Documentation
https://www.elastic.co/guide/en/elasticsearch/reference/current/elasticsearch-intro.html
- What is Elasticsearch?
- Set up Elasticsearch
- Upgrade Elasticsearch
- Index modules
- Mapping
- Text analysis
- Index templates
- Data streams
- Ingest pipelines
- Aliases
- Search your data
- Query DSL
- Aggregations
- EQL
- SQL
- Scripting
- Data management
- Autoscaling
- Monitor a cluster
- Roll up or transform your data
- Set up a cluster for high availability
- Snapshot and restore
- Secure the Elastic Stack
- Watcher
- Command line tools
- How to
- Troubleshooting
- REST APIs
- Migration guide
What is Elasticsearch?
Elasticsearch is the distributed search and analytics engine at the heart of the Elastic Stack. Logstash and Beats facilitate collecting, aggregating, and enriching your data and storing it in Elasticsearch
Elasticsearch provides near real-time search and analytics for all types of data. Whether you have structured or unstructured text, numerical data, or geospatial data, Elasticsearch can efficiently store and index it in a way that supports fast searches. And as your data and query volume grows, the distributed nature of Elasticsearch enables your deployment to grow seamlessly right along with it
Data in: documents and indices
Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents
Elasticsearch uses a data structure called an inverted index that supports very fast full-text searches (Apache Lucene)
Есть 2 типа индексов – прямой и обратный. Прямой – сопоставление документу списка слов в нем встреченного. Обратный – слову сопоставляется список документов, в которых оно есть
Elasticsearch also has the ability to be schema-less, which means that documents can be indexed without explicitly specifying how to handle each of the different fields that might occur in a document. When dynamic mapping is enabled, Elasticsearch automatically detects and adds new fields to the index
Defining your own mappings enables you to:
- Distinguish between full-text string fields and exact value string fields
- Perform language-specific text analysis
- Optimize fields for partial matching
- Use custom date formats
- Use data types such as geo_point and geo_shape that cannot be automatically detected
Information out: search and analyze
While you can use Elasticsearch as a document store and retrieve documents and their metadata, the real power comes from being able to easily access the full suite of search capabilities built on the Apache Lucene search engine library
Elasticsearch provides a simple, coherent REST API for managing your cluster and indexing and searching your data. For testing purposes, you can easily submit requests directly from the command line or through the Developer Console in Kibana
The Elasticsearch REST APIs support structured queries, full text queries, and complex queries that combine the two. Structured queries are similar to the types of queries you can construct in SQL. For example, you could search the gender and age fields in your employee index and sort the matches by the hire_date field. Full-text queries find all documents that match the query string and return them sorted by relevance—how good a match they are for your search terms
You can access all of these search capabilities using Elasticsearch’s comprehensive JSON-style query language (Query DSL). You can also construct SQL-style queries to search and aggregate data natively inside Elasticsearch, and JDBC and ODBC drivers enable a broad range of third-party applications to interact with Elasticsearch via SQL
Scalability and resilience
Elasticsearch is built to be always available and to scale with your needs. It does this by being distributed by nature. You can add servers (nodes) to a cluster to increase capacity and Elasticsearch automatically distributes your data and query load across all of the available nodes
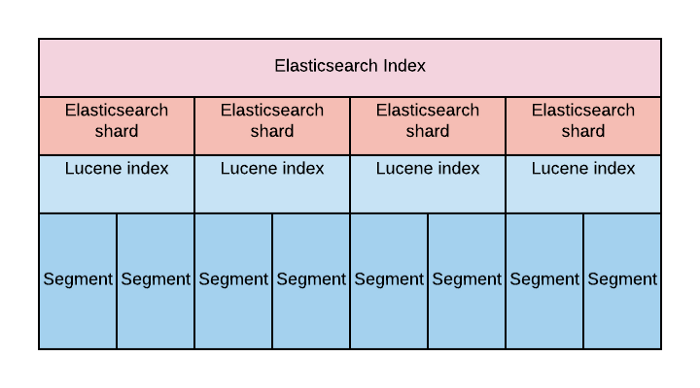
Under the covers, an Elasticsearch index is really just a logical grouping of one or more physical shards, where each shard is actually a self-contained index
