Administrator Linux. Professional
Дисковая подсистема
VFS
VFS (Virtual File System) - абстрактная файловая система служащая для интерпретации системных вызовов приложений в язык понятный различным файловым системам. Своеобразная унификация
Самый банальный пример, это когда приложение обращается к локальной и сетевой файловой системе не замечая практической разницы. За него это делает VFS
https://habr.com/ru/companies/otus/articles/446614/
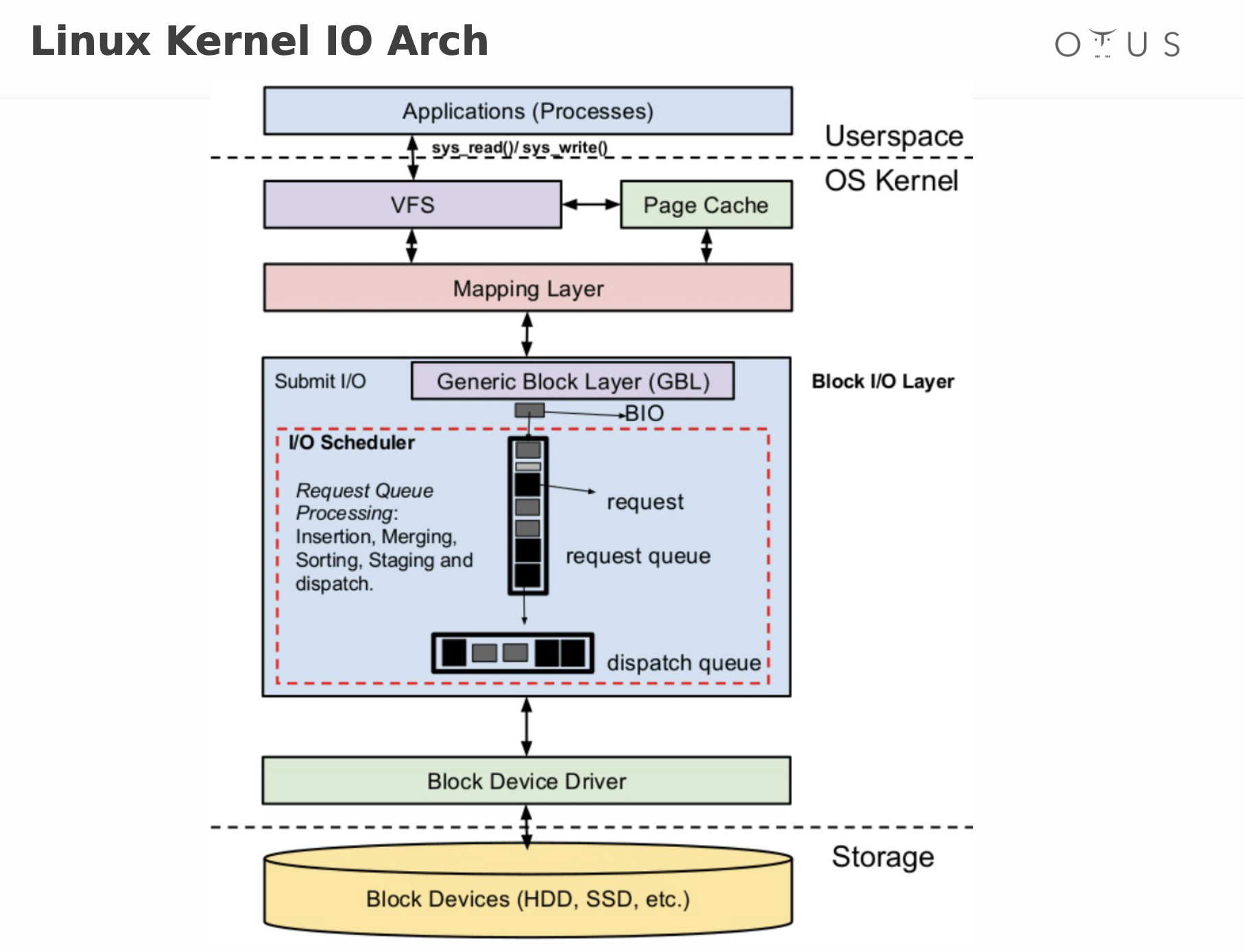
Ядро Linux имеет определенные требования к сущности, которая может считаться файловой системой. Она должна реализовывать методы open(), read() и write() для постоянных объектов, которые имеют имена. С точки зрения объектно-ориентированного программирования, ядро определяет обобщенную файловую систему (generic filesystem) в качестве абстрактного интерфейса, а эти три большие функции считаются «виртуальными» и не имеют конкретного определения. Соответственно, реализация файловой системы по умолчанию называется виртуальной файловой системой (VFS)
Знакомые нам системы, такие как ext4, NFS и /proc имеют три важные функции в структуре данных С, которая называется file_operations. Кроме того, определенные файловые системы расширяют и переопределяют функции VFS привычным объектно-ориентированным способом
В ядре также содержатся сущности, такие как cgroups, /dev и tmpfs, которые требуются в процессе загрузки и поэтому определяются в подкаталоге ядра init/. Заметьте, что cgroups, /dev и tmpfs не вызывают «большую тройку» функций file_operations, а напрямую читают и пишут в память
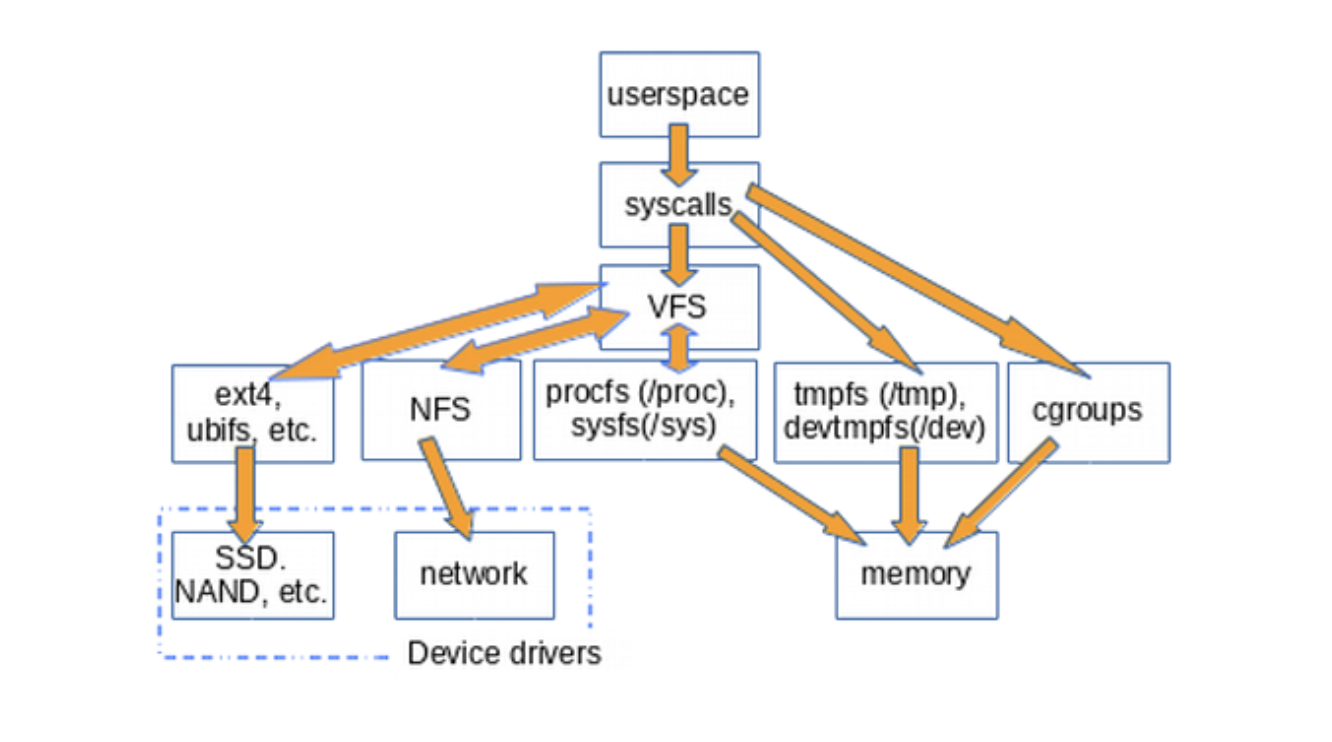
VFS — это «слой оболочки» между системными вызовами и реализациями определенных file_operations, таких как ext4 и procfs. Функции file_operations могут взаимодействовать либо с драйверами устройств, либо с устройствами доступа к памяти. tmpfs, devtmpfs и cgroups не используют file_operations, а напрямую обращаются к памяти
