3. Администрирование сервера
https://postgrespro.ru/docs/postgresql/13/admin
- Установка из исходного кода
- Подготовка к работе и сопровождение сервера
- Настройка сервера
- Аутентификация клиентского приложения
- Роли базы данных
- Управление базами данных
- Локализация
- Регламентные задачи обслуживания базы данных
- Резервное копирование и восстановление
- Отказоустойчивость, балансировка нагрузки и репликация
- Мониторинг работы СУБД
Установка из исходного кода
https://www.postgresql.org/ftp/source/
./configure
make
su
make install
adduser postgres
mkdir /usr/local/pgsql/data
chown postgres /usr/local/pgsql/data
su - postgres
/usr/local/pgsql/bin/initdb -D /usr/local/pgsql/data
/usr/local/pgsql/bin/pg_ctl -D /usr/local/pgsql/data -l logfile start
/usr/local/pgsql/bin/createdb test
/usr/local/pgsql/bin/psql test
Все файлы по умолчанию устанавливаются в подкаталоги каталога /usr/local/pgsql
При конфигурировании (выполнение configure) можно указать множество разных параметров, например путь установки (--prefix)
./configure --help - содержит исчерпывающий список параметров конфигурирования
С помощью параметров конфигурирования можно вынести подкаталоги prefix'a в другие места
Помимо параметров можно использовать переменные окружения
Подготовка к работе и сопровождение сервера
PostgreSQL рекомендуется запускать под отдельным пользователем
Рекомендуется не назначать этого пользователя владельцем исполняемых файлов PostgreSQL, чтобы их нельзя было подменить в случае компрометации серверного процесса
При установке из пакетов пользователь добавится автоматически
При установке из исходников нужно создать руками
Прежде чем начать работать с базами данных нужно проинициализировать область хранения данных на диске
Это хранилище называется кластером баз данных
Кластер представляет собой набор баз данных управляемых одним экземпляром сервера
После инициализации в кластере создается база postgres, сам постгрес может жить и без нее, но на ее существование расчитывают внешние вспомогательные программы
Также создается база template1, она используется в качестве шаблона для создаваемых баз данных
С точки зрения файловой системы кластер баз данных представляет собой один каталог, в котором будут храниться все данные
Какого-либо стандартного пути не существует, но часто данные размещаются в /usr/local/pgsql/data или в /var/lib/pgsql/data
Для создания кластера (для инициализации области хранения данных) нужно воспользоваться командой initdb и передать ей через ключ -D желаемый путь
Команду нужно выполнять от имени пользователя postgres (ну или какой там у вас)
Вместо ключа -D можно установить переменную окружения PGDATA
А еще можно это сделать через pg_ctl:
pg_ctl -D /usr/local/pgsql/data initdb
Команда initdb не будет работать, если указанный каталог данных уже существует и содержит файлы; это мера предохранения от случайной перезаписи существующей инсталляции
Команда initdb также устанавливает локаль для кластера
Локаль это важно. Отличные от "C" и "POSIX" локали могут негативно влиять на производительность
Также в момент инициализации устанавливается кодировка для всего кластера
Локаль влияет на порядок сортировки, а порядок сортировки влияет на порядок ключей в индексах. Поэтому какую-то суперкастомную установку будет очень сложно перенести