By distributing the documents in an index across multiple shards, and distributing those shards across multiple nodes, Elasticsearch can ensure redundancy, which both protects against hardware failures and increases query capacity as nodes are added to a cluster. As the cluster grows (or shrinks), Elasticsearch automatically migrates shards to rebalance the cluster
There are two types of shards: primaries and replicas. Each document in an index belongs to one primary shard. A replica shard is a copy of a primary shard
The number of primary shards in an index is fixed at the time that an index is created, but the number of replica shards can be changed at any time, without interrupting indexing or query operations
There are a number of performance considerations and trade offs with respect to shard size and the number of primary shards configured for an index:
- The more shards, the more overhead there is simply in maintaining those indices. The larger the shard size, the longer it takes to move shards around when Elasticsearch needs to rebalance a cluster
- Querying lots of small shards makes the processing per shard faster, but more queries means more overhead, so querying a smaller number of larger shards might be faster
As a starting point:
- Aim to keep the average shard size between a few GB and a few tens of GB. For use cases with time-based data, it is common to see shards in the 20GB to 40GB range
- Avoid the gazillion shards problem. The number of shards a node can hold is proportional to the available heap space. As a general rule, the number of shards per GB of heap space should be less than 20
In the event of a major outage in one location, servers in another location need to be able to take over. The answer? Cross-cluster replication (CCR)
CCR provides a way to automatically synchronize indices from your primary cluster to a secondary remote cluster that can serve as a hot backup. If the primary cluster fails, the secondary cluster can take over. You can also use CCR to create secondary clusters to serve read requests in geo-proximity to your users
Indices replicated to secondary clusters are read-only
Set up Elasticsearch
To use your own version of Java, set the ES_JAVA_HOME environment variable
Installing Elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/current/deb.html
The Debian package for Elasticsearch can be downloaded from our website or from our APT repository
This package contains both free and subscription features
In the documentation uses elastic's cdn which blocks russia's IPs
This is cause of using yandex's mirror -deb [trusted=yes] https://mirror.yandex.ru/mirrors/elastic/8/ stable main
For installation - apt install elasticsearch
When installing Elasticsearch, security features are enabled and configured by default:
- Authentication and authorization are enabled, and a password is generated for the elastic built-in superuser
- Certificates and keys for TLS are generated for the transport and HTTP layer, and TLS is enabled and configured with these keys and certificates
Installation notes:
--------------------------- Security autoconfiguration information ------------------------------
Authentication and authorization are enabled.
TLS for the transport and HTTP layers is enabled and configured.
The generated password for the elastic built-in superuser is : CzwQ+iDSMoO73+fR0C09
If this node should join an existing cluster, you can reconfigure this with
'/usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token <token-here>'
after creating an enrollment token on your existing cluster.
You can complete the following actions at any time:
Reset the password of the elastic built-in superuser with
'/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic'.
Generate an enrollment token for Kibana instances with
'/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana'.
Generate an enrollment token for Elasticsearch nodes with
'/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node'.