Существование VFS обеспечивает возможность переиспользовать код, так как основные методы, связанные с файловыми системами, не должны быть повторно реализованы каждым типом файловой системы
Помимо /tmp, VFS (виртуальные файловые системы), которые наиболее знакомы пользователям Linux – это /proc и /sys. (/dev располагается в общей памяти и не имеет file_operations)
procfs создает снимок мгновенного состояния ядра и процессов, которые он контролирует для userspace. В /proc ядро выводит информацию о том, какими средствами оно располагает, например, прерывания, виртуальная память и планировщик. Кроме того, /proc/sys – это место, где параметры, настраиваемые с помощью команды sysctl, доступны для userspace. Статус и статистика отдельных процессов выводится в каталогах /proc/
Поведение /proc файлов показывает, какими непохожими могут быть дисковые файловые системы VFS. С одной стороны, /proc/meminfo содержат информацию, которую можно посмотреть командой free. С другой же, там пусто. Дело в том, что ядро собирает статистику памяти, когда происходит запрос к /proc, и на самом деле в файлах /proc ничего нет, когда никто туда не смотрит
root@docs:~# file /proc/meminfo
/proc/meminfo: empty
root@docs:~# wc -l /proc/meminfo
51 /proc/meminfo
root@docs:~# head /proc/meminfo
MemTotal: 2018392 kB
MemFree: 92596 kB
MemAvailable: 1405692 kB
Buffers: 85360 kB
Cached: 1341856 kB
SwapCached: 0 kB
Active: 631124 kB
Inactive: 1149328 kB
Active(anon): 364 kB
Inactive(anon): 371384 kB
Кажущаяся пустота procfs имеет смысл, поскольку располагающаяся там информация динамична. Немного другая ситуация с sysfs
Цель sysfs – предоставить свойства доступные для чтения и записи того, что ядро называет «kobjects» в userspace. Единственная цель kobjects – это подсчет ссылок: когда удаляется последняя ссылка на kobject, система освободит ресурсы, связанные с ним
