K8S
- Documentation
- Base
- Как подключаться к K8S и самые популярные команды
- Kubernetes for DEVOPS
- 3. Размещение Kubernetes
- 4. Работа с объектами Kubernetes
- 5. Управление ресурсами
- 6. Работа с кластерами
- 7. Продвинутые инструменты для работы с Kubernetes
- 8. Работа с контейнерами
- cgroups
Documentation
Что-то из доки
Getting started
Production environment
Обычно продовый куб имеет гораздо больше требований чем тестовый или разработческий. Например такие как безопасный доступ для множества пользователей, постоянная доступность и ресурсы для возможности адаптироваться к изменению требований
На требования к кластеру влияют такие проблемы:
- Доступность. Одиночная машина это единая точка отказа. Создание высокодоступного кластера подразумевает:
- Разделение control plane от worker nodes
- Реплицирование компонентов control plane на множество узлов
- Распределение трафика по API Server'ам кластера
- Наличие достаточного количества доступных worker node, или возможность быстро получить их (в соответствии с требованиями изменяющейся нагрузки)
- Масштабируемость. Если ты ожидаешь что твой куб будет получать стабильную нагрузку, то можешь засетапить его один раз и забыть. Однако если ты ожидаешь рост нагрузки со временем, или изменение нагрузки в связи с сезонностью или другими особыми событиями, то тебе нужно спланировать как масштабировать контрол плейн и дата плейн (и как масштабировать это все вниз чтобы высвобождать ненужные ресурсы (которые были нужны в моменте))
- Безопасность и управление доступом. В учебном кластере ты имеешь полные админские права, но разделяемые кластеры с важной нагрузкой требуют более изысканных подходов к управлению доступом к ресурсам кластера. Ты можешь использовать RBAC и другие механизмы безопасности для обеспечения безопасного доступа к необходимым ресурсам
Чтобы собрать надежный и чинибельный кластер:
- Выбери инструменты деплоя. Есть kubeadm, kops, kubespray и другие, выбери подходящий тебе
- Управляй сертификатами. Безопасная коммуникация между компонентами control plane достигается за счет сертификатов. Сертификаты автоматически генерятся при деплое или ты можешь использовать свой собственный CA
- Настрой балансировщик нагрузки для API Server'ов. Чтобы распределять API запросы на экземпляры API Server'ов запущенных на разных узлах
- Разделяй и бэкапь ETCD. Можно запустить ETCD на тех же машинах что и control plane, а можно унести его на отдельные машины (для дополнительной безопасности и надежности). Поскольку в ETCD хранится полная конфигурация кластера, то он должен бэкапиться регулярно и ты должен мочь восстановить этот бэкап при необходимости (нерабочие бэкапы никому не нужны)
- Делай множественный control plane. Для высокой доступности control plane не должен быть ограничен одной машиной. Если сервисы control plane'a запускаются через систему инициализации (например systemd), то каждый сервис должен запускаться минимум на трех машинах. С другой стороны если запускать компоненты control plane'a как поды, то куб сам постарается сделать так чтобы было доступно необходимое количество экземпляров сервисов
- Охватывай несколько зон. Если сильно критична высокая доступность кластера, то делай кластер который работает в нескольких зонах доступности сразу (или в нескольких датацентрах сразу). Запуская кластер в нескольких зонах, ты повышаешь шанс на то, что, даже при выходе из строя целого датацентра, твой кластер продолжит работать
- Управление приходящими фичами. Если ты планируешь поддерживать свой кластер рабочим долгое время, то нужно быть готовым его обслуживать, обновлять, управлять сертификатами и безопасностью
Продовый кластер должен быть масштабируемым и все на что он полагается тоже должно быть масштабируемым (например CoreDNS)
Установи лимиты на ресурсы. Есть лимиты на уровне неймспейсов и всего кластера
Если ты готовишься к большому скейлингу, то твой dns сервер должен быть готов обслуживать такое количество имен и запросов
Container Runtimes
Нужно установить container runtime на все узлы где должны запускаться поды
Kubernetes 1.30 требует использования такого рантайма, который будет работать по Container Runtime Interface (CRI)
Вот тут есть подробности про доступные рантаймы https://github.com/kubernetes/community/blob/master/contributors/devel/sig-node/container-runtime-interface.md
Если кратко:
CRI был создан потому что было очень сложно подключать к кубу какие-либо необычные рантаймы
Для этого нужно было сильно шарить за кублет (именно за его внутренности) и закоммитить поддержку своего рантайма в основную репу куба
Это немасштабируемый способ. А куб преследует расширяемость
Поэтому сделали CRI, это понятная спецификация поддержав которую своим рантаймом ты автоматически делаешь его доступным для использования с кубом
До версии 1.24 Kubernetes имел прямую интеграцию с Docker Engine (dockershim). Теперь ее нет
По умолчанию Linux kernel не позволяет роутить IPv4 пакеты между интерфейсами. Многие сетевые драйверы делают такую настройку сами, но некоторые полагаются на то что системный администратор сделает это за них
Чтобы включить это вручную сделай:
# sysctl params required by setup, params persist across reboots
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
EOF
# Apply sysctl params without reboot
sudo sysctl --system