-------------------------------------------------------------------------------------------------
### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
### You can start elasticsearch service by executing
sudo systemctl start elasticsearch.service
You can add /usr/share/elasticsearch/bin to PATH variable for easyly use elastic's binaries
Use systemctl start elasticsearch.service for run it
Deb package contains the files listed below:
root@es-1:~# ar x elasticsearch_8.1.1_amd64.deb
root@es-1:~# tar --list -f data.tar.gz | egrep -v '/usr/share/elasticsearch/jdk/.+|/usr/share/elasticsearch/modules/.+|/usr/share/elasticsearch/lib/.+'
./usr/
./usr/share/
./usr/share/elasticsearch/
./usr/share/elasticsearch/bin/
./usr/share/elasticsearch/bin/elasticsearch-keystore
./usr/share/elasticsearch/bin/elasticsearch-shard
./usr/share/elasticsearch/bin/elasticsearch-geoip
./usr/share/elasticsearch/bin/elasticsearch-node
./usr/share/elasticsearch/bin/elasticsearch-env-from-file
./usr/share/elasticsearch/bin/elasticsearch
./usr/share/elasticsearch/bin/elasticsearch-cli
./usr/share/elasticsearch/bin/elasticsearch-env
./usr/share/elasticsearch/bin/elasticsearch-plugin
./usr/share/elasticsearch/bin/elasticsearch-sql-cli
./usr/share/elasticsearch/bin/elasticsearch-croneval
./usr/share/elasticsearch/bin/elasticsearch-setup-passwords
./usr/share/elasticsearch/bin/elasticsearch-syskeygen
./usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token
./usr/share/elasticsearch/bin/elasticsearch-certgen
./usr/share/elasticsearch/bin/x-pack-watcher-env
./usr/share/elasticsearch/bin/elasticsearch-sql-cli-8.1.1.jar
./usr/share/elasticsearch/bin/x-pack-security-env
./usr/share/elasticsearch/bin/x-pack-env
./usr/share/elasticsearch/bin/elasticsearch-service-tokens
./usr/share/elasticsearch/bin/elasticsearch-users
./usr/share/elasticsearch/bin/elasticsearch-certutil
./usr/share/elasticsearch/bin/elasticsearch-saml-metadata
./usr/share/elasticsearch/bin/elasticsearch-reconfigure-node
./usr/share/elasticsearch/bin/elasticsearch-reset-password
./usr/share/elasticsearch/README.asciidoc
./usr/share/elasticsearch/lib/
./usr/share/elasticsearch/modules/
./usr/share/elasticsearch/jdk/
./usr/share/doc/
./usr/share/doc/elasticsearch/
./usr/share/doc/elasticsearch/copyright
./etc/
./etc/elasticsearch/
./etc/elasticsearch/role_mapping.yml
./etc/elasticsearch/log4j2.properties
./etc/elasticsearch/roles.yml
./etc/elasticsearch/users
./etc/elasticsearch/jvm.options
./etc/elasticsearch/elasticsearch.yml
./etc/elasticsearch/users_roles
./etc/elasticsearch/elasticsearch-plugins.example.yml
./etc/default/
./etc/default/elasticsearch
./usr/lib/
./usr/lib/tmpfiles.d/
./usr/lib/tmpfiles.d/elasticsearch.conf
./usr/lib/systemd/
./usr/lib/systemd/system/
./usr/lib/systemd/system/elasticsearch.service
./usr/lib/sysctl.d/
./usr/lib/sysctl.d/elasticsearch.conf
./usr/share/elasticsearch/bin/systemd-entrypoint
./usr/share/elasticsearch/NOTICE.txt
./usr/share/lintian/
./usr/share/lintian/overrides/
./usr/share/lintian/overrides/elasticsearch
./usr/share/elasticsearch/plugins/
./etc/elasticsearch/jvm.options.d/
./var/
./var/log/
./var/log/elasticsearch/
./var/lib/
./var/lib/elasticsearch/
When you reconfigure your node to connect to existing cluster existing configuration will be rewriten:
root@es-3:~# /usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token eyJ2ZXIiOiI4LjEuMSIsImFkciI6WyIxMC4xMjguMC4yNjo5MjA3Il0sImZnciI6ImZhOWQ1ZTY0MzgzN2Q0YzQwMGUzNGMxYmFmMWNhNTQyYzZkZTc1MDRhYjNkMTJjZDU3MjdmZDQ2OTRkMjUxMGIiLCJrZXkiOiJjX1p6WUlZQlp4N0lEbzFkVm9lWjpPT3JxZnZ2c1FIdXM4a1Jzb3gtOEJ3In0=
This node will be reconfigured to join an existing cluster, using the enrollment token that you provided.