Ничего не понял, но начало этой статьи что-то объясняет - https://dmilvdv.narod.ru/Translate/LDD3/ldd_kobjects_ksets_subsystem.html
Файлы в sysfs описывают одно конкретное свойство для каждой сущности и могут быть читаемыми, перезаписываемыми или и то и другое сразу
Блочное устройство обеспечивает обмен блоками данных. Блок (chunk)— это единица данных фиксированного размера. Размер блока определяется ядром, но чаще всего он совпадает с размером страницы аппаратной архитектуры, и для 32-битной архитектуры x86 составляет 4096 байт
В настоящее время существует два подхода к организации /dev:
- Статическая организация - специальные файлы для всех возможных устройств вне зависимости от того, загружен драйвер соответствующего устройства или нет. Уходящая в прошлое организация
- Динамическая организация - специальные файлы в
/devсоздаются по мере инициализации устройств и загрузки драйверов, и удаляются при выгрузке соответствующего драйвера или удалении устройства
Процесс работы со статическим /dev особых проблем не вызывает – системный администратор при необходимости просто создает
отсутствующие файлы командой mknod
DevFS
Ядро монтирует к каталогу /dev специальную файловую систему, называемую devfs:
- Целиком находится в оперативной памяти
- Драйвер devfs динамически создает специальный файл
- Динамически же удаляет его
Udev
В отличие от devsfd, который требовал поддержки со стороны ядра, udev такой поддержки не требует:
- Постоянно закрепленные за устройствами имена, которые не зависят от того, какое положение они занимают в дереве устройств
- Уведомление внешних по отношению к ядру программ, если устройство было заменено
- Гибкие правила именования устройств
devtmpfs
На текущий момент используется devtmpfs + udev (systemd+udevd)
После монтирования корневой файловой системы, этот экземпляр tmpfs перемонтируется ядром в каталог /dev