Если делать кластер баз данных на отдельном разделе, то не следует выбирать в качестве каталога данных саму точку монтирования, лучше внутри монтируемой ФС сделать каталог который пренадлежит пользователю postgres, а внутри этого каталога диру для данных
Это исключит некоторые проблемы
Как показывает практика, смена ФС или смена параметров ФС обычно не влияет на производительность постгреса
Запустить постгрес можно разными способами
С помощью команды postgres, передав ей путь до кластера баз данных через ключ -D: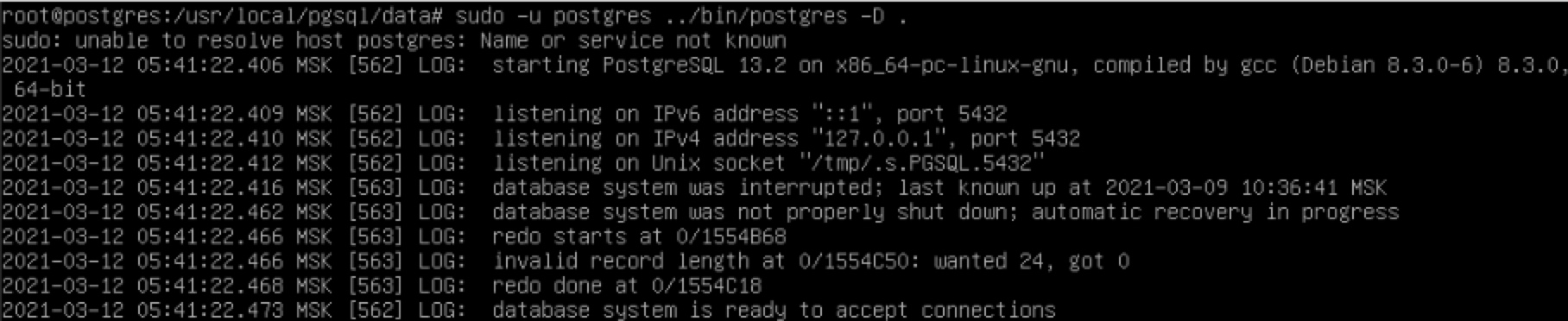
А можно передать через переменную окружения PGDATA:
Два описанных выше способа запустят постгрес на переднем плане, можно перенаправить вывод в логфайл и добавить амперсанд в конце команды
Будет почти норм, но это отстой
Эти способы можно использовать для аудита/диагностики
По-человечески запускать постгрес следует, например, так:
Можно написать systemd unit, но для некоторых функций systemd требуется чтобы постгрес был скомпилирован с опцией --with-systemd
Запущенный постгрес создает файл postmaster.pid в каталоге кластера
Это нужно для защиты от запуска нескольких экземпляров с одним каталогом данных
Также это может быть полезно для выключения экземпляра (облегчает поиск pid'a)
Нужно чтобы пользователь от которого запускается постгрес был системным (это задается при создании пользователя, например useradd -r ...)
Либо нужно указать параметр RemoveIPC=no в /etc/systemd/logind.conf
Иначе сервер будет не стабильным потому что ОС будет высвобождать разделяемые ресурсы преждевременно и данные могут теряться
Остановить постгрес можно послав сигнал postmaster'у
- SIGTERM - graceful shutdown
- SIGINT - запрещает новые коннекты и шлет SIGTERM старым коннектам
- SIGQUIT - гасит все жестко
Для выключения сервера не следует использовать сигнал SIGKILL. При таком выключении сервер не сможет освободить разделяемую память и семафоры. Кроме того, при уничтожении главного процесса postgres сигналом SIGKILL, он не успеет передать этот сигнал своим дочерним процессам, так что может потребоваться завершать и их вручную
Чтобы завершить отдельный сеанс, не прерывая работу других сеансов, воспользуйтесь функцией pg_terminate_backend() или отправьте сигнал SIGTERM дочернему процессу, обслуживающему этот сеанс
Номер версии постгреса состоит из двух чисел (до версии 10 было три числа) - например 10.1
- 10 - Первое число означает основную версию
- 1 - Второе означает номер корректирующей версии
Все корректирующие версии в рамках одной основной версии - совместимы
До 10 версии номер основной версии обозначало два первых числа, а третье обозначало корректирующую
Для обновления совместимых версий достаточно просто заменить исполняемые файлы при выключенном постгресе
Каталог данных при этом не затрагивается
При обновлении основных версий может затрагиваться каталог данных
Традиционный способ обновления - сделать дамп из старого постгреса и залить его в новый, но это может занять очень много времени
Утилита pg_upgrade позволит провести обновление на месте и быстрее
Еще можно поднять два экземпляра в разных кластерах и на разных портах и запустить переливку данных из старой версии в новую
pg_dumpall -p 5432 | psql -d postgres -p 5433
Для создания копии рекомендуется использовать актуальные версии утилиты pg_dump/pg_dumpall