This operation will overwrite the existing configuration. Specifically:
- Security auto configuration will be removed from elasticsearch.yml
- The [certs] config directory will be removed
- Security auto configuration related secure settings will be removed from the elasticsearch.keystore
Do you want to continue with the reconfiguration process [y/N]y
root@es-3:~#
Enrollment token can be generated with /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node command
Elasticsearch will not be started before connecting to cluster (data dir must be empty -
/var/lib/elasticsearch)
Commands systemctl start/stop elasticsearch.service provide no feedback about successfulness of start
So, you need to see in a log files in /var/log/elasticsearch directory
By default, Elasticsearch is configured to allow automatic index creation, and no additional steps are required
You can change it behaviour with action.auto_create_index option in elasticsearch.yml
To enable journalctl logging, the --quiet option must be removed from the ExecStart command line in the elasticsearch.service file
You can test that your Elasticsearch node is running by sending an HTTPS request to port 9200 on localhost:
root@es-1:~# curl --cacert /etc/elasticsearch/certs/http_ca.crt -u elastic https://localhost:9207
Enter host password for user 'elastic':
{
"name" : "es-1",
"cluster_name" : "logs",
"cluster_uuid" : "kjc6gBJXT4eyigyTxmEO4Q",
"version" : {
"number" : "8.1.1",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "d0925dd6f22e07b935750420a3155db6e5c58381",
"build_date" : "2022-03-17T22:01:32.658689558Z",
"build_snapshot" : false,
"lucene_version" : "9.0.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
The /etc/elasticsearch directory contains the default runtime configuration for Elasticsearch
Owner is root:elasticsearch, this set on package installation
The setgid flag applies group permissions on the /etc/elasticsearch directory to ensure that Elasticsearch can read any contained files and subdirectories
By default Elasticsearch load configuration from /etc/elasticsearch/elasticsearch.yml (not .yaml, only .yml)
Deb distros also has /etc/default/elasticsearch file with ENVs like - ES_JAVA_HOME, ES_PATH_CONF, ES_JAVA_OPTS, RESTART_ON_UPGRADE
Autogenerated CA cert for TLS is stored at /etc/elasticsearch/certs/http_ca.crt
This is self-signed certificate, and clients must validate that they trust the certificate that Elasticsearch uses for HTTPS
Directory layout (deb) - https://www.elastic.co/guide/en/elasticsearch/reference/current/deb.html#deb-layout
Certificates and keys are generated in the Elasticsearch configuration directory, which are used to connect a Kibana instance to your secured Elasticsearch cluster and to encrypt internode communication:
- http_ca.crt - The CA certificate that is used to sign the certificates for the HTTP layer of this Elasticsearch cluster.
- http.p12 - Keystore that contains the key and certificate for the HTTP layer for this node.
- transport.p12 - Keystore that contains the key and certificate for the transport layer for all the nodes in your cluster.
http.p12 and transport.p12 are password-protected PKCS#12 keystores. Elasticsearch stores the passwords for these keystores as secure settings. To retrieve the passwords so that you can inspect or change the keystore contents, use the bin/elasticsearch-keystor tool
Use the following command to retrieve the password for http.p12:
elasticsearch-keystore show xpack.security.http.ssl.keystore.secure_password
Use the following command to retrieve the password for transport.p12:
elasticsearch-keystore show xpack.security.transport.ssl.keystore.secure_password
Run Elasticsearch locally