devtmpfsотвечает за заполнение каталога/devudevза права доступа, необходимые симлинки и запуск скриптов пользователя
Hardware RAID
Преимущества:
- Аппаратное решение, не влияющее на производительность основной системы
- Выделенный CPU
- Выделенная память для Кэшей
- Возможность использовать BBU (Battery Backup Unit)
- Возможность подключения большого количества дисков
- Прозрачность для загрузчиков (возможность грузиться с любого массива)
Недостатки:
- Высокая стоимость
- Высокая сложность
- Разнообразность интерфейсов управления и драйверов
- Низкая «мобильность»/переносимость
- Привязка к железу
- Бóльший простой по времени при аварии
- Очень дорогой ремонт, необходимость закупать впрок контроллеры, которые потом могут прекратить выпускать
Software RAID
Преимущества:
- Бесплатно
- Отсутствие привязки к конкретному железу
- Прозрачность конфигурации
- Примерно одинаковый интерфейс управления в любом linux
- Легкая переносимость между компьютерами
- Гибкость конфигурации
Недостатки:
- Отсутствие BBU
- Отсутствие выделенного кэша
- Отсутствие службы поддержки :-)
RAID
Вычислительные алгоритмы, которые используются при построении RAID-массивов, появлялись постепенно и впервые были классифицированы в 1993 году в работе Chen, Lee, Gibson, Katz, & Patterson, 1993
RAID-0
В соответствии с этой классификацией массивом RAID-0 именуется массив независимых дисков, в котором не предпринимаются меры по защите информации от утраты. Преимущество таких массивов по сравнению с одиночным диском состоит в возможности существенного увеличения ёмкости и производительности за счёт организации параллельного обмена данными
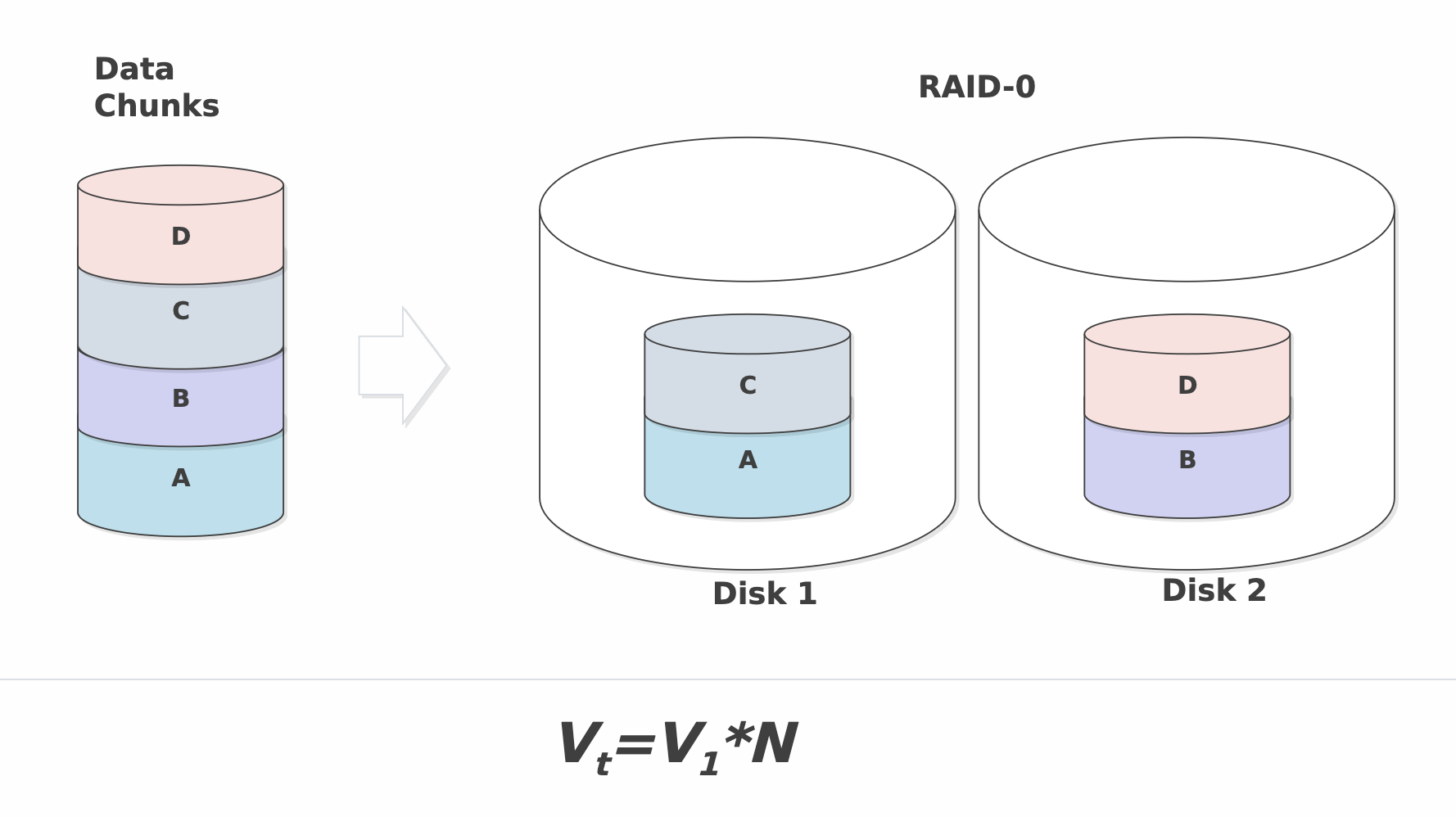
Преимущества:
- Самое быстрое чтение
- Очень простой
- Максимальная эффективность использования дискового пространства
Недостатки: - Не «настоящий» RAID, нет отказоустойчивости: отказ одного диска влечет за собой потерю всех данных массива
RAID-1