Проверь что net.ipv4.ip_forward возвращает 1
sysctl net.ipv4.ip_forward
Base
Как подключаться к K8S и самые популярные команды
Как подключиться
Основная утилита для работы с k8s - это kubectl
Как установить kubectl:
Очень полезно настроить автодополнение для kubectl, потому что команды у kubectl бывают длинными и сложными, а автодополнение позволит ускориться и меньше ошибаться
Чтобы kubectl мог найти и получить доступ к кластеру Kubernetes, нужен файл kubeconfig
По умолчанию конфигурация kubectl находится в ~/.kube/config
Команда kubectl cluster-info позволит проверить корректно ли сконфигурирован kubectl (если все хорошо, то она выведет информацию о кластере, а если есть проблемы, то выведет сообщение о проблеме)
Kubeconfig'ом пользуются разные утилиты:
Для работы со всеми этими инструментами достаточно иметь корректный kubeconfig, они просто прочитают его и сразу (без дополнительных манипуляций) позволят работать
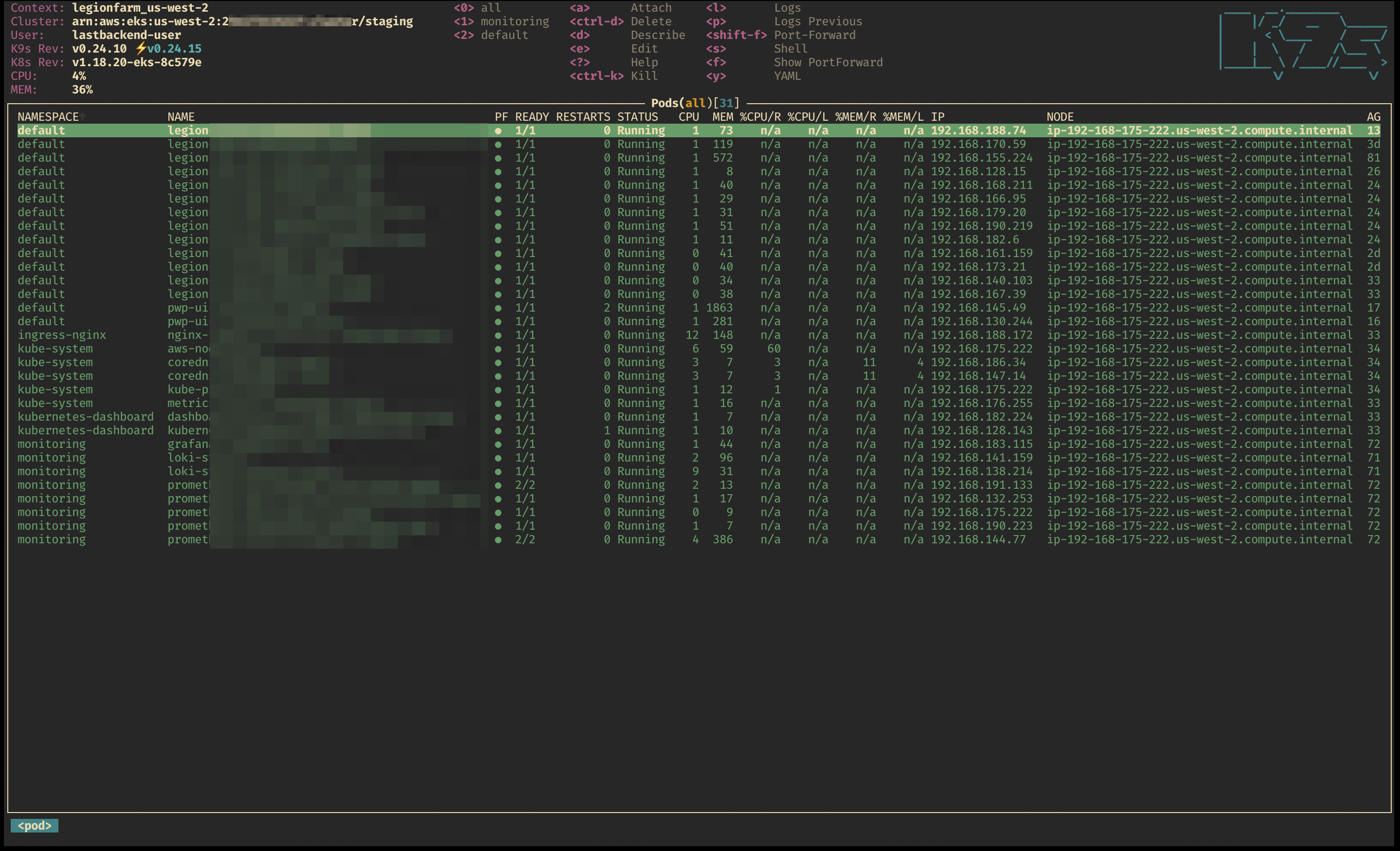
k9s
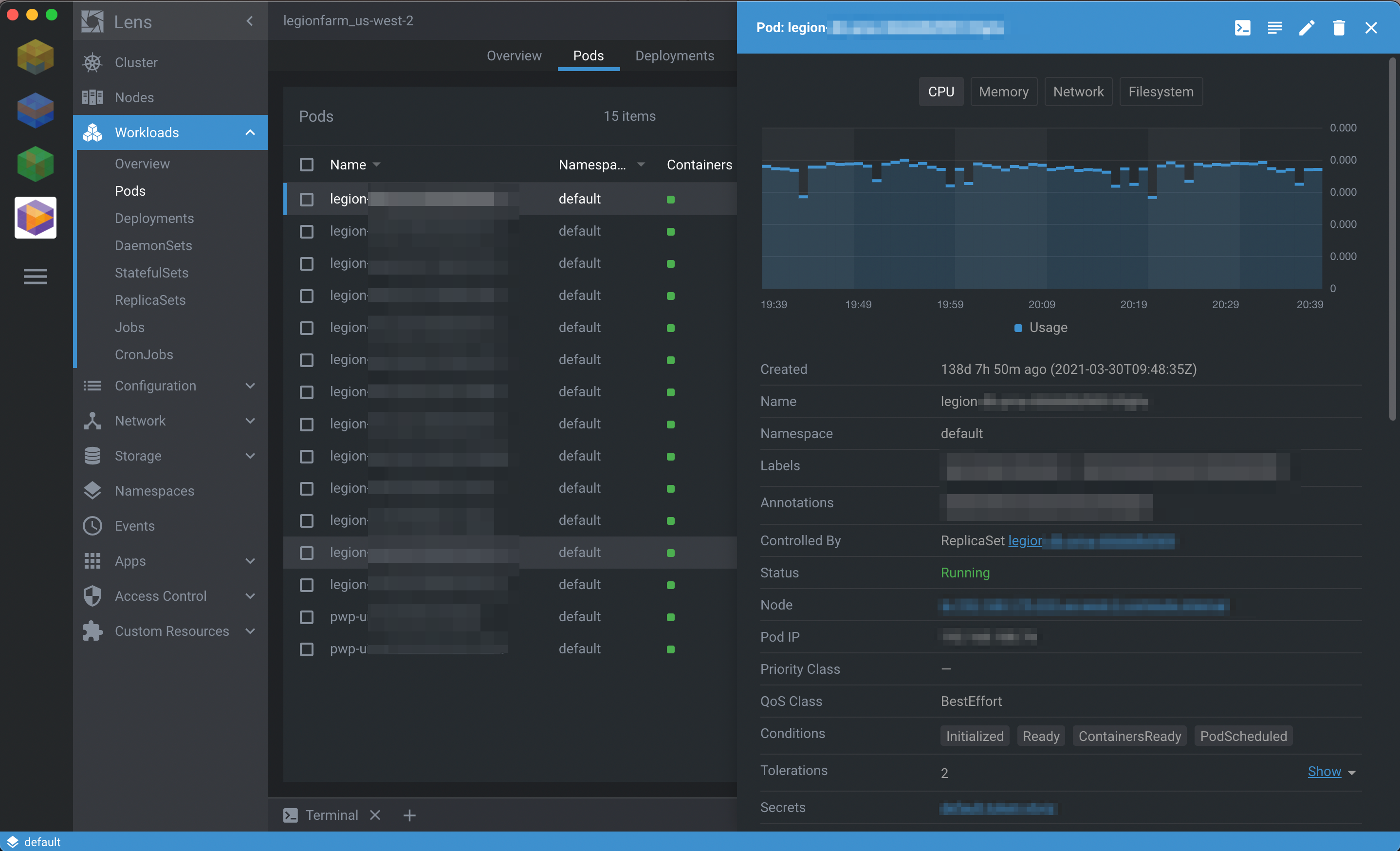
lens
kubeconfig
Структура
Kubeconfig состоит из нескольких составных частей которые объединяются в контексты

С помощью группы команд kubectl config можно управлять содержимым kubeconfig'a
$ kubectl config <TAB>
current-context delete-context get-clusters get-users set set-context unset view
delete-cluster delete-user get-contexts rename-context set-cluster set-credentials use-context
Подробнее тут: https://kubernetes.io/docs/tasks/access-application-cluster/configure-access-multiple-clusters/
Где взять
Если кластер в Амазоне, то проще всего сделать это через aws-cli:
- Настроить aws-cli:
Сконфигурировать
Проверить$ aws configure AWS Access Key ID [None]: <secret> AWS Secret Access Key [None]: <secret> Default region name [None]: eu-west-3 Default output format [None]: json$ aws sts get-caller-identity { "UserId": "<secret>", "Account": "<secret>", "Arn": "arn:aws:iam::<secret>:user/k8s-user" } - Обновить kubeconfig
$ aws eks --region eu-west-3 update-kubeconfig --name education-eks-RhxcE48z Added new context arn:aws:eks:eu-west-3:<secret>:cluster/education-eks-RhxcE48z to /Users/vandud/.kube/config
Если не удается, то kubeconfig можно запросить у команды devops
Основные команды
kubectl
config
Показать контексты
$ k config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
arn:aws:eks:eu-west-3:<secret>:cluster/education-eks-RhxcE48z arn:aws:eks:eu-west-3:<secret>:cluster/education-eks-RhxcE48z arn:aws:eks:eu-west-3:<secret>:cluster/education-eks-RhxcE48z
* docker-desktop docker-desktop docker-desktop
legionfarm-with-vpn_us-east-2 arn:aws:eks:us-east-2:<secret>:cluster/legion-eks aws:cluster/legion-eks
legionfarm_us-west-2 arn:aws:eks:us-west-2:<secret>:cluster/staging lastbackend-user
Переключить контекст
kubectl config use-context CONTEXT-NAME
Также можно воспользоваться командой kubectx (устанавливается отдельно)
$ kubectx legionfarm_us-west-2
Switched to context "legionfarm_us-west-2".
$ kubectx
arn:aws:eks:eu-west-3:<secret>:cluster/education-eks-RhxcE48z
docker-desktop
legionfarm-with-vpn_us-east-2
legionfarm_us-west-2
В ее выводе текущий контекст выделен цветом
Вместе с kubectx устанавливается kubens
Работает аналогично, но переключает не контексты, а неймспейсы (namespace - логический подкластер)
$ kubens monitoring
Context "legionfarm_us-west-2" modified.
Active namespace is "monitoring".
apply/create
apply - одна из самых частых команд, она применит к кластеру указанный манифест
kubectl apply -f ./manifest.yaml
Можно указать папку с манифестами, тогда применятся все манифесты из папки
kubectl apply -f ./dir
Команда create просто создает какой-либо ресурс, а apply создает если еще не создано, и обновит уже существующее
explain
Очень полезная и удобная команда
Предоставляет документацию по ресурсам
$ kubectl explain pods
$ kubectl explain pods.spec
$ kubectl explain pods.spec.tolerations
$ kubectl explain pods.spec.tolerations.effect
Каждая из этих команд выведет на экран соответствующую документацию
get
kubectl get тоже частая команда, она позволяет вывести список ресурсов определенного типа
Например посмотрим поды из неймспейса logging
$ kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
loki-0 1/1 Running 0 44d
loki-promtail-68dpk 1/1 Running 0 18d
loki-promtail-9ldn7 1/1 Running 0 41d
loki-promtail-c6lm8 1/1 Running 0 41d
loki-promtail-ckwc5 1/1 Running 0 45d
loki-promtail-fzltl 1/1 Running 0 41d
loki-promtail-t4kvd 1/1 Running 0 37d
Кроме подов можно отобразить и другие ресурсы
$ kubectl get svc -n logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
loki ClusterIP 172.20.47.212 <none> 3100/TCP 61d
loki-headless ClusterIP None <none> 3100/TCP 61d
Ключ -o позволяет указать формат вывода, у него масса значений, ниже некоторые основные
$ kubectl get svc -n logging -o name
service/loki
service/loki-headless
$ kubectl get svc -n logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
loki ClusterIP 172.20.47.212 <none> 3100/TCP 61d
loki-headless ClusterIP None <none> 3100/TCP 61d
$ kubectl get svc -n logging -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
loki ClusterIP 172.20.47.212 <none> 3100/TCP 61d app=loki,release=loki
loki-headless ClusterIP None <none> 3100/TCP 61d app=loki,release=loki
$ kubectl get svc -n logging -o json
...
$ kubectl get svc -n logging -o yaml
...