You send data and other requests to Elasticsearch through REST APIs. You can interact with Elasticsearch using any client that sends HTTP requests, such as the Elasticsearch language clients and curl. Kibana’s developer console provides an easy way to experiment and test requests. To access the console, go to Management > Dev Tools
About index - https://www.youtube.com/watch?v=P35CTWgEpS0
Shard is Lucene instance
You index data into Elasticsearch by sending JSON objects (documents) through the REST APIs
To add a single document to an index, submit an HTTP post request that targets the index
root@es-1:~# curl -X POST -k -u elastic:CzwQ+iDSMoO73+fR0C09 "https://localhost:9200/customer/_doc?pretty" -H 'Content-Type: application/json' -d "{\"date\": \"$(date)\",\"log\": \"$(tail -n 1 /var/log/elasticsearch/logs.log)\", \"data\":\"$(head /dev/urandom | tr -dc a-z1-4 | tr 1-2 ' \n' | awk 'length==0 || length>50' | tr 3-4 ' ' | sed 's/^ *//' | head -n 1)\"}"
{
"_index" : "customer",
"_id" : "ZWKtZoYB_RTAJ3CjCp7R",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 41662,
"_primary_term" : 2
}
This request automatically creates the customer index if it doesn’t exist, adds a new document that has an auto generated ID, and stores and indexes the date, log and data fields
Also you can insert new doc with specified ID
POST /customer/_doc/1
{
"firstname": "Jennifer",
"lastname": "Walters"
}
The new document is available immediately from any node in the cluster
asticsearch/logs.log)\", \"data\":\"$(head /dev/urandom | tr -dc a-z1-4 | tr 1-2 ' \n' | awk 'length==0 || length>50' | tr 3-4 ' ' | sed 's/^ *//' | head -n 1)\"}"
root@es-1:~# curl -X POST -k -u elastic:CzwQ+iDSMoO73+fR0C09 "https://localhost:9200/test/_doc?pretty" -H 'Content-Type: application/json' -d '{"name": "Ivan", "age": 24}'
{
"_index" : "test",
"_id" : "43rMZoYBBYmCfWCjVvEr",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
root@es-1:~# curl -X GET -k -u elastic:CzwQ+iDSMoO73+fR0C09 "https://localhost:9200/test/_doc/43rMZoYBBYmCfWCjVvEr?pretty"
{
"_index" : "test",
"_id" : "43rMZoYBBYmCfWCjVvEr",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Ivan",
"age" : 24
}
}
To add multiple documents in one request, use the _bulk API
root@es-1:~# curl -X POST -k -u elastic:CzwQ+iDSMoO73+fR0C09 "https://localhost:9200/test/_bulk?pretty" -H 'Content-Type: application/json' -d '
{ "create": { } }
> {"name": "Ivan", "age": 24}
> { "create": { } }
> {"name": "Test", "age": "12345"}
> '
{
"took" : 38,
"errors" : false,
"items" : [
{
"create" : {
"_index" : "test",
"_id" : "5nrRZoYBBYmCfWCjffFg",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"create" : {
"_index" : "test",
"_id" : "53rRZoYBBYmCfWCjffFg",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
}
]
}
For search use _search endpoint
root@es-1:~# curl -X GET -k -u elastic:CzwQ+iDSMoO73+fR0C09 "https://localhost:9200/customer/_search?pretty" -H 'Content-Type: application/json' -d '
{"query": {"match": {"data": "ry m kbkuky czedcynkmqhnhrxjeqih tvkwcrabhkjiyvyvwt"}}}
'
{
"took" : 216,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1008,
"relation" : "eq"
},
"max_score" : 46.97039,
"hits" : [
{
"_index" : "customer",
"_id" : "AmJyZoYB_RTAJ3CjXUEV",
"_score" : 46.97039,
"_source" : {
"date" : "Sat 18 Feb 2023 09:33:36 PM UTC",
"log" : "[2023-02-18T20:24:30,309][INFO ][o.e.i.g.DatabaseNodeService] [es-1] successfully loaded geoip database file [GeoLite2-City.mmdb]",
"data" : "ry m kbkuky czedcynkmqhnhrxjeqih tvkwcrabhkjiyvyvwt "
}
},
{
"_index" : "customer",
"_id" : "KmKBZoYB_RTAJ3CjgFnD",
"_score" : 8.853238,
"_source" : {
"date" : "Sat 18 Feb 2023 09:50:08 PM UTC",
"log" : "[2023-02-18T20:24:30,309][INFO ][o.e.i.g.DatabaseNodeService] [es-1] successfully loaded geoip database file [GeoLite2-City.mmdb]",
"data" : "pnpseh quzqcnwmhtmycg ccgtnerz oj ry m bvmtvpouocrdnd kpj mm epjzt ikwuu"
}
},
...
To get started with Kibana, create a data view that connects to one or more Elasticsearch indices, data streams, or index aliases.