Соврeменнные версии способны читать данные постгреса начиная с 7 версии
Еще можно настроить репликацию из старого постгреса в новый, а потом переключить мастера на новый постгрес
Любой пользователь в системе может запустить свой постгрес и слушать аутентификационные данные клиентов
Чтобы защититься от поддельного сервера, можно использовать unix-socket в специальном каталоге в который может писать только проверенный пользователь
Также можно защитить клиентов передав им параметр requirepeer, в котором указывается имя владельца серверного процесса (так можно обезопасить локальные подключения)
Шифрование
- Пароли пользователей хранятся в виде хэшей. SCRAM/MD5, scram - предпочтительнее
Но нужно учитывать что старые клиенты могут не уметь в scram - С помощью модуля pgcrypto можно шифровать отдельные поля таблицы
- Можно зашифровать каталог данных (если он монтируется отдельно)
- Можно настроить ssl для подключений
Можно использовать ipsec-туннели
Можно использовать ssh - Можно настроить проверку подлинности ssh, тогда можно будет избежать MITM
- А еще можно шифровать данные на клиенте и складывать в базу уже зашифрованные
Чтобы работал ssl, нужно чтобы он был включен при сборке (./configure --with-openssl)
По умолчанию когда включаешь в конфиге ssl=on, сервер будет согласовывать использование ssl с каждым клиентом индивидуально (ssl и non-ssl подключения будут работать на одном и том же порту)
Но можно и настроить индивидуальные параметры, например у какого-то клиента строго принимать только по ssl, итд
Если установил из репозитория то посмотреть с какими ключами он был собран можно так:
root@two:~# pg_config --configure
'--build=x86_64-linux-gnu' '--prefix=/usr' '--includedir=${prefix}/include'...
Нужно быть внимательным с правами на ключи. Возможны ситуации когда у нас есть отдельный пользователь для бэкапов, который имеет права на каталог с базой, и если мы храним ключи в этом же каталоге, то они в опасности
Если закрытый ключ защищен паролем то постгрес не запустится пока не будет введен пароль
Postgres пользуется openssl. Алгоритмы и шифры можно задавать в конфиге постгреса
Сделать самоподписанные серты для защищенного подключения в postgres можно опираясь на эту страницу: CA,CSR,CRT
Но есть нюанс при выпуске клиентского серта
Поле CN должно содержать имя пользователя под которым будет производиться подключение
root@three:~# openssl x509 -in client.crt -noout -subject
subject=CN = test
ssl = on
ssl_ca_file = '/etc/ssl/certs/server-ca.crt' # в этот файл можно включить всю цепочку
ssl_cert_file = '/etc/ssl/certs/server.crt'
ssl_key_file = '/etc/ssl/private/server.key'
root@two:/etc/ssl# cp ~/server-ca.crt certs/.
root@two:/etc/ssl# cp ~/server.crt certs/.
root@two:/etc/ssl# cp ~/server.key private/.
root@two:/etc/postgresql/13/main# tail -1 pg_hba.conf
hostssl all all 0.0.0.0/0 cert
postgres=# create database testdb;
CREATE DATABASE
postgres=# create user test;
CREATE ROLE
postgres=# grant all privileges on database testdb to test;
GRANT
postgres=#
root@three:~# psql "host=two.vandud.ru user=test dbname=testdb sslmode=verify-full sslrootcert=/root/server-ca.crt sslcert=/root/client.crt sslkey=/root/client.key"
psql (13.2 (Debian 13.2-1.pgdg100+1))
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
Type "help" for help.