Вывод в формате json можно дальше парсить через jq
$ kubectl get svc -n logging -o json | jq .items[0].spec.clusterIP
"172.20.47.212"
edit/scale/delete
Можно редактировать ресурсы прямо наживую
Команда edit откроет манифест ресурса в вашем редакторе по умолчанию
После сохранения изменения применятся к ресурсу
$ k edit deployments/vm-grafana -n monitoring
deployment.apps/vm-grafana edited
Командой scale можно масштабировать репликасеты
$ k scale --replicas=1 rs/vm-grafana-5d469c787 -n monitoring
replicaset.apps/vm-grafana-5d469c787 scaled
Команда delete удаляет ресурсы
$ kubectl -n monitoring get pod vm-grafana-5d469c787-45qm2
NAME READY STATUS RESTARTS AGE
vm-grafana-5d469c787-45qm2 2/2 Running 0 37d
$ kubectl -n monitoring delete pod vm-grafana-5d469c787-45qm2
pod "vm-grafana-5d469c787-45qm2" deleted
$ kubectl -n monitoring get pod vm-grafana-5d469c787-lcnz8 # из-за deployment'a создался новый под (но старый удалился :) )
NAME READY STATUS RESTARTS AGE
vm-grafana-5d469c787-lcnz8 2/2 Running 0 41s
logs
Чтобы посмотреть конец лога в режиме follow --tail 10 -f (как tail -f) контейнера grafana из пода vm-grafana-5d469c787-lcnz8:
$ k logs -n monitoring vm-grafana-5d469c787-lcnz8 -c grafana --tail 10 -f
{"@level":"debug","@message":"datasource: registering query type fallback handler","@timestamp":"2021-08-16T01:47:16.861844Z"}
t=2021-08-16T01:47:16+0000 lvl=info msg="inserting datasource from configuration " logger=provisioning.datasources name=VictoriaMetrics uid=
t=2021-08-16T01:47:16+0000 lvl=info msg="HTTP Server Listen" logger=http.server address=[::]:3000 protocol=http subUrl= socket=
t=2021-08-16T01:49:15+0000 lvl=eror msg="Failed to look up user based on cookie" logger=context error="user token not found"
t=2021-08-16T01:49:15+0000 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/ status=302 remote_addr=10.0.151.54 time_ms=0 size=29 referer=
t=2021-08-16T01:49:15+0000 lvl=eror msg="Failed to look up user based on cookie" logger=context error="user token not found"
t=2021-08-16T01:49:25+0000 lvl=eror msg="Failed to look up user based on cookie" logger=context error="user token not found"
t=2021-08-16T01:49:25+0000 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=POST path=/api/frontend-metrics status=401 remote_addr=10.0.151.54 time_ms=0 size=26 referer=https://ops.lstbknd.net/login
t=2021-08-16T01:50:01+0000 lvl=eror msg="Failed to look up user based on cookie" logger=context error="user token not found"
t=2021-08-16T01:50:01+0000 lvl=info msg="Successful Login" logger=http.server User=admin@localhost
^C
port-forward
Очень полезная команда
Позволяет прокинуть порт от пода до локального хоста
Например из пода с графаной
$ kubectl -n monitoring port-forward vm-grafana-5d469c787-lcnz8 3000:3000
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
...
И видим в браузере что все работает
diff
Позволяет увидеть разницу между текущим состоянием ресурса и его описанием из файла
$ k apply -f configmap.yaml # применили
configmap/demo-config created
$ vim configmap.yaml # отредактировали
$ k diff -f configmap.yaml # смотрим чем отличаются
diff -u -N /var/folders/zd/bqd54lkx6_zgbwl9l72z8dzr0000gn/T/LIVE-445248743/v1.ConfigMap.default.demo-config /var/folders/zd/bqd54lkx6_zgbwl9l72z8dzr0000gn/T/MERGED-840651034/v1.ConfigMap.default.demo-config
--- /var/folders/zd/bqd54lkx6_zgbwl9l72z8dzr0000gn/T/LIVE-445248743/v1.ConfigMap.default.demo-config 2021-08-16 05:06:20.000000000 +0300
+++ /var/folders/zd/bqd54lkx6_zgbwl9l72z8dzr0000gn/T/MERGED-840651034/v1.ConfigMap.default.demo-config 2021-08-16 05:06:20.000000000 +0300
@@ -1,6 +1,6 @@
apiVersion: v1
data:
- greeting: Salut # это в кластере
+ greeting: Salut-edited # а это в файле
kind: ConfigMap
metadata:
annotations:
Kubernetes for DEVOPS
3. Размещение Kubernetes
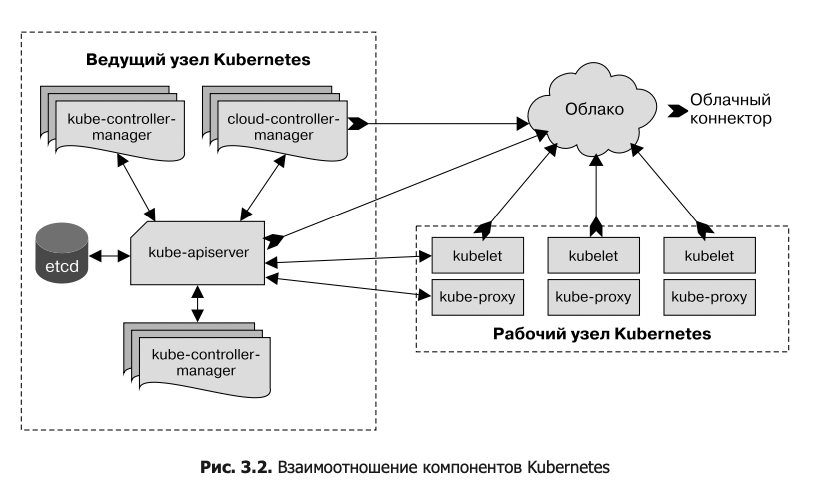
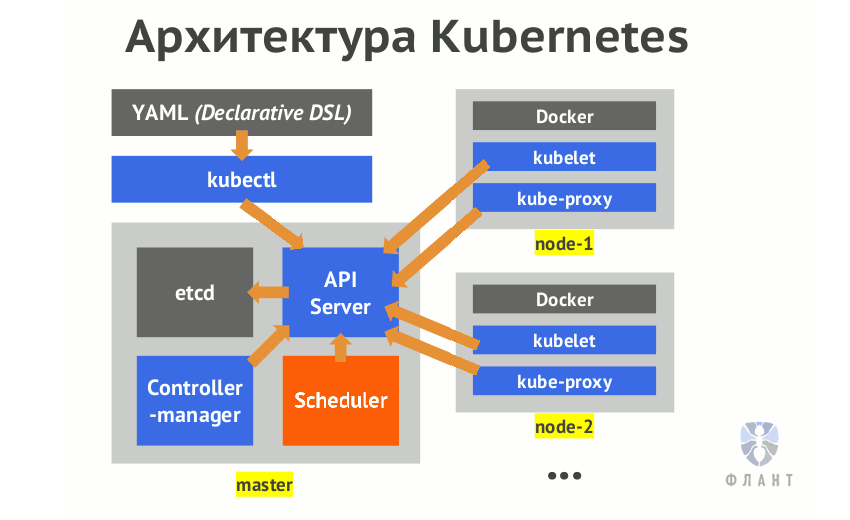
«Мозг» кластера называется управляющим уровнем. Он берет на себя все задачи, необходимые для того, чтобы платформа Kubernetes выполняла свою работу: планирование контейнеров, управление сервисами, обслуживание API-запросов итд
Управляющий уровень на самом деле состоит из нескольких компонентов
- kube-apiserver — это внешний сервер для управляющего.уровня,.который.об- рабатывает.API-запросы.
etcd.—.база.данных,.в.которой.Kubernetes.хранит.всю.информацию.о.существу- ющих.узлах,.ресурсах.кластера.и.т..д.
kube-scheduler.определяет,.где.будут.запущены.свежесозданные.pod-оболочки. kube-controller-manager.отвечает.за.запуск.контроллеров.ресурсов,.таких.как.
развертывания.
cloud-controller-manager взаимодействует с облачным провайдером (в облачных кластерах), управляя такими ресурсами, как балансировщики нагрузки. и дисковые тома
Участники кластера, которые выполняют компоненты управляющего уровня, называются master-узлами
Компоненты узла . Участники.кластера,.которые.выполняют.пользовательские.рабочие.задания,.на- зываются.рабочими узлами
Каждый. рабочий. узел. в. кластере. Kubernetes. отвечает. за. следующие. компо- ненты. kubelet.отвечает.за.управление.средой.выполнения.контейнера,.в.которой.за- пускаются.рабочие.задания,.запланированные.для.узла,.а.также.за.мониторинг. их.состояния. kube-proxy.занимается.сетевой.магией,.которая.распределяет.запросы.между. pod-оболочками. на. разных. узлах,. а. также. между. pod-оболочками. и. Интер- нетом. Среда выполнения контейнеров.запускает.и.останавливает.контейнеры,.а.также. отвечает.за.их.взаимодействие..Обычно.это.Docker,.хотя.Kubernetes.поддержи- вает.и.другие.среды.выполнения.контейнеров,.такие.как.rkt.и.CRI-O.