- Go to Management > Stack Management > Kibana > Data Views
- Select Create data view
- Enter a name for the data view and a pattern that matches one or more indices, such as customer
- Select Save data view to Kibana
To start exploring, go to Analytics > Discover
Configuring Elasticsearch
Elasticsearch ships with good defaults and requires very little configuration. Most settings can be changed on a running cluster using the Cluster update settings API
Elasticsearch has three configuration files:
elasticsearch.yml- for configuring Elasticsearchjvm.options- for configuring Elasticsearch JVM settingslog4j2.properties- for configuring Elasticsearch logging
Config file format is YAML, and can be defined as follows:
path:
data: /var/lib/elasticsearch
logs: /var/log/elasticsearch
And also as follows:
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
Environment variables referenced with the ${...} notation within the configuration file will be replaced with the value of the environment variable. For example:
node.name: ${HOSTNAME}
network.host: ${ES_NETWORK_HOST}
Updates made using the cluster update settings API can be persistent, which apply across cluster restarts, or transient, which reset after a cluster restart
If you configure the same setting using multiple methods, Elasticsearch applies the settings in following order of precedence:
- Transient setting
- Persistent setting
elasticsearch.ymlsetting- Default setting value
If you run Elasticsearch on your own hardware, use the cluster update settings API to configure dynamic cluster settings. Only use
elasticsearch.ymlfor static cluster settings and node settings. The API doesn’t require a restart and ensures a setting’s value is the same on all nodes
Important Elasticsearch configuration
Number of items which must be considered before using your cluster in production:
Path settings
Elasticsearch writes the data you index to indices and data streams to a data directory. Elasticsearch writes its own application logs, which contain information about cluster health and operations, to a logs directory
Set it in elasticsearch.yml:
path:
data: /var/data/elasticsearch
logs: /var/log/elasticsearch
- Don’t modify anything within the data directory or run processes that might interfere with its contents
- Don’t attempt to take filesystem backups of the data directory; there is no supported way to restore such a backup - Instead, use Snapshot and restore to take backups safely
- Don’t run virus scanners on the data directory - The data directory contains no executables so a virus scan will only find false positives
Multiple data paths
Deprecated in 7.13.0
Cluster name setting
A node can only join a cluster when it shares its cluster.name with all the other nodes in the cluster
cluster:
name: logging-prod
Do not reuse the same cluster names in different environments. Otherwise, nodes might join the wrong cluster
Node name setting
Elasticsearch uses node.name as a human-readable identifier for a particular instance of Elasticsearch. The node name defaults to the hostname of the machine when Elasticsearch starts, but can be configured explicitly in elasticsearch.yml:
node:
name: prod-data-2
Network host setting
By default, Elasticsearch only binds to loopback addresses such as 127.0.0.1 and [::1]. This is good for testing and development. But for production you need to configure network.host setting:
network:
host: 192.168.1.10
When you provide a value for
network.host, Elasticsearch assumes that you are moving from development mode to production mode, and upgrades a number of system startup checks from warnings to exceptions
Discovery and cluster formation settings
discovery.seed_hosts- provides a list of other nodes in the cluster that are master-eligible and likely to be live and contactable to seed the discovery process (If a hostname resolves to multiple IP addresses, the node will attempt to discover other nodes at all resolved addresses)cluster.initial_master_nodes- Because auto-bootstrapping is inherently unsafe, when starting a new cluster in production mode, you must explicitly list the master-eligible nodes whose votes should be counted in the very first election. You set this list using this settingAfter the cluster forms successfully for the first time, remove the
cluster.initial_master_nodessetting from each node’s configuration. Do not use this setting when restarting a cluster or adding a new node to an existing cluster
Identify the initial master nodes by theirnode.name, which defaults to their hostname
Heap size settings
We recommend the default sizing for most production environments
JVM heap dump path setting
By default, Elasticsearch configures the JVM to dump the heap on out of memory exceptions to the data directory - /var/lib/elasticsearch
If this path is not suitable for receiving heap dumps, modify the -XX:HeapDumpPath=... entry in jvm.options
GC logging settings
By default, Elasticsearch enables garbage collection (GC) logs. These are configured in jvm.options and output to the same default location as the Elasticsearch logs. The default configuration rotates the logs every 64 MB and can consume up to 2 GB of disk space