Технология RAID-1 подразумевает дублирование каждого диска системы. Таким образом, массив RAID-1 имеет удвоенное количество дисков по сравнению с RAID-0, но выход из строя одного диска системы не влечёт за собой утрату данных, поскольку в массиве для каждого диска имеется копия
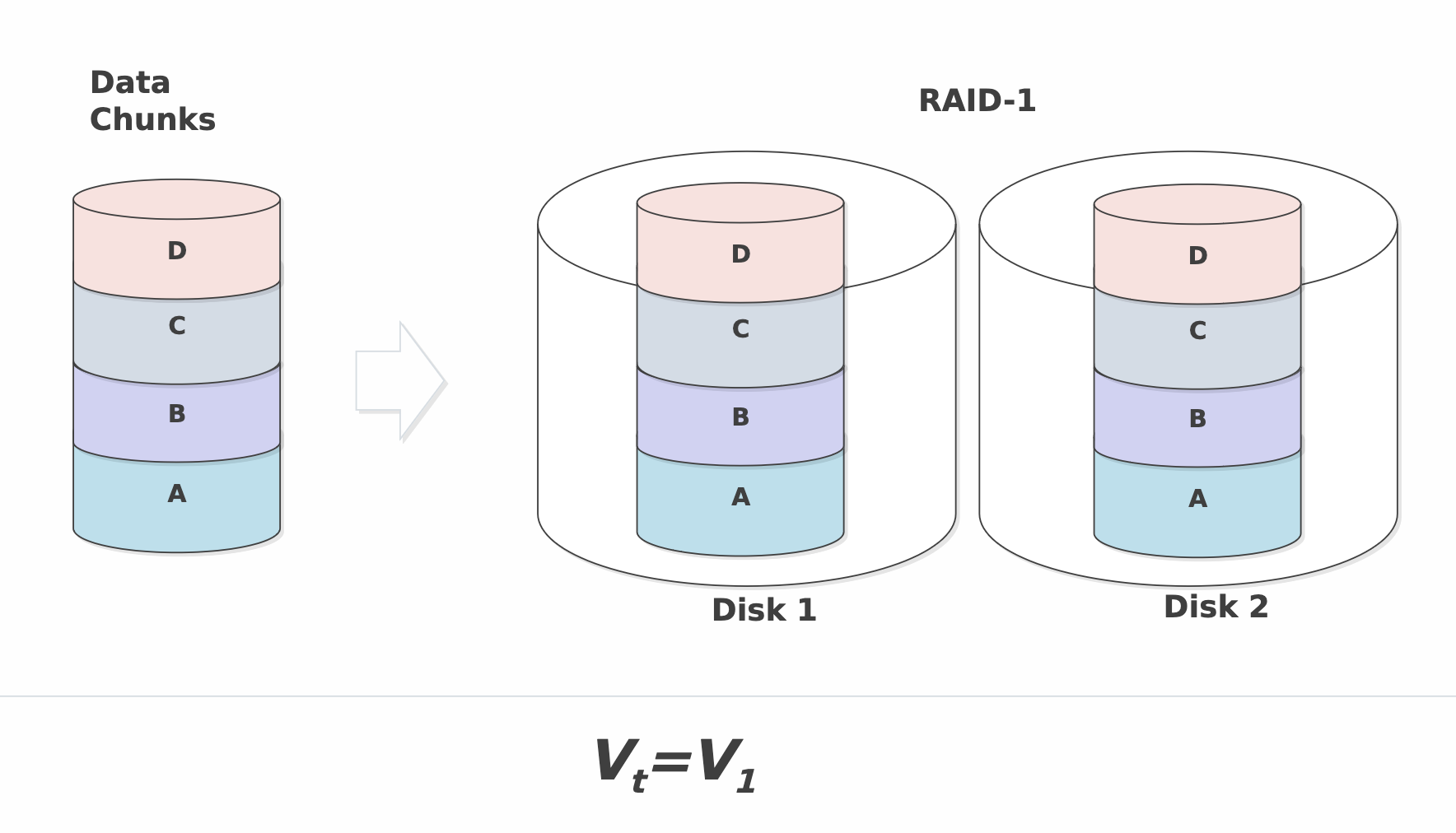
Преимущества:
- Простота реализации
- Простота восстановления: перекопировать все данные с «выжившего» диска
- Высокая скорость на чтение
Недостатки:
- Высокая стоимость на единицу объема: 100% избыточность
RAID-2 / RAID-3
Технологии RAID-2 и RAID-3 не получили распространения на практике, и мы опустим их описание
RAID-4
Технология RAID-4 подразумевает использование одного дополнительного диска, на который записывается сумма (XOR) остальных дисков данных СХД
Контрольная сумма (или синдром) обновляется при выполнении каждой записи данных на диски СХД. Отметим, что для этого нет необходимости вычислять заново, а достаточно прибавить к синдрому разность старого и нового значения изменяемого диска. В случае выхода из строя одного из дисков уравнение может быть решено относительно появившегося неизвестного, т.е. данные с утраченного диска будут восстановлены
Очевидно, что операции чтения и записи синдрома происходят чаще, чем операции с любым другим диском данных. Этот диск становится самым загруженным элементом массива, т.е. слабым звеном с точки зрения производительности. Кроме того, он быстрее изнашивается
RAID-5
Для решения этой проблемы была предложена технология RAID-5, в которой для хранения синдромов используются части различных дисков системы. Таким образом, загрузка дисков операциями чтения и записи выравнивается

Технологии RAID-1 — RAID-5 позволяют восстанавливать данные в случае выхода из строя одного из дисков, но в случае утраты двух дисков эти технологии оказываются бессильны. Конечно, вероятность одновременного выхода из строя двух дисков значительно ниже, чем одного. Однако на практике замена отказавшего диска требует определенного времени, в течение которого данные остаются «беззащитными»