Хотя.ведущий.узел.обычно.не.выпол- няет.пользовательские.рабочие.задания,.исключение.составляют.очень.маленькие. кластеры
Если. вы. остановите. все. ведущие. узлы. в. своем. кластере,. pod-оболочки. на.рабочих.узлах.продолжат.функционировать.—.по.крайней.мере.какое-то.время.. Однако.вы.не.сможете.развертывать.новые.контейнеры.или.менять.какие-либо.ресур- сы.Kubernetes,.а.такие.контроллеры,.как.deployment,.перестанут.действовать.
4. Работа с объектами Kubernetes
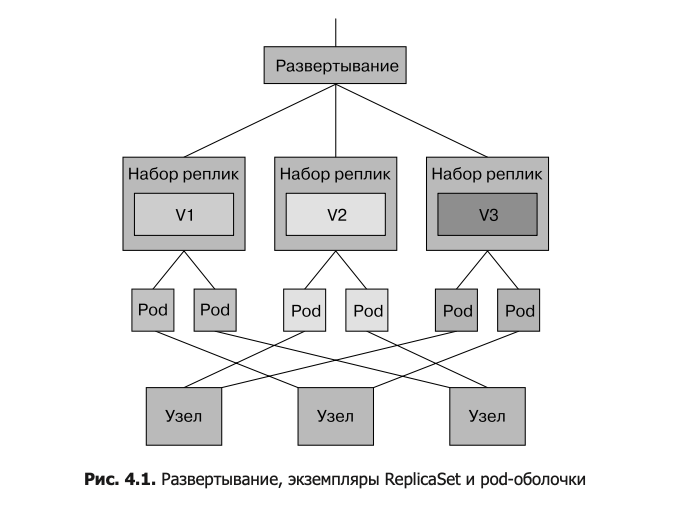
Для. каждой. программы,. за. которой. нужно. следить,. Kubernetes. создает. соответ- ствующий.объект.Deployment,.записывающий.некоторую.связанную.с.ней.инфор- мацию:. имя. образа. контейнера,. количество. реплик. (копий),. которые. вы. хотите. выполнять,.и.любые.другие.параметры,.необходимые.для.запуска.контейн.ера.
В.связке.с.ресурсом.Deployment.работает.некий.объект.Kubernetes.под.названием. контроллер..Контроллеры.отслеживают.ресурсы,.за.которые.отвечают,.убеждаясь. в. том,. что. те. присутствуют. и. выполняются,. а. если. заданное. развертывание. по. какой-либо.причине.не.имеет.достаточного.количества.реплик,.дополнительно.их. создают.. Если. же. реплик. слишком. много,. контроллер. уберет. лишние. —. так. или. иначе,.он.следит.за.тем,.чтобы.реальное.состояние.совпадало.с.желаемым.
На. самом. деле. развертывание. не. управляет. репликами. напрямую:. вместо. этого. оно.автоматически.создает.сопутствующий.объект.под.названием.ReplicaSet,. который.сам.этим.занимается.
Если посмотреть описание deployment'a, то можно будет увидеть pod-template
$ kubectl describe deployments/legion-ui
Name: legion-ui
Namespace: default
CreationTimestamp: Tue, 03 Aug 2021 11:18:07 +0300
Labels: app=legion-ui
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=legion-ui
Replicas: 2 desired | 2 updated | 2 total | 2 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 15
RollingUpdateStrategy: 1 max unavailable, 1 max surge
Pod Template:
Labels: app=legion-ui
Containers:
legion-ui:
Image: registry.gitlab.com/legion_farm/legion_v2/ui:staging
Port: 3000/TCP
Host Port: 0/TCP
Environment:
NODE_ENV: staging
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: legion-ui-697fb9bbc7 (2/2 replicas created)
Events: <none>
В pod-template содержится информация о том как запускать контейнер
На самом деле между deployment'ом и pod'ом есть еще replicaset, но с репликасетом напрямую взаимодействовать не приходится, им управляет деплоймент
При обновлении деплоймента создается новый репликасет с новыми подами, а старый со старыми подами умирает
Контроллеры.Kubernetes.непрерывно.сравнивают.желаемое.состояние,.указанное. каждым. ресурсом,. с. реальным. состоянием. кластера. и. вносят. необходимые. кор- ректировки..Этот.процесс.называют.циклом согласования,.поскольку.он.все.время. повторяется.в.попытке.согласовать.текущее.состояние.с.желаемым.
Создав.развертывание,.вы.сообщили.Kubernetes.о.том,.что.pod-оболочка.demo. должна.работать.всегда..Система.ловит.вас.на.слове,.и,.даже.если.вы.сами.удалите. этот.Pod-объект,.она.посчитает,.что.вы.наверняка.ошиблись,.и.услужливо.запустит. замену.
развертывание создаст pod-оболочки, а Kubernetes при не- обходимости их запустит,.но.не.объяснили,.как.такое.происходит. За.эту.часть.процесса.отвечает.компонент.Kubernetes.под.названием.«планировщик».. Когда.развертывание.(через.соответствующий.объект.ReplicaSet).решит,.что.нуж- на.новая.реплика,.оно.создаст.ресурс.Pod.в.базе.данных.Kubernetes..Одновременно. с.этим.указанный.ресурс.добавляется.в.очередь.—.этакий.ящик.входящих.сообще- ний.для.планировщика. Задача. планировщика. —. следить. за. этой. очередью,. взять. из. нее. следующую. за- планированную. pod-оболочку. и. найти. узел,. на. котором. ее. можно. запустить.. При. выборе. подходящего. узла. (при. условии,. что. такой. имеется). планировщик. будет.исходить.из.нескольких.разных.критериев,.включая.ресурсы,.запрашиваемые. pod-оболочкой
Планировщик Kubernetes отвечает за назначение узлов подам (pods). Суть его работы сводится к следующему:
Вы создаёте под.
Планировщик замечает, что у нового пода нет назначенного ему узла.
Планировщик назначает поду узел.
Он не отвечает за реальный запуск пода — это уже работа kubelet. Всё, что от него в принципе требуется, — гарантировать, что каждому поду назначен узел. Просто, не так ли?
В Kubernetes применяется идея контроллера. Работа контроллера заключается в следующем:
посмотреть на состояние системы;
заметить, где актуальное состояние не соответствует желаемому (например, «этому поду должен быть назначен узел»);
повторить.
Планировщик — один из видов контроллера. Вообще же существует множество разных контроллеров, у всех разные задачи и выполняются они независимо.
у. pod-оболочки. может. быть. несколько. реплик. и. каждая. со. своим. адресом..Любому.другому.приложению,.которому.необходимо.обратиться.к.этой. pod-оболочке,.нужно.будет.хранить.список.адресов,.что.не.кажется.очень.хорошей. идеей. К.счастью,.существует.лучший.способ:.ресурс.типа.«сервис».предоставляет.один. несменяемый.IP-адрес.или.такое.же.доменное.имя,.которые.автоматически.перена- правляют.на.любую.подходящую.pod-оболочку..
Сервис. можно. считать. веб-прокси. или. балансировщиком. нагрузки,. который. на- правляет.запросы.к.группе.внутренних.pod-оболочек.(рис..4.2)..Но.он.не.ограни- чен.веб-портами.и.может.направить.трафик.на.любой.другой.порт.в.соотв.етствии. с.разделом.ports.в.спецификации.
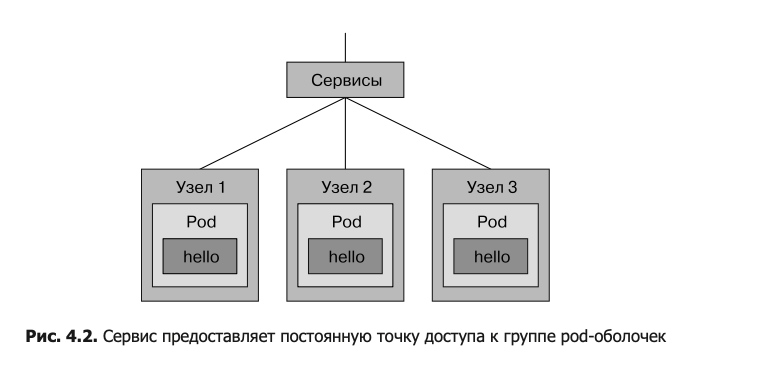
deployment управляет.группой.pod- оболочек.вашего.приложения,.а.сервис.предоставляет.запросам.единую.точку.входа. в.эти.pod-оболочки.
5. Управление ресурсами
Использование. процессорных. ресурсов. pod-оболочкой. выражается,. как. можно. было.ожидать,.в.единицах.процессоров..Одна.такая.единица.эквивалентна.одному. AWS.vCPU,.одному.Google.Cloud.Core,.одному.Azure.vCore.и.одному.гиперпотоку. физического.процессора,.который.поддерживает.гиперпоточность..Иными.словами,. 1 CPU.с.точки.зрения.Kubernetes.означает.то,.о.чем.можно.было.бы.подумать. Поскольку. большинству. pod-оболочек. не. нужен. целый. процессор,. запросы. и. ли- миты. обычно. выражаются. в. миллипроцессорах. (которые. иногда. называют. милли- ядрами)..Память.измеряется.в.байтах.или,.что.более.удобно,.в.мебибайтах.(МиБ)
Например,.запрос.100m.(100.миллипро- цессоров).и.250Mi.(250.МиБ.памяти).означает,.что.pod-оболочка.не.может.быть. назначена.узлу.с.меньшим.количеством.доступных.ресурсов..Если.в.кластере.нет. ни.одного.узла.с.достаточной.мощностью,.pod-оболочка.будет.оставаться.в.состоя- нии.pending,.пока.такой.узел.не.появится.