testdb=> \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
testdb | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/postgres +
| | | | | postgres=CTc/postgres+
| | | | | test=CTc/postgres
(4 rows)
testdb=>
Чтобы не вводить длинную команду для подключения
Ее содержимое можно засунуть в ~/.pg_service.conf и ссылаться на содержимое файла через параметр service
root@three:~# cat .pg_service.conf
[test]
host=two.vandud.ru
user=test
dbname=testdb
sslmode=verify-full
sslrootcert=/root/server-ca.crt
sslcert=/root/client.crt
sslkey=/root/client.key
root@three:~# psql "service=test"
psql (13.2 (Debian 13.2-1.pgdg100+1))
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
Type "help" for help.
testdb=>
При работе с сертификатами постгрес может проверять CRL
Для этого в postgres.conf нужно указать путь до файла с CRL в ssl_crl_file
Сервер не примет файл ключа с либеральными правами
Если клиент не поддерживает ssl, то можно использовать ssh
Можно прокинуть туннель и работать через него
ssh -L 63333:localhost:5432 joe@foo.com
psql -h localhost -p 63333 postgres
Настройка сервера
Пока просто прочитал
Нужно перечитать и выписать важное
https://postgrespro.ru/docs/postgresql/14/runtime-config
Аутентификация клиентского приложения
Имена пользователей базы данных PostgreSQL не имеют прямой связи с пользователями операционной системы на которой запущен сервер. Если у всех пользователей базы данных заведена учётная запись в операционной системе сервера, то имеет смысл назначить им точно такие же имена для входа в PostgreSQL. Однако сервер, принимающий удалённые подключения, может иметь большое количество пользователей базы данных, у которых нет учётной записи в ОС. В таких случаях не требуется соответствие между именами пользователей базы данных и именами пользователей операционной системы
Файл pg_hba.conf расположен в каталоге с данными кластера базы данных (HBA расшифровывается как host-based authentication — аутентификации по имени узла)
Он конфигурируется по записе на строку. Запись может быть продолжена на следующей строке, для этого нужно завершить строку обратной косой чертой (Обратная косая черта является спецсимволом только в конце строки)
Первая запись с соответствующим типом соединения, адресом клиента, указанной базой данных и именем пользователя применяется для аутентификации. Процедур «fall-through» или «backup» не предусмотрено: если выбрана запись и аутентификация не прошла, последующие записи не рассматриваются. Если же ни одна из записей не подошла, в доступе будет отказано
Записи могут иметь следующие форматы:
local база пользователь метод-аутентификации [параметры-аутентификации]
host база пользователь адрес метод-аутентификации [параметры-аутентификации]
hostssl база пользователь адрес метод-аутентификации [параметры-аутентификации]
hostnossl база пользователь адрес метод-аутентификации [параметры-аутентификации]
hostgssenc база пользователь адрес метод-аутентификации [параметры-аутентификации]
hostnogssenc база пользователь адрес метод-аутентификации [параметры-аутентификации]
host база пользователь IP-адрес IP-маска метод-аутентификации [параметры-аутентификации]