Преимущества:
- Высокая скорость записи данных
- Достаточно высокая скорость чтения данных
- Высокая производительность при большой интенсивности запросов чтения/записи данных
- Малые накладные расходы для реализации избыточности
Недостатки:
- Низкая скорость чтения/записи данных малого объема при единичных запросах
- Достаточно сложная реализация
- Сложное восстановление данных
RAID-6
Для решения указанных задач была предложена технология RAID-6, ориентированная на восстановление двух дисков
RAID 6 представляет собой расширение RAID 5. При использовании этой технологии даже отказ сразу двух жестких дисков в одной группе не приведет к потере данных. В случае RAID 6 для восстановления информации необходимо провести две математические операции. Первая та же, что и в случае технологии RAID 5 («исключающее или»), вторая требует наличия дополнительного жесткого диска Q, поэтому и сама технология называется проверкой четности P+Q
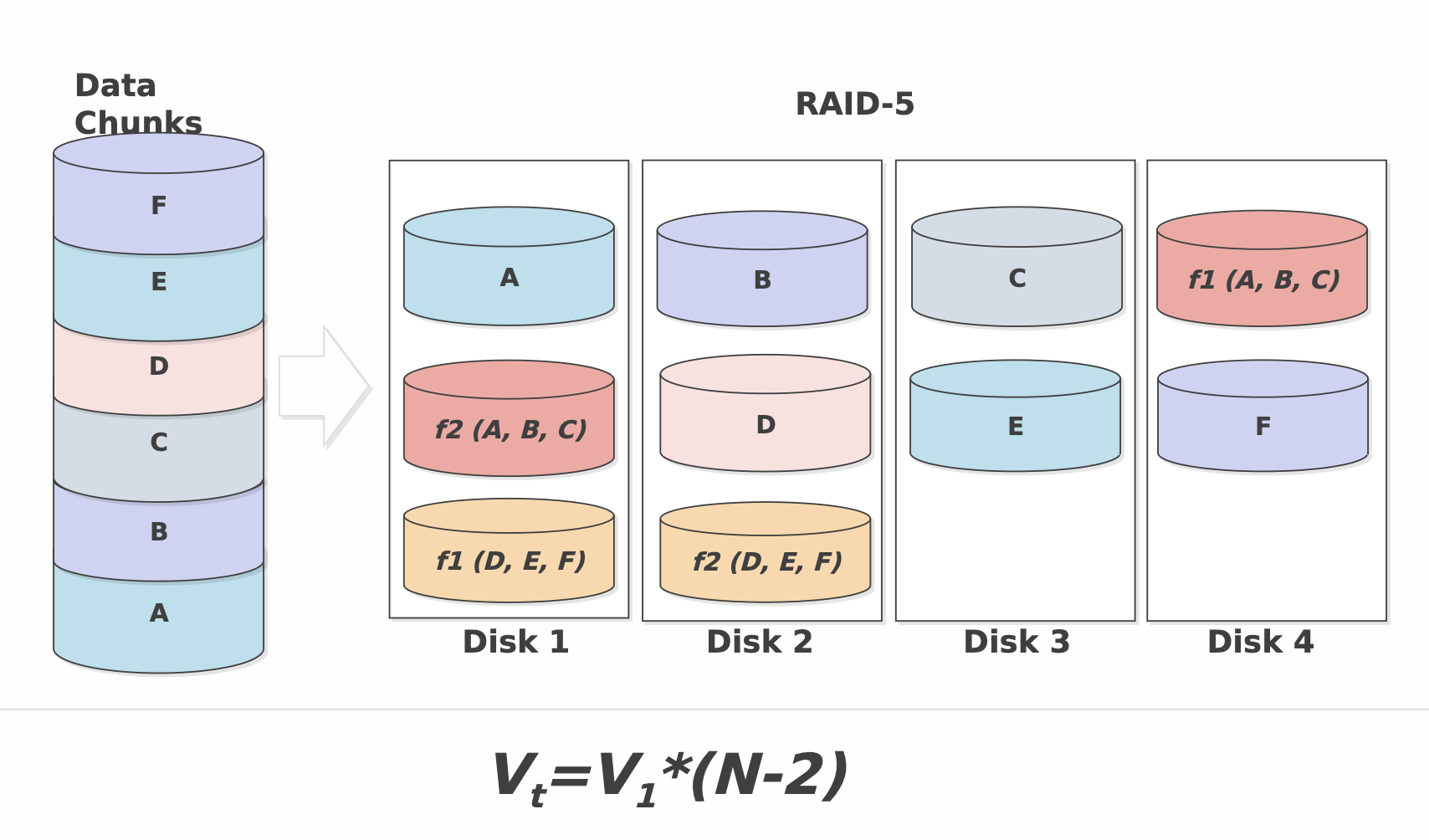
Преимущества:
- Высокая отказоустойчивость
- Достаточно высокая скорость обработки запросов
- Относительно малые накладные расходы для реализации избыточности
Недостатки:
- Очень сложная реализация
- Сложное восстановление данных
- Очень низкая скорость записи данных
RAID-10
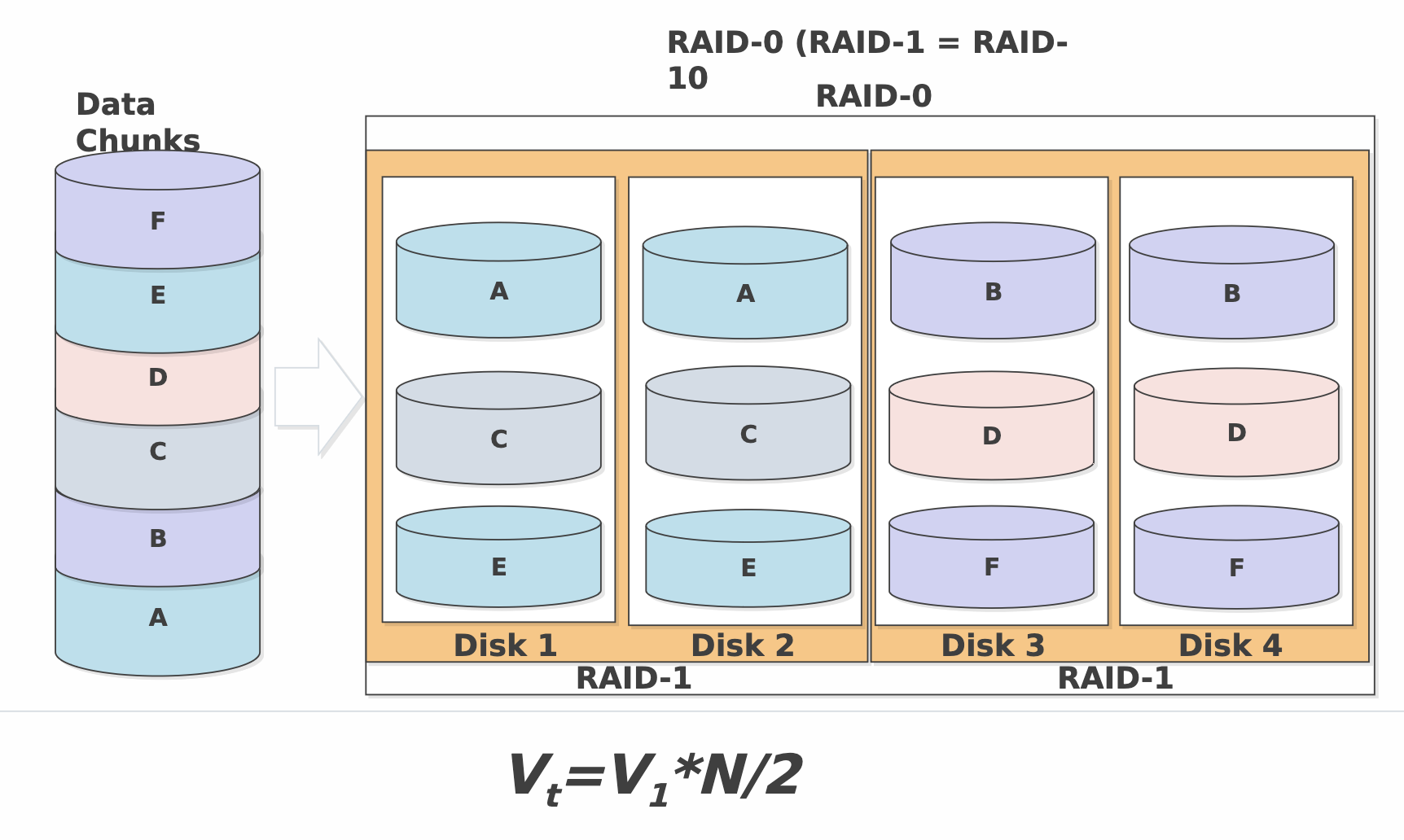
RAID-10 - Рэйд один ноль
Страйп из двух пар зеркал
Рэйд 0 из Рэйд 1
Преимущества:
- Самая высокая отказоустойчивость
- Самая высокая производительность
- Сочетает в себе преимущества R0 и R1
Недостатки:
- Двойная стоимость пространства
RAID-5
https://www.open-e.com/blog/how-does-raid-5-work/
Сперва надо вспомнить определение операции XOR:
Результат функции XOR равен 1 если оба аргумента отличаются
XOR (0, 1) = 1
XOR (1, 0) = 1