Лимит на ресурс.определяет.максимальное.количество.этого.ресурса,.которое. pod-оболочке. позволено. использовать.. Если. pod-оболочка. попытается. занять. больше. выделенного. ей. лимита. на. процессор,. производительность. будет. сни- жена
акие.лимиты.следует.устанавливать.для.конкретного.приложения,.зависит.от. ваших.наблюдений.и.личного.мнения.(см..подраздел.«Оптимизация.pod-оболочек». на.с..123). Kubernetes.допускает.отрицательный баланс ресурсов,.когда.сумма.всех.лимитов. у.контейнеров.одного.узла.превышает.общее.количество.ресурсов,.которыми.узел. обладает..Это.своего.рода.азартная.игра:.планировщик.ставит.на.то,.что.большин- ство.контейнеров.большую.часть.времени.не.будут.достигать.своих.лимитов. Если.ставка.себя.не.оправдает,.общее.количество.потребляемых.ресурсов.начнет. приближаться.к.максимальной.мощности.узла.и.Kubernetes.начнет.удалять.кон- тейнеры.более.агрессивно..В.условиях.нехватки.ресурсов.могут.быть.остановлены. даже.те.контейнеры,.которые.исчерпали.запрошенные.ресурсы,.а.не.лимиты1.
Кубер будет убивать поды с приложения в случае если нехватка ресурсов будет угрожать жизни кублета
Всегда заказывайте запросы и лимиты на ресурсы для своих контейнеров. Это поможет Kubernetes как следует управлять вашими pod-оболочками и планиро- вать их работу.
нужно делать маленькие контейнеры
- Мелкие.контейнеры.быстрее.собираются.
- Образы.занимают.меньше.места.
- Загрузка.образов.с.сервера.происходит.быстрее.
- Уменьшается.поверхность.атаки.
Используя golang можно здорово выиграть
Потому что го можно собрать в один бинарь, а контейнер состоящий из одно бинаря уже и не уменьшить
куберу нужно понимать когда под готов принимать запросы и жив ли он вообще (под существует пока в нем существует процесс, но процесс может зависнуть, тогда под будет существовать, но приложение в нем работать не будет)
для этого есть liveness пробы
livenessProbe:
httpGet:
path: /healthz # эндпоинт тут специально с ошибкой, чтобы не конфликтнуть с эндпоинтом приложения
port: 8888
initialDelaySeconds: 3
periodSeconds: 3
Как. скоро. Kubernetes. следует. начинать. проверять. работоспособность?. Никакое. приложение.не.может.стартовать.мгновенно..Если.проверка.произойдет.сразу.после. запуска. контейнера,. она,. скорее. всего,. потерпит. неудачу:. в. результате. контейнер. перезапустится.—.и.этот.цикл.будет.повторяться.бесконечно! Поле.initialDelaySeconds.позволяет.указать.время.ожидания.перед.первой. проверкой.работоспособности,.чтобы.избежать.убийственного цикла (loop of the death). Точно.так.же.Kubernetes.лучше.не.заваливать.ваше.приложение.запросами.к.конеч- ной.точке.healthz.тысячу.раз.в.секунду..Поле.periodSeconds.определяет,.к.ак.часто. следует. выполнять. проверку. работоспособности:. в. данном. примере. это. делается. каждые.три.секунды.
Помимо.httpGet,.доступны.и.другие.типы.проверок..Для.сетевых.серверов,.которые. не.понимают.HTTP,.можно.использовать.tcpSocket: livenessProbe: tcpSocket: port: 8888 Если.TCP-соединение.с.заданным.портом.будет.успешно.установлено,.контей- нер.жив. Вы. можете. также. выполнять. в. контейнере. произвольные. команды,. используя. проверку.exec: readinessProbe: exec: command: - cat - /tmp/healthy Проверка.exec.выполняет.внутри.контейнера.заданную.команду.и.считается.успеш- ной. при. успешном. выполнении. команды. (то. есть. если. завершается. с. нулевым. статусом)..Обычно.exec.лучше.подходит.для.проверки.готовности.
Проверки.готовности.и.работоспособности.имеют.общее.происхождение,.но. разную. семантику.. Иногда. приложению. нужно. просигнализировать. Kubernetes. о.том,.что.оно.временно.неспособно.обрабатывать.запросы:.возможно,.выполняет. длинный.процесс.инициализации.или.ждет.завершения.какого-то.дочернего.про- цесса..Для.этого.предусмотрена.проверка.готовности. Если. ваше. приложение. не. начинает. прослушивать. HTTP,. пока. не. будет. готово. к.обработке.запросов,.проверки.готовности.и.работоспособности.могут.выглядеть. одинаково: readinessProbe: httpGet: path: /healthz port: 8888 initialDelaySeconds: 3 periodSeconds: 3 Контейнер,. не. прошедший. проверку. готовности,. удаляется. из. любых. сервисов,. совпавших.с.заданной.pod-оболочкой..Это.похоже.на.удаление.неисправного.узла. из.пула.балансировщика.нагрузки:.к.pod-оболочке.не.будет.направляться.трафик,. пока.она.опять.не.начнет.успешно.проходить.проверку.готовности.
можно.установить.поле.minReadySeconds.. Контейнеры. или. pod-оболочки. не. будут. считаться. готовыми,. пока. с. момента. успешной.проверки.готовности.не.пройдет.minReadySeconds.секунд.(по.умолча- нию.0).
Ресурс.PodDisruptionBudget. позволяет.указать,.сколько.pod-оболочек.заданного.приложения.допустимо.к.по- тере.в.любой.момент.времени.
Иногда.Kubernetes.нужно.остановить.ваши.pod-оболочки,.даже.если.они.в.полном. порядке.и.готовы.к.работе.(этот.процесс.называется.выселением)..Возможно,.узел,. на.котором.они.размещены,.очищается.перед.обновлением.и.pod-оболочки.необ- ходимо.переместить.на.другой.узел.
minAvailable
maxUnavailable
Доменные.имена.сервисов.всегда.имеют.следующую.структуру: SERVICE.NAMESPACE.svc.cluster.local Приставка..svc.cluster.local.является.необязательной,.равно.как.и.простра.нство. имен..Но.если,.например,.вы.хотите.обратиться.к.сервису.demo.из.пространства. prod,.можно.использовать.такое.имя: demo.prod Даже.если.у.вас.есть.десять.разных.сервисов.под.названием.demo,.каждый.из.ко- торых. размещен. в. отдельном. пространстве,. вы. можете. уточнить,. какой. из. них. имеется.в.виду,.добавив.к.доменному.имени.пространство.имен.
Вы. можете. ограничить. потребление. процессорного. времени. и. памяти. не. только. для.отдельных.контейнеров,.как.было.показано.в.подразделе.«Запросы.ресурсов». на.с..108,.но.и.для.заданных.пространств.имен..Для.этого.в.соответствующем.про- странстве.нужно.создать.ресурс.ResourceQuota..Ниже.показан.пример: apiVersion: v1 kind: ResourceQuota metadata: name: demo-resourcequota spec: hard: pods: "100"
Теперь.Kubernetes.будет.блокировать.любые.API-операции.в.пространстве.имен.demo,. которые.превышают.квоту..В.этом.примере.ResourceQuota.ограничивает.простран- ство.имен.100.pod-оболочками,.поэтому.при.попытке.запуска.101-й.pod-оболочки. вы.увидите.такое.сообщение.об.ошибке: Error from server (Forbidden): pods "demo" is forbidden: exceeded quota: demo-resourcequota, requested: pods=1, used: pods=100, limited: pods=100 Использование.ResourceQuota.—.это.хороший.способ.не.дать.приложе.ниям.из. одного. пространства. имен. захватить. слишком. много. ресурсов. у. других. частей. кластера.
Чтобы.проверить,.активирован.ли.ресурс.ResourceQuotas.в.конкретном.простран- стве.имен,.используйте.команду.kubectl.get.resourcequotas
ограничения нужны в любом случае. Без них контейнер с утечкой памяти или слишком высокими требованиями к процессору может израсходовать все доступные ресурсы на узле и затруднить работу своих соседей.
Чтобы избежать такой ситуации, назначьте контейнеру лимиты, немного превы- шающие 100 % от уровня обычного потребления. Благодаря этому контейнер не будет удален в условиях нормальной работы, а если что-то пойдет не так, масштабы последствий будут минимизированы.
У. Kubernetes. есть. дополнение. под. названием. Vertical. Pod. Autoscaler. (VPA). (github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler),.которое.может.по- мочь. вам. в. подборе. идеальных. значений. для. запросов. ресурсов.. Оно. следит. за. заданным.развертыванием.и.автоматически.регулирует.запросы.ресурсов.для.его. pod-оболочек,.исходя.из.того,.что.те.на.самом.деле.используют..У.дополнения.есть. пробный.режим,.который.просто.дает.советы,.не.модифицируя.запущенные.pod- оболочки,.и.это.может.быть.полезно.