hostssl база пользователь IP-адрес IP-маска метод-аутентификации [параметры-аутентификации]
hostnossl база пользователь IP-адрес IP-маска метод-аутентификации [параметры-аутентификации]
hostgssenc база пользователь IP-адрес IP-маска метод-аутентификации [параметры-аутентификации]
hostnogssenc база пользователь IP-адрес IP-маска метод-аутентификации [параметры-аутентификации]
- local - Управляет подключениями через Unix-сокеты. Без подобной записи подключения через Unix-сокеты невозможны
- host - Управляет подключениями, устанавливаемыми по TCP/IP
Эту разницу видно на скриншоте ниже (когда указываем-h localhostто подключаемся по tcp и постгрес запрашивает пароль, а когда не указываем то подключаемся через сокет и пароль не запрашивается потому что в pg_hba есть соответствующая запись)

В столбце с именем базы данных можно указать несколько имен, разделяя их запятыми. Также можно задать отдельный файл с именами баз данных, написав имя файла после знака @ (аналогично с именами пользователей)
Значение all определяет, что подходят все базы данных. Значение sameuser определяет, что данная запись соответствует, только если имя запрашиваемой базы данных совпадает с именем запрашиваемого пользователя. Значение samerole определяет, что запрашиваемый пользователь должен быть членом роли с таким же именем, как и у запрашиваемой базы данных
Значение replication показывает, что запись соответствует, когда запрашивается подключение для физической репликации, но не когда запрашивается подключение для логической. Имейте в виду, что для подключений физической репликации не указывается какая-то конкретная база данных, в то время как для подключений логической репликации должна указываться конкретная база
В поле адреса биты, находящиеся правее границы маски, в указанном IP-адресе должны быть нулевыми
Валидные примеры: 172.20.143.89/32, 172.20.143.0/24
Файл pg_hba.conf прочитывается при запуске системы, а также в тот момент, когда основной сервер получает сигнал SIGHUP. Если вы редактируете файл во время работы системы, необходимо послать сигнал процессу postmaster (используя pg_ctl reload, вызвав SQL-функцию pg_reload_conf() или выполнив kill -HUP), чтобы он прочел обновлённый файл
Системное представление pg_hba_file_rules может быть полезно для предварительной проверки изменений в файле pg_hba.conf или для диагностики проблем, когда перезагрузка этого файла не даёт желаемого эффекта. Строки в этом представлении, содержащие в поле error не NULL, указывают на проблемы в соответствующих строках файла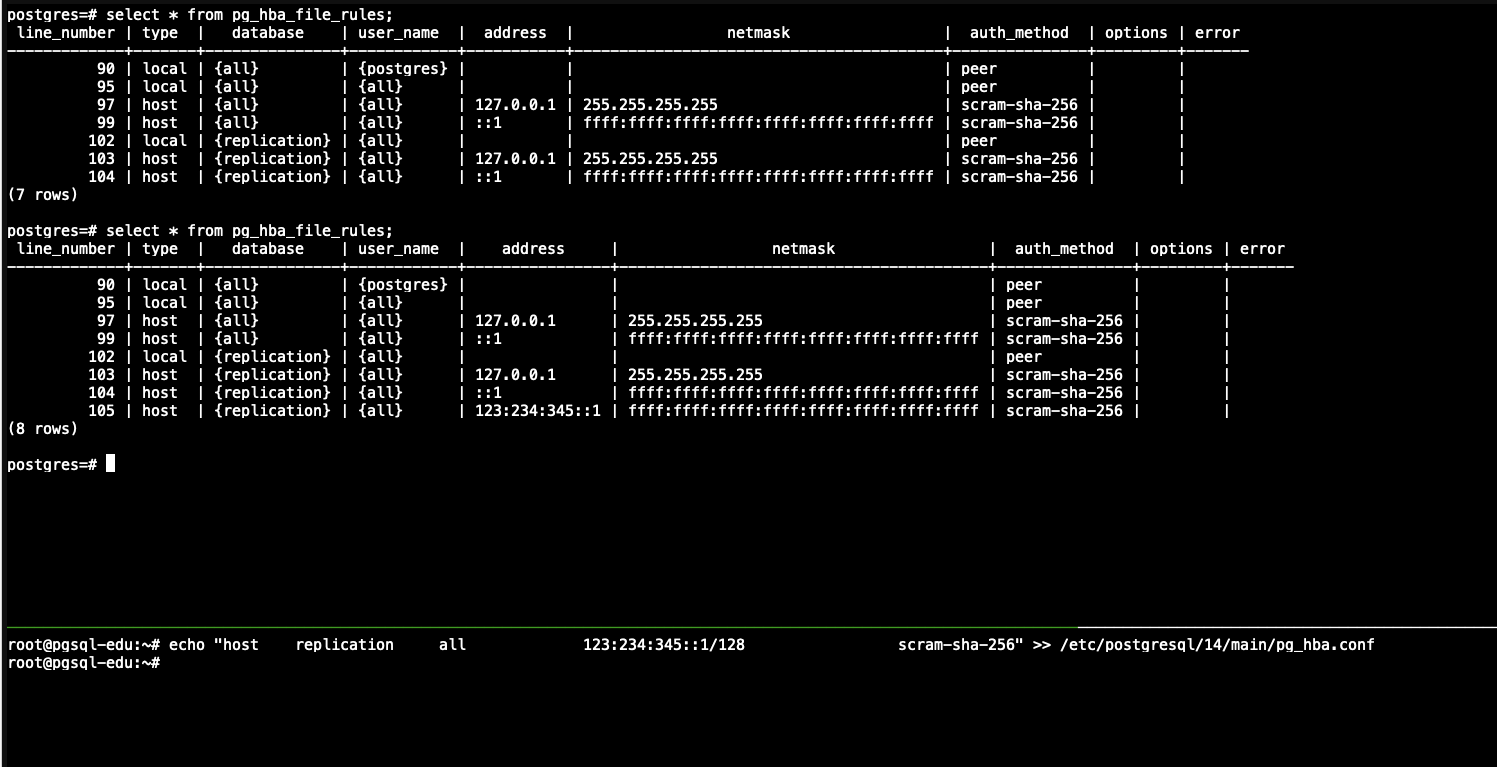
Кстати изменения из файла pg_hba.conf подсасываются автоматически в таблицу в таблицу pg_hba_file_rules, но не применяются, чтобы они применились надо релоадить
Файл pg_hba.conf прочитывается при запуске системы, а также в тот момент, когда основной сервер получает сигнал SIGHUP. Если вы редактируете файл во время работы системы, необходимо послать сигнал процессу postmaster (используя pg_ctl reload, вызвав SQL-функцию pg_reload_conf() или выполнив kill -HUP), чтобы он прочел обновлённый файл