Результат функции XOR равен 0 если оба аргумента одинаковые
XOR (0, 0) = 0
XOR (1, 1) = 0
Предположим что у нас есть 3 диска со следующими битами
| 101 | 010 | 011 |
| 1 | 2 | 3 |
И мы посчитаем XOR от этих данных и расположим его на 4 диске
XOR (101, 010, 011) = 100 (XOR (101,010) = 111 and then XOR (111, 011) = 100
Данные на 4 диске будут такие
| 101 | 010 | 011 | 100 |
| 1 | 2 | 3 | 4 |
Теперь посмотрим на магию XOR в действии. Предположим что 2 диск сломался. Когда мы посчитаем XOR от всех оставшихся данных то получим данные с потерянного диска
| 101 | 010 | 011 | 100 |
| 1 | X | 3 | 4 |
XOR (101, 011, 100) = 010 # получили данные потерянного диска
Можно проверить с любым другим диском. В итоге мы всегда получим потерянные данные
| 101 | 010 | 011 | 100 |
| 1 | 2 | X | 4 |
XOR (101, 010, 100) = 011
То что работает с 3 битами на 4 дисках будет работать на любом количестве бит и дисков. Реальный RAID 5 имеет наиболее общий размер страйпа в 64k (65536 * 8 = 524288 bits )
Также настоящий XOR engine будет работать с 524288 битами а не 3 как в примере. Это причина почему RAID 5 требует высокоэффективный XOR engine чтобы считать это все быстро
При добавлении нового диска нужно будет перестроить контрольную сумму или восстановить данные в случае если диск был добавлен для расширения а не замены
В это примере мы объяснили работу RAID 4 где контрольная сумма хостится на отдельном диске. RAID 5 распределяет контрольную сумму по всем дискам. Распределенный хэш дает легкий прирост производительности но магия XOR там та же самая
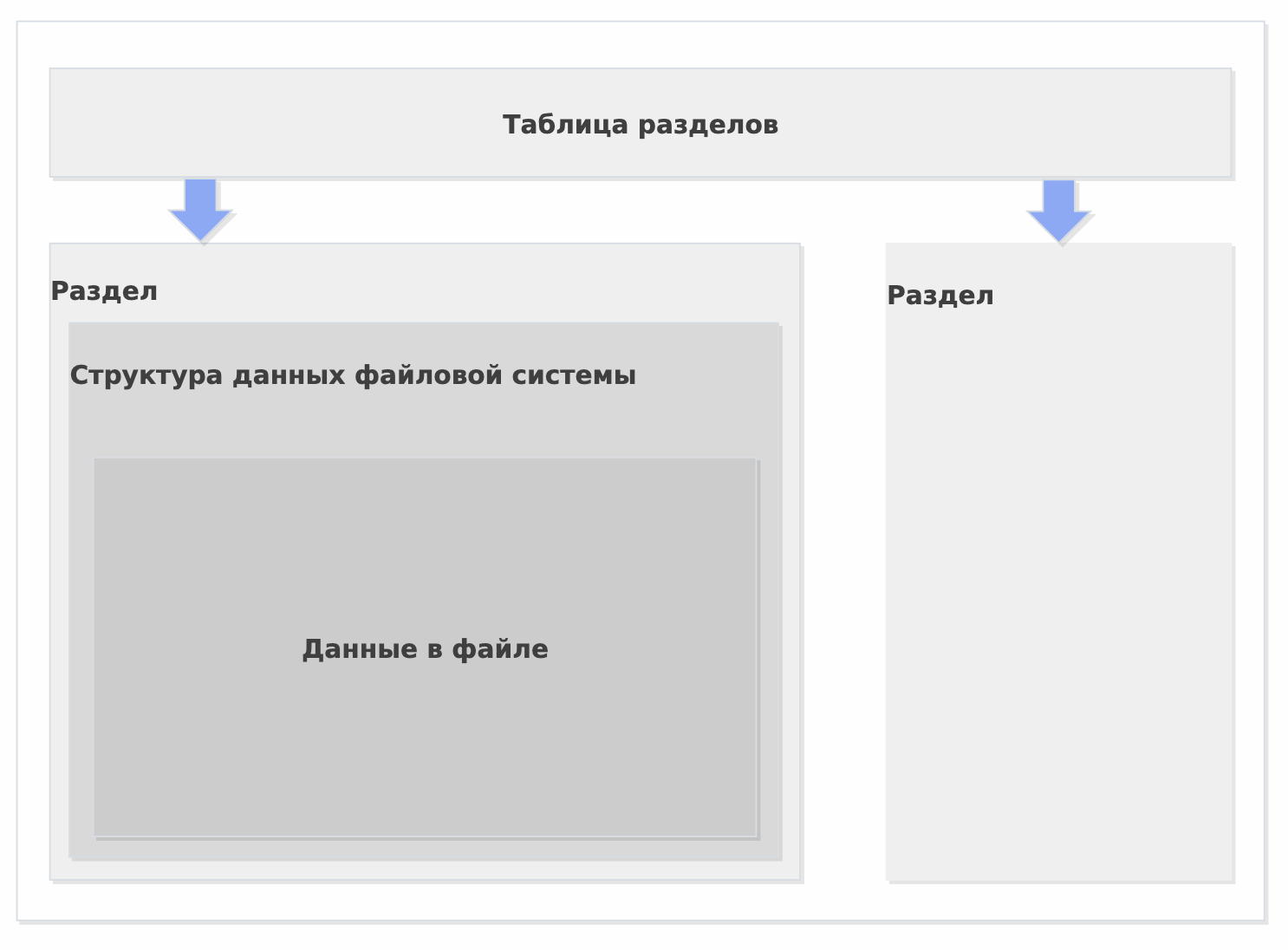
Таблицы разделов
MBR
Таблица разделов - логически выделенная часть жесткого диска фиксированного размера видимая ОС как отдельное блочное устройство
- Физически информация о разделах находится на жестком диске в разных местах в зависимости от типа таблицы
- Мы будем рассматривать MBR (Master Boot Record) и GPT (Guide Partition Table)