На мелких нодах доля нагрузки на поддержку кластера ощутима (системные приложения занимают какую-то часть ресурсов, и когда ресурсов мало, то эта часть становится заметнй)
На больших нода эта доля менее заметна, но потеря большой ноды влечет потеря большой доли кластера
Поэтому в размере нод нужно найти баланс
Взгляните на относительное потребление ресурсов каждым узлом, используя приборную панель вашего облачного провайдера или команду kubectl top nodes. Чем больше заняты ваши процессоры, тем выше эффективность. Если большие узлы вашего кластера загружены сильнее других, советуем удалить некоторые из узлов помельче и заменить их более крупными.
Ресурсам можно давать аннотации с именем владельца ресурса
Это позволит легко находить ответственного при возникновении проблем или при обнаружении ненужного ресурса
У. вашего. кластера. всегда. должно. быть. достаточно. резервной. мощности,. чтобы. справиться.с.отказом.одного.рабочего.узла.
В.Kubernetes.можно.использовать.концепцию.принадлежности узлов.(node. affinities),.чтобы.pod-оболочки,.отказ.которых.недопустим,.не.размещались.на.пре- рываемых.узлах.


6. Работа с кластерами
если.ваша.текущая.архитектура.состоит.из.десяти.облачных. серверов,.кластеру.Kubernetes,.вероятно,.не.понадобится.больше.десяти.узлов.для. обслуживания.той.же.нагрузки;.плюс.еще.один.в.качестве.резерва..На.самом.деле. это,. скорее. всего,. перебор:. благодаря. равномерному. распределению. нагрузки. между.узлами.Kubernetes.может.достичь.более.высокой.загруженности,.чем.тра- диционные.серверы..Но.чтобы.откалибровать.кластер.для.оптимальной.мощности,. вам.могут.понадобиться.некоторое.время.и.опыт.
Если у вас имеются аппаратные серверы с излишком ресурсов или если вы еще не готовы полностью мигрировать в облако, используйте Kubernetes для вы- полнения контейнерных рабочих заданий на ваших собственных компьютерах.
Не следует выключать те узлы, которые вам больше не нужны. Сначала очистите их, чтобы рабочие задания могли мигрировать на другие узлы, и убедитесь в том, что в вашем кластере остается достаточно свободных ресурсов.
Утилита.K8Guard,.разработанная.компанией.Target,.умеет.искать.распространен- ные.проблемы.в.кластерах.Kubernetes.и.либо.исправлять.их.самостоятельно,.либо. уведомлять.о.них..Вы.можете.сконфигурировать.ее.с.учетом.конкретных.политик. вашего. кластера. (например,. можете. настроить. уведомления. на. случай,. если. ка- кой-либо.образ.контейнера.превышает.1.ГиБ.или.если.правило.условного.доступа. позволяет.обращаться.к.ресурсу.откуда.угодно). K8Guard.также.экспортирует.показатели,.которые.можно.собирать.с.помощью.такой. системы. мониторинга,. как. Prometheus. (больше. об. этом. —. в. главе. 16).. Благодаря. чему,.например,.можно.узнать,.сколько.развертываний.нарушают.ваши.политики,. и. оценить. производительность. ответов. Kubernetes. API.. Это. помогает. н.аходить. и.исправлять.проблемы.на.ранних.этапах. Лучше. всего. сделать. так,. чтобы. утилита. K8Guard. постоянно. работала. с. вашим. кластером.и.могла.предупреждать.вас.о.любых.нарушениях,.как.только.они.про- изойдут.
Copper.(copper.sh).—.это.инструмент.для.проверки.манифестов.Kubernetes.перед. их. развертыванием;. он. отмечает. распространенные. проблемы. или. применяет. отдельные. политики.. Copper. включает. в. себя. проблемно-ориентированный. язык. (domain-specific. language,. DSL),. предназначенный. для. описания. правил. и.политик.проверки.
Если.применить.команду.copper.check.к.манифесту.Kubernetes,.который.содержит. спецификацию.образа.контейнера.latest,.на.экране.появится.следующее.сообще- ние.об.ошибке: copper check --rules no_latest.cop --files deployment.yml Validating part 0 NoLatest - FAIL
Вы,.к.примеру,.можете.выбрать. произвольную.pod-оболочку,.принудительно.ее.остановить.и.проверить,.перезапу- стит.ли.ее.Kubernetes.и.не.повлияет.ли.это.на.частоту.ошибок.в.системе. Ручное.выполнение.такой.процедуры.занимает.много.времени..К.тому.же.вы.мо- жете.подсознательно.обходить.стороной.слишком.важные.для.ваших.приложений. ресурсы..Чтобы.проверка.была.честной,.ее.следует.автоматизировать. Такой. вид. автоматического,. произвольного. вмешательства. в. промышленные. сервисы.иногда.называют.тестом обезьяны.в.честь.инструмента.Chaos.Monkey. («хаотическая. обезьяна»),. разработанного. компанией. Netflix. для. тестирования. своей.инфраструктуры.
Инструмент.Chaos.Monkey,.выключающий.произвольные.облачные.серверы,.вхо- дит.в.состав.пакета.Netflix.Simian Army,.который.содержит.и.другие.инструменты. хаотического тестирования..Latency.Monkey,.например,.создает.коммуникаци- онные.задержки,.симулируя.проблемы.с.сетью,.Security.Monkey.ищет.известные. уязвимости,.а.Chaos.Gorilla.выключает.целую.зону.доступности.AWS.
7. Продвинутые инструменты для работы с Kubernetes
Команда.kubectl.explain.выводит.документацию.для.заданного. типа.ресурсов: kubectl explain pods
На.самом.деле.exp.lain.по- зволяет.копнуть.настолько.глубоко,.насколько.вы.захотите
$ kubectl explain deploy.spec.template.spec.containers.livenessProbe.exec
KIND: Deployment
VERSION: apps/v1
RESOURCE: exec <Object>
DESCRIPTION:
One and only one of the following should be specified. Exec specifies the
action to take.
ExecAction describes a "run in container" action.
FIELDS:
command <[]string>
Command is the command line to execute inside the container, the working
directory for the command is root ('/') in the container's filesystem. The
command is simply exec'd, it is not run inside a shell, so traditional
shell instructions ('|', etc) won't work. To use a shell, you need to
explicitly call out to that shell. Exit status of 0 is treated as
live/healthy and non-zero is unhealthy.
создает.развертывание.для.выполнения.в.заданном.контейнере. Большинство. ресурсов. можно. создавать. явным. образом. с. помощью. команды. kubectl.create: kubectl create namespace my-new-namespace namespace "my-new-namespace" created Аналогично.kubectl.delete.и.удалит.ресурс: kubectl delete namespace my-new-namespace namespace "my-new-namespace" deleted Команда.kubectl.edit.дает.вам.возможность.просматривать.и.модифицировать. любые.ресурсы: kubectl edit deployments my-deployment Этим. вы. откроете. свой. стандартный. текстовый. редактор. с. файлом. манифеста. в.формате.YAML,.который.представляет.заданный.ресурс. Это. хороший. способ. получить. детальную. информацию. о. конфигурации. любого. ресурса,.но.также.вы.можете.в.редакторе.внести.и.необходимые.изменения..После. сохранения.файла.и.выхода.из.редактора.kubectl.обновит.ресурс.так,.словно.вы. применили.к.манифесту.ресурса.команду.kubectl.apply. Если.вы.допустили.какие-либо.ошибки.(например,.некорректный.формат.YAML),. kubectl.об.этом.сообщит.и.откроет.файл,.чтобы.вы.могли.исправить.проблему.
Не используйте императивные команды kubectl, такие как create или edit, в про- мышленных кластерах. Вместо этого всегда управляйте ресурсами с помощью YAML-манифестов в системе контроля версий и применяйте их командой kubectl apply (или используя чарты Helm).
kubectl diff позволяет увидеть разницу между ресурсом в кластере и описанием ресурса в файле
императивные команды можно использовать для генерации манифестов
вместо того чтобы руками писать однотипные огромные шаблонные манифесты, можно генерировать их через kubectl
[node1 ~]$ kubectl run demo --image=cloudnatived/demo:hello --dry-run=client -o yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: demo
name: demo
spec:
containers:
- image: cloudnatived/demo:hello
name: demo
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
С.точки.зрения.Kubernetes.журналом.считается. все,.что.контейнер.записывает.в.потоки вывода сообщений об ошибках.—.это.то,.что. выводит.на.экран.программа,.запущенная.в.терминале.
$ kubectl --namespace kube-system logs --tail 5 openstack-cloud-controller-manager-8lpjb
I0701 17:37:55.155260 1 named_certificates.go:53] loaded SNI cert [0/"self-signed loopback"]: "apiserver-loopback-client@1625161074" [serving] validServingFor=[apiserver-loopback-client] issuer="apiserver-loopback-client-ca@1625161074" (2021-07-01 16:37:53 +0000 UTC to 2022-07-01 16:37:53 +0000 UTC (now=2021-07-01 17:37:55.155236083 +0000 UTC))
I0701 17:37:55.155317 1 secure_serving.go:197] Serving securely on [::]:10258
I0701 17:37:55.155379 1 leaderelection.go:243] attempting to acquire leader lease kube-system/cloud-controller-manager...