Когда используется внешняя система аутентификации, например Ident или GSSAPI, имя пользователя операционной системы, устанавливающего подключение, может не совпадать с именем целевого пользователя (роли) базы данных. В этом случае можно применить сопоставление имён пользователей, чтобы сменить имя пользователя операционной системы на имя пользователя БД. Чтобы задействовать сопоставление имён, укажите map=имя-сопоставления в поле параметров в pg_hba.conf
Сопоставления имён пользователя определяются в файле сопоставления ident, который по умолчанию называется pg_ident.conf и хранится в каталоге данных кластера
Формат файла такой: map-name system-username database-username
map-name является произвольным именем, на которое будет ссылаться файл сопоставления файла pg_hba.conf. Два других поля указывают имя пользователя операционной системы и соответствующее имя пользователя базы данных
Записи в файле подразумевают, что «пользователь этой операционной системы может подключиться как пользователь этой базы данных»
Если поле system-username начинается со знака (/), оставшаяся его часть рассматривается как регулярное выражение. Регулярное выражение может включать в себя одну группу, или заключённое в скобки подвыражение, на которое можно сослаться в поле database-username, написав \1 (с одной обратной косой). Это позволяет сопоставить несколько имён пользователя с одной строкой, что особенно удобно для простых замен. Например, эти строки:
mymap /^(.*)@mydomain\.com$ \1
mymap /^(.*)@otherdomain\.com$ guest
удалят часть домена для имён пользователей, которые заканчиваются на @mydomain.com, и позволят пользователям, чьё имя пользователя системы заканчивается на @otherdomain.com, подключиться как guest
Файл pg_ident.conf прочитывается при запуске системы, а также в тот момент, когда основной сервер получает сигнал SIGHUP. Если вы редактируете файл во время работы системы, необходимо послать сигнал процессу postmaster (используя pg_ctl reload, вызвав SQL-функцию pg_reload_conf() или выполнив kill -HUP), чтобы он прочел обновлённый файл
authentication option "map" is only valid for authentication methods ident, peer, gssapi, sspi, and cert
Пароли всех пользователей базы данных хранятся в системном каталоге pg_authid. Управлять паролями можно либо используя SQL-команды CREATE ROLE и ALTER ROLE, например, CREATE ROLE foo WITH LOGIN PASSWORD 'secret', либо с помощью команды psql \password. Если пароль для пользователя не задан, вместо него хранится NULL, и пройти аутентификацию по паролю этот пользователь не сможет
Метод аутентификации peer работает, получая имя пользователя операционной системы клиента из ядра и используя его в качестве разрешённого имени пользователя базы данных (с возможностью сопоставления имён пользователя). Этот метод поддерживается только для локальных подключений (например sudo -u postgres psql работает именно так)
При аутентификации через сертификат пароль у клиента не запрашивается. Атрибут cn (Обычное имя) сертификата сравнивается с запрашиваемым именем пользователя базы данных, и если они соответствуют, вход разрешается. Если cn отличается от имени пользователя базы данных, то может быть использовано сопоставление имён пользователей через pg_ident