Преимущества:
- Самый популярный и совместимый
Недостатки:
- Максимум 4 первичных раздела на диске
- Если первые сектора диска повреждены, диск перестает читаться
- Максимальный раздел — 2.2 Tb
Занимает 512 байт
| Смещение | Длина | Описание |
|---|---|---|
| 000h | 446 | Код загрузчика |
| 1BEh | 64 | Таблица разделов |
| 16 | Раздел 1 | |
| 1CEh | 16 | Раздел 2 |
| 1DEh | 16 | Раздел 3 |
| 1EEh | 16 | Раздел 4 |
| 1FEh | 2 | Сигнатура (55h AAh) |
16 байтный блок раздела:
| Смещение | Длина | Описание |
|---|---|---|
| 00h | 1 | Признак активности раздела |
| 01h | 1 | Начало раздела - головка |
| 02h | 1 | Начало раздела - сектор (биты 0-5), дорожка (биты 6,7) |
| 03h | 1 | Начало раздела - дорожка (старшие биты 8,9 хранятся в байте номера сектора) |
| 04h | 1 | Код типа раздела |
| 05h | 1 | Конец раздела - головка |
| 06h | 1 | Конец раздела - сектор (биты 0-5), дорожка (биты 6,7) |
| 07h | 1 | Конец раздела - дорожка (старшие биты 8,9 хранятся в байте номера сектора) |
| 08h | 4 | Смещение первого сектора |
| 0Ch | 4 | Количество секторов раздела |
GPT / GUID
Преимущества:
- Неограниченное кол-во разделов
- Очень большие ограничения на объем
- Раздел зарезервирован, хранятся контрольные CRC-суммы, в случае проблем возможно восстановление
Недостатки:
- Не поддерживается старыми системами

mdadm
Состоит из:
- Утилита управления -
mdadm - Модули ядра
- Утилита мониторинга
Блочные устройства:
- разделы
- диски
- тома lvm
Метаданные:
- 0.9, 1.0 - конец устройства (необходимо для загрузки в некоторых случаях)
- 1.1 - начало
- 1.2 - 4К от начала устройства
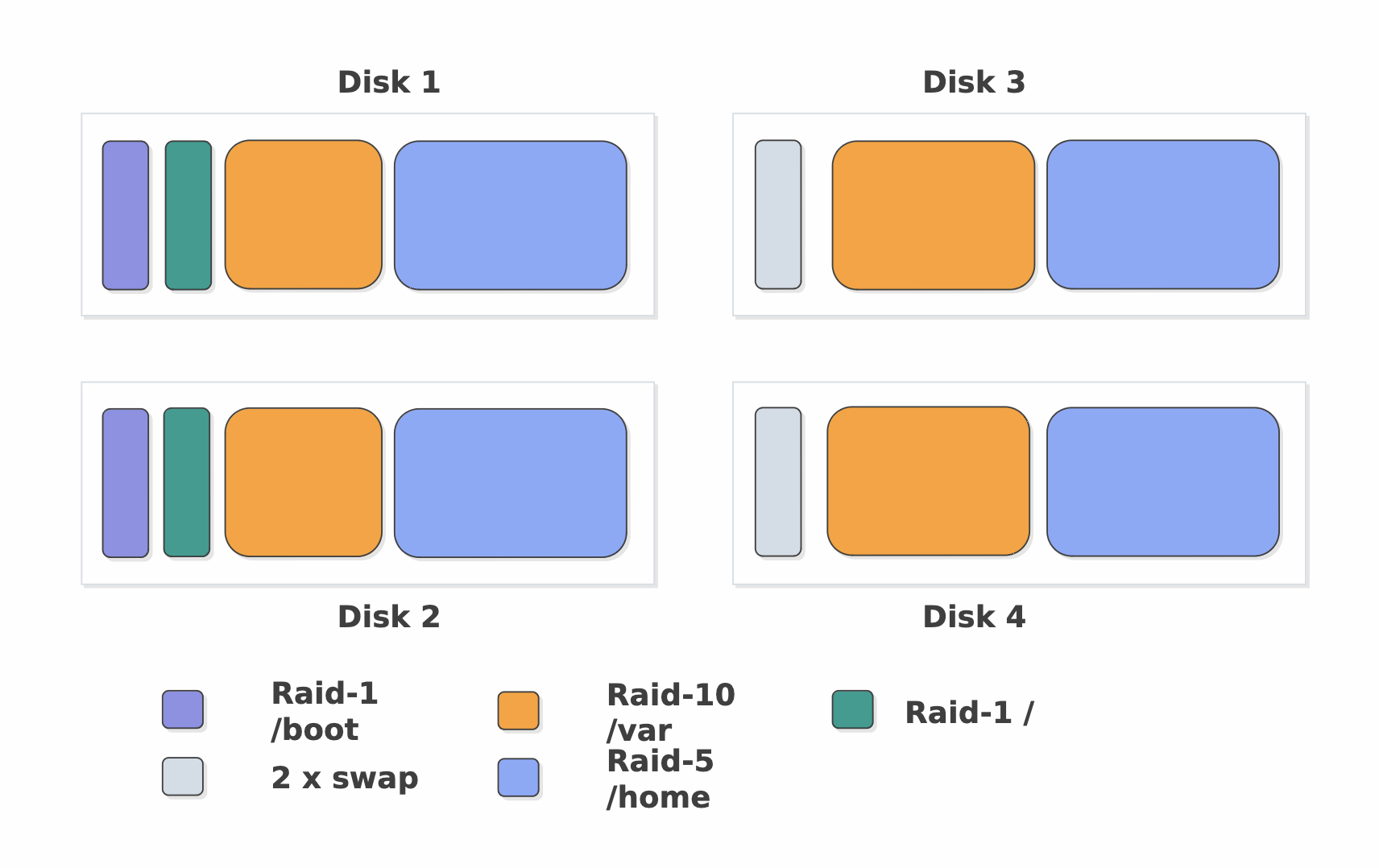
Массивы mdraid можно создавать из любых блочных устройств:
- Дисков
- Разделов
- Томов lvm
Наиболее безопасно создавать RAID поверх разделов, это может помочь сгладить разный размер дисков, позволит на одном наборе дисков создать разные RAID