I0701 17:37:55.156540 1 tlsconfig.go:240] Starting DynamicServingCertificateController
E0701 17:48:33.165811 1 leaderelection.go:325] error retrieving resource lock kube-system/cloud-controller-manager: etcdserver: request timed out
k attach pod-name - позволяет зааттачиться к поду
$ ksys attach coredns-558bd4d5db-6s25r
If you don't see a command prompt, try pressing enter.
^C
Кон- текст. —. это. сочетание. кластера,. пользователя. и. пространства. имен
Когда.вы.запускаете.команды.kubectl,.они.всегда.выполняются.в.текущем контек- сте
Это.замечательно.—.приготовить. изящный.однострочный.скрипт.командной.оболочки.для.интерактивной.отладки. и.исследования,.но.он.может.оказаться.слишком.сложным.для.чтения.и.обслужи- вания. Для. настоящих. системных. программистов,. которые. автоматизируют. промыш- ленные. рабочие. процессы,. мы. настоятельно. советуем. использовать. и. настоящие системные.языки.программирования..Язык.Go.—.логичный.выбор,.поскольку.он. удовлетворил.требованиям.создателей.Kubernetes,.и,.таким.образом,.данная.плат- форма.включает.в.себя.полноценную.клиентскую.библиотеку.(github.com/kubernetes/ client-go).для.программ.на.Go
8. Работа с контейнерами
Наименьшим развертываемым объектом в кластере Kubernetes являются pod-оболочки, а не контейнеры. Это означает, что все контейнеры в pod- оболочке всегда оказываются на одном компьютере
В качестве интересного упражнения можете сами создать контейнер, не используя такие среды выполнения, как Docker. В отличном докладе Лиз Райс под названием «Что же такое контейнер на самом деле?» (youtu.be/HPuvDm8IC-4) показано, как это делается с нуля в программе на Go.
У.контейнера.также.есть.точка входа.—.команда,.которая.запускается.при.старте.. Обычно. она. приводит. к. созданию. единого. процесса. для. выполнения. команды,. хотя. какие-то. приложения. запускают. несколько. вспомогательных. или. рабочих. подпроцессов..Для.запуска.больше.одного.отдельного.процесса.в.контейнере.нужно. написать.оберточный.скрипт,.который.будет.играть.роль.входной.точки,.запуская. нужные.вам.процессы.
В целом при проектировании pod-оболочек следует задаться вопросом: «Будут ли эти контейнеры работать корректно, если окажутся на разных компьютерах?» Если ответ отрицательный, контейнеры сгруппированы верно. Если ответ положительный, пра- вильным решением, скорее всего, будет разделить их на несколько pod-оболочек.
идентификатор.образа.состоит.из.четырех.разных.частей:.сетевого имени реестра, пространства имен репозитория, репозитория образа.и.тега.. Обязательным.является.лишь.имя.образа..Идентификатор.с.использованием.всех. этих.элементов.выглядит.так: docker.io/cloudnatived/demo:hello
Выбор. тегов. для. контейнера. зависит. лишь. от. вас.. Есть. несколько. популярных. вариантов: теги.с.семантическими.версиями,.такие.как.v1.3.0..Обычно.указывают.на.вер- сию.приложения; тег.на.основе.Git.SHA.вида.5ba6bfd.....Указывает.на.определенную.фиксацию. в.репозитории.исходного.кода,.которая.использовалась.при.сборке.контейнера. (см..подраздел.«Теги.на.основе.Git.SHA».на.с..320); тег,.представляющий.среду,.такую.как.staging.или.production.
https://vsupalov.com/docker-latest-tag/
При развертывании контейнеров в промышленной среде следует избегать тега latest, поскольку это затрудняет отслеживание версий текущих образов и их откат
Если.мейнтейнер.решит. загрузить.в.репозиторий.другой.образ.с.тем.же.тегом,.при.вашем.следующем.раз- вертывании. вы. получите. его. обновленную. версию.. Говоря. техническим. языком,. теги.являются.недетерминистическими.
Иногда.желательно.иметь.детерминистические.развертывания,.то.есть.гарантиро- вать,.что.развертывание.всегда.ссылается.именно.на.тот.образ.контейнера,.который. вы.указали..Этого.можно.добиться.с.помощью.контрольной суммы.контейнера:. криптографического.хеша,.который.неизменно.идентифицирует.данный.образ.
Образы.могут.иметь.много.тегов,.но.только.одну.контрольную.сумму..Это.означает,. что.при.задании.в.манифесте.контейнера.контрольной.суммы.образа.вы.гаранти- руете.детерминистические.развертывания
этот хеш называют digest
Каждый. контейнер. может. предоставить. один. или. несколько. параметров. в. своей. спецификации: resources.requests.cpu; resources.requests.memory; resources.limits.cpu; . resources.limits.memory. Запросы.и.лимиты.указываются.для.отдельных.контейнеров,.но.обычно.мы.гово- рим.о.них.в.контексте.ресурсов.pod-оболочки..В.таком.случае.запрос.ресурсов.будет. суммой.всех.запросов.для.всех.контейнеров.этой.pod-оболочки.и.т..д
Поле.imagePullPolicy.в.специ- фикации. контейнера. определяет,. насколько. часто. Kubernetes. будет. это. делать.. Возможно.одно.из.трех.значений:.Always,.IfNotPresent.или.Never
Использование.переменных.среды.—.это.распространенный,.хотя.и.ограниченный. способ.передачи.информации.контейнеру.на.этапе.выполнения..Он.распространен. ввиду.того,.что.доступ.к.этим.переменным.имеют.все.исполняемые.файлы.в.Linux,. и.даже.программы,.написанные.задолго.до.появления.контейнеров,.могут.исполь- зовать.их.для.конфигурации..Ограниченность.способа.связана.с.тем,.что.перемен- ные. среды. могут. иметь. лишь. строковые. значения:. никаких. массивов,. словарей. или.любых.других.структурированных.данных..Кроме.того,.общий.размер.среды. процесса.не.может.превышать.32.КиБ,.поэтому.невозможно.передавать.через.него. большие.файлы.
Если.образ.контейнера.сам.указывает.переменные.среды.(например,.в.Dockerfile),. параметр.env,.принадлежащий.Kubernetes,.их.перезапишет..Это.может.пригодиться. для.изменения.конфигурации.контейнера.по.умолчанию.
На своем сервере вы ничего не запускаете от имени администратора (по крайней мере, это нежелательно). Точно так же ничто в вашем контейнере не должно ра- ботать с администраторскими привилегиями. Запуск двоичных файлов, созданных в других местах, требует значительного доверия. Это относится и к двоичным файлам внутри контейнеров.
Кроме. того,. взломщики. могут. воспользоваться. ошибкой. в. среде. выполнения. контейнера,.чтобы.выйти.за.его.пределы.и.получить.те.же.права.и.привилегии.на. основном.компьютере.
Для. максимальной. безопасности. каждый. контейнер. должен. иметь. отд.ельный. UID..Например,.если.он.каким-то.образом.будет.скомпрометирован.или.случайно. попытается.перезаписать.данные,.он.не.навредит.другим.контейнерам,.потому.что. имеет.доступ.только.к.своим.собственным.данным. Но.если.нужно,.чтобы.два.контейнера.или.более.могли.работать.с.одними.и.теми.же. данными.(например,.через.подключенный.том),.вы.должны.назначить.им.одина- ковые.UID.
Kubernetes.позволяет.блокировать.запуск. контейнеров,.которые.собираются.работать.от.имени.администратора. Для.этого.предусмотрен.параметр.runAsNonRoot:.true
Еще.одна.настройка,.полезная.с.точки.зрения.безопасности,.—.readOnlyRo.otFi- lesystem,. не. позволяющая. контейнеру. записывать. в. его. собственную. файловую. систему.. Вполне. возможно. представить. ситуацию,. когда. контейнер. пользуется. уязвимостью.в.Docker.или.Kubernetes,.вследствие.которой.могут.измениться.файлы. на.родительском.узле.через.запись.в.локальную.файловую.систему..Если.файловая. система.находится.в.режиме.«только.для.чтения»,.этого.не.произойдет,.потому.что. контейнер.получит.ошибку.ввода/вывода: containers:
- name: demo image: cloudnatived/demo:hello securityContext: readOnlyRootFilesystem: true Многим. контейнерам. не. нужно. ничего. записывать. в. собственную. файловую. систему,. поэтому. подобная. конфигурация. не. помешает. их. работе.. Параметр. readOnlyRootFilesystem.рекомендуется.(kubernetes.io/blog/2016/08/security-best-practices- kubernetes-deployment).устанавливать.всегда,.если.только.контейнеру.действительно. не.нужно.производить.запись.в.файлы.