Configure this in jvm.options.d/gc.options:
# Turn off all previous logging configuratons
-Xlog:disable
# Default settings from JEP 158, but with `utctime` instead of `uptime` to match the next line
-Xlog:all=warning:stderr:utctime,level,tags
# Enable GC logging to a custom location with a variety of options
-Xlog:gc*,gc+age=trace,safepoint:file=/opt/my-app/gc.log:utctime,pid,tags:filecount=32,filesize=64m
Temporary directory settings
By default, Elasticsearch uses a private temporary directory that the startup script creates immediately below the system temporary directory
On some Linux distributions, a system utility will clean files and directories from /tmp if they have not been recently accessed. Removing the private temporary directory causes problems if a feature that requires this directory is subsequently used
If you install Elasticsearch using the .deb or .rpm packages and run it under systemd, the private temporary directory that Elasticsearch uses is excluded from periodic cleanup - via PrivateTmp=true option in the systemd service
JVM fatal error log setting
By default, Elasticsearch configures the JVM to write fatal error logs to the default logging directory. On RPM and Debian packages, this directory is /var/log/elasticsearch
You can change it with -XX:ErrorFile=... entry in jvm.options
Cluster backups
In a disaster, snapshots can prevent permanent data loss. Snapshot lifecycle management is the easiest way to take regular backups of your cluster
Secure settings
Some settings are sensitive, and relying on filesystem permissions to protect their values is not sufficient
For this use case, Elasticsearch provides a keystore and the elasticsearch-keystore tool to manage the settings in the keystore
Only some settings are designed to be read from the keystore. To see whether a setting is supported in the keystore, look for a "Secure" qualifier the setting reference
All the modifications to the keystore take effect only after restarting Elasticsearch
Re-reading settings requires a node restart, but certain secure settings are marked as reloadable
Auditing settings
Audit logs are only available on certain subscription levels. For more information, see https://www.elastic.co/subscriptions
If some XPack functions is enabled, then you will have WARNs in logs
[2023-02-19T15:34:52,799][WARN ][o.e.x.s.a.AuditTrailService] [es-1] Auditing logging is DISABLED because the currently active license [BASIC] does not permit it
Circuit breaker settings
https://www.elastic.co/guide/en/elasticsearch/reference/current/circuit-breaker.html#circuit-breaker
Cluster-level shard allocation and routing settings
Shard allocation is the process of allocating shards to nodes. This can happen during initial recovery, replica allocation, rebalancing, or when nodes are added or removed
Node with role Master controls which shards to allocate to which nodes
A cluster is balanced when it has an equal number of shards on each node, with all nodes needing equal resources, without having a concentration of shards from any index on any node. Elasticsearch runs an automatic process called rebalancing which moves shards between the nodes in your cluster to improve its balance
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-cluster.html#modules-cluster
Miscellaneous cluster settings
Cross-cluster replication settings
https://www.elastic.co/guide/en/elasticsearch/reference/current/ccr-settings.html
Discovery and cluster formation
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery-settings.html
Field data cache settings
The field data cache contains field data and global ordinals, which are both used to support aggregations on certain field types. Since these are on-heap data structures, it is important to monitor the cache’s use
The entries in the cache are expensive to build, so the default behavior is to keep the cache loaded in memory. The default cache size is unlimited, causing the cache to grow until it reaches the limit set by the field data circuit breaker. This behavior can be configured
Health diagnostic settings in Elasticsearch
This chapter contain the expert-level settings available for configuring an internal diagnostics service
https://www.elastic.co/guide/en/elasticsearch/reference/current/health-diagnostic-settings.html
Index lifecycle management settings in Elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/current/ilm-settings.html
Index management settings
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-management-settings.html
Index recovery settings
Peer recovery syncs data from a primary shard to a new or existing shard copy
Peer recovery automatically occurs when Elasticsearch:
- Recreates a shard lost during node failure
- Relocates a shard to another node due to a cluster rebalance or changes to the shard allocation settings
https://www.elastic.co/guide/en/elasticsearch/reference/current/recovery.html
Indexing buffer settings
The indexing buffer is used to store newly indexed documents. When it fills up, the documents in the buffer are written to a segment on disk
https://www.elastic.co/guide/en/elasticsearch/reference/current/indexing-buffer.html