даже.если.он.работает.от. имени.обычного.пользователя.(с.UID.1000,.например),.но.в.нем.есть.исполняемый. файл.с.setuid,.этот.файл.может.по.умолчанию.получить.администраторские.при- вилегии. Чтобы.подобного.не.случилось,.присвойте.полю.allowPrivilegeEscalation.в.по- литике.безопасности.контейнера.значение.false: containers:
- name: demo image: cloudnatived/demo:hello securityContext: allowPrivilegeEscalation: false Вы.можете.управлять.этой.настройкой.на.уровне.всего.кластера,.а.не.отдельного. контейнера.(см..подраздел.«Политики.безопасности.pod-оболочек».на.с..198). Современным.программам.в.Linux.не.нужен.бит.setuid,.они.могут.достичь.того.же.ре- зультата.с.помощью.более.гибкого.механизма.привилегий.под.названием.«мандаты»
Например,. веб-сервер,. который. прослушивает. порт. 80,. должен. выполняться. от. имени.администратора:.номера.портов.ниже.1024.считаются.системными.и.привиле- гированными..Вместо.этого.программе.может.быть.выдан.мандат.NET_BIND_SERVICE,. который.позволит.привязать.ее.к.любому.порту,.но.не.даст.никаких.других.особых. привилегий.
Контекст.безопасности.Kubernetes позволяет. убрать. любой. мандат. из. стандартного. набора. или. добавить. его. туда. в.случае.необходимости..Например: containers:
- name: demo image: cloudnatived/demo:hello securityContext: capabilities: drop: ["CHOWN", "NET_RAW", "SETPCAP"] add: ["NET_ADMIN"] Контейнер.будет.лишен.мандатов.CHOWN,.NET_RAW.и.SETPCAP,.но.получит.мандат. NET_ADMIN.
Для.максимальной.безопасности.следует.убрать.любые.мандаты.для.контейнеров. и.затем.по.мере.необходимости.отдельно.их.выдавать: . containers:
- name: demo image: cloudnatived/demo:hello securityContext: capabilities: drop: ["all"] add: ["NET_BIND_SERVICE"]
Вместо.того.чтобы.указывать.параметры.безопасности.для.каждой.отдельной.pod- оболочки. или. контейнера,. вы. можете. описать. их. на. уровне. кластера. с. помощью. ресурса.PodSecurityPolicy
PodSecurityPolicie.использовать.не.так.и.просто,.поскольку.вам.придется.самим. создавать.политики,.выдавать.им.доступ.к.нужным.служебным.учетным.записям. через.RBAC.и.включать.контроллер.доступа.PodSecurityPolicy.в.своем.кластере.. Но. если. у. вас. большая. инфраструктура. или. вы. не. контролируете. напрямую.конфигурацию.безопасности.отдельных.pod-оболочек,.PodSecurityPolicy.будет. хорошим.выбором
Если.по.каким-то. причинам. нужно. будет. выдать. дополнительные. права. (например,. доступ. к. pod- оболочкам.из.других.пространств.имен),.можно.создать.для.приложения.отдель- ную.служебную.учетную.запись,.привязать.ее.к.необходимым.ролям.и.прописать. в.конфигурации.pod-оболочки. Для.этого.укажите.в.поле.serviceAccountName.спецификации.pod-оболочк.и.имя. служебной.учетной.записи: apiVersion: v1 kind: Pod ... spec: serviceAccountName: deploy-tool
Некоторые примеры использования тома emptyDir:
область временных файлов;
контрольные точки во время длительных задач;
хранение данных, полученных сопроводительным контейнером и обслуживаемых контейнером приложения.
В случае сбоев контейнеров данные в томе emptyDir сохраняются. Но при перезапуске контейнеров сохранность данных в томе emptyDir не гарантируется. Если группа контейнеров останавливается, том emptyDir не сохраняется.
Максимальный размер тома emptyDir для Linux составляет 50 ГБ.
Чтобы.использовать.новое.хранилище,.контейнеру.не.нужно.делать.ничего.особен- ного:.все,.что.он.записывает.в.каталог./cache,.будет.попадать.в.том.и.становиться. доступным.для.других.контейнеров,.к.которым.этот.том.также.подключен..Все.кон- тейнеры,.подключившие.том,.могут.производить.с.ним.операции.чтения.и.записи.
cgroups
Контрольные Группы (control groups) нужны для того, чтобы ограничивать процессам доступные ресурсы
Потому что если какой-то процесс потребит все ресурсы системы, то их не хватит для других, возможно, более важных процессов
В ядро 4.5 была официально добавлена новая версия механизма cgroups - cgroup v2
(cgroupv2 по сути переписан с нуля, он стремится избежать некоторых недостатков cgroup v1, предоставляя более унифицированный и предсказуемый интерфейс, используется только одна иерархия cgroup, в отличие от множества иерархий в cgroup v1)
Механизм cgroup состоит из ядра и подсистем
blkio— устанавливает лимиты на чтение и запись с блочных устройств;cpuacct— генерирует отчёты об использовании ресурсов процессора;cpu— обеспечивает доступ процессов в рамках контрольной группы к CPU;cpuset— распределяет задачи в рамках контрольной группы между процессорными ядрами;devices— разрешает или блокирует доступ к устройствам;freezer— приостанавливает и возобновляет выполнение задач в рамках контрольной группыhugetlb— активирует поддержку больших страниц памяти для контрольных групп;memory— управляет выделением памяти для групп процессов;net_cls— помечает сетевые пакеты специальным тэгом, что позволяет идентифицировать пакеты, порождаемые определённой задачей в рамках контрольной группы;netprio— используется для динамической установки приоритетов по трафику;pids— используется для ограничения количества процессов в рамках контрольной группы.
Список подсистем можно получить так:
root@mon-test-vm-03x:/sys/fs/cgroup# ls -lh
total 0
dr-xr-xr-x 6 root root 0 Aug 25 2023 blkio
lrwxrwxrwx 1 root root 11 Aug 25 2023 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 Aug 25 2023 cpuacct -> cpu,cpuacct
dr-xr-xr-x 6 root root 0 Aug 25 2023 cpu,cpuacct
dr-xr-xr-x 3 root root 0 Aug 25 2023 cpuset
dr-xr-xr-x 6 root root 0 Aug 25 2023 devices
dr-xr-xr-x 3 root root 0 Aug 25 2023 freezer
dr-xr-xr-x 6 root root 0 Aug 25 2023 memory
lrwxrwxrwx 1 root root 16 Aug 25 2023 net_cls -> net_cls,net_prio
dr-xr-xr-x 3 root root 0 Aug 25 2023 net_cls,net_prio
lrwxrwxrwx 1 root root 16 Aug 25 2023 net_prio -> net_cls,net_prio
dr-xr-xr-x 3 root root 0 Aug 25 2023 perf_event
dr-xr-xr-x 6 root root 0 Aug 25 2023 pids
dr-xr-xr-x 2 root root 0 Aug 25 2023 rdma
dr-xr-xr-x 6 root root 0 Aug 25 2023 systemd
dr-xr-xr-x 5 root root 0 Aug 25 2023 unified
Чтобы создать контрольную группу нужно создать директорию в любой из подсистем. Там автоматически будут созданы все управляющие файлы
Чтобы добавить процессы в группу нужно прописать их pid'ы в файл tasks
root@mon-test-vm-03x:/sys/fs/cgroup/cpu# mkdir vandudcgroup
root@mon-test-vm-03x:/sys/fs/cgroup/cpu# mkdir vandudcgroup/vandudchildcgroup
root@mon-test-vm-03x:/sys/fs/cgroup/cpu# mkdir vandudcgroup/vandudchildcgroup/vandudchildchildcgroup
root@mon-test-vm-03x:/sys/fs/cgroup/cpu# tree vandudcgroup/
vandudcgroup/
├── cgroup.clone_children
├── cgroup.procs
├── cpuacct.stat
├── cpuacct.usage
├── cpuacct.usage_all
├── cpuacct.usage_percpu
├── cpuacct.usage_percpu_sys
├── cpuacct.usage_percpu_user
├── cpuacct.usage_sys
├── cpuacct.usage_user
├── cpu.cfs_period_us
├── cpu.cfs_quota_us
├── cpu.shares
├── cpu.stat
├── notify_on_release
├── tasks
└── vandudchildcgroup
├── cgroup.clone_children
├── cgroup.procs
├── cpuacct.stat
├── cpuacct.usage
├── cpuacct.usage_all
├── cpuacct.usage_percpu
├── cpuacct.usage_percpu_sys
├── cpuacct.usage_percpu_user
├── cpuacct.usage_sys
├── cpuacct.usage_user
├── cpu.cfs_period_us
├── cpu.cfs_quota_us
├── cpu.shares
├── cpu.stat
├── notify_on_release
├── tasks
└── vandudchildchildcgroup
├── cgroup.clone_children
├── cgroup.procs
├── cpuacct.stat
├── cpuacct.usage
├── cpuacct.usage_all
├── cpuacct.usage_percpu
├── cpuacct.usage_percpu_sys
├── cpuacct.usage_percpu_user
├── cpuacct.usage_sys
├── cpuacct.usage_user
├── cpu.cfs_period_us
├── cpu.cfs_quota_us
├── cpu.shares
├── cpu.stat
├── notify_on_release
└── tasks
2 directories, 48 files
root@mon-test-vm-03x:/sys/fs/cgroup/cpu# yes >/dev/null &
[2] 26816
root@mon-test-vm-03x:/sys/fs/cgroup/cpu# echo 26816 > vandudcgroup/vandudchildcgroup/vandudchildchildcgroup/tasks
root@mon-test-vm-03x:/sys/fs/cgroup/cpu# cat vandudcgroup/vandudchildcgroup/vandudchildchildcgroup/tasks
26816