Роли базы данных
PostgreSQL использует концепцию ролей (roles) для управления разрешениями на доступ к базе данных. Роль можно рассматривать как пользователя базы данных или как группу пользователей, в зависимости от того, как роль настроена. Роли могут владеть объектами базы данных (например, таблицами и функциями) и выдавать другим ролям разрешения на доступ к этим объектам, управляя тем, кто имеет доступ и к каким объектам. Кроме того, можно предоставить одной роли членство в другой роли, таким образом одна роль может использовать права других ролей
Концепция ролей включает в себя концепцию пользователей («users») и групп («groups»). До версии 8.1 в PostgreSQL пользователи и группы были отдельными сущностями, но теперь есть только роли. Любая роль может использоваться в качестве пользователя, группы, и того и другого
Роли базы данных концептуально полностью отличаются от пользователей операционной системы. На практике поддержание соответствия между ними может быть удобным, но не является обязательным. Роли базы данных являются глобальными для всей установки кластера базы данных (не для отдельной базы данных)
Идущие в комплекте программы createuser/dropuser являются обертками нам запросами CREATE ROLE имя;/DROP ROLE имя;
Для получения списка существующих ролей, рассмотрите pg_roles системного каталога
Метакоманда \du программы psql также полезна для получения списка существующих ролей
Для начальной настройки кластера базы данных, система сразу после инициализации всегда содержит одну предопределённую роль. Эта роль является суперпользователем («superuser») и по умолчанию (если не изменено при запуске initdb) имеет такое же имя, как и пользователь операционной системы, инициализирующий кластер баз данных. Обычно эта роль называется postgres. Для создания других ролей, вначале нужно подключиться с этой ролью
Роль базы данных может иметь атрибуты, определяющие её полномочия и взаимодействие с системой аутентификации клиентов:
- Право подключения - Только роли с атрибутом LOGIN могут использоваться для начального подключения к базе данных. Роль с атрибутом LOGIN можно рассматривать как пользователя базы данных. Для создания такой роли можно использовать любой из вариантов:
(Команда CREATE USER эквивалентна CREATE ROLE за исключением того, что CREATE USER по умолчанию включает атрибут LOGIN, в то время как CREATE ROLE — нет)CREATE ROLE имя LOGIN; CREATE USER имя; - Статус суперпользователя - Суперпользователь базы данных обходит все проверки прав доступа, за исключением права на вход в систему. Это опасная привилегия и она не должна использоваться небрежно
- Создание базы данных - Роль должна явно иметь разрешение на создание базы данных (за исключением суперпользователей, которые пропускают все проверки)
- Создание роли - Роль должна явно иметь разрешение на создание других ролей (за исключением суперпользователей, которые пропускают все проверки). Роль с правом CREATEROLE может не только создавать, но и изменять и удалять другие роли, а также выдавать и отзывать членство в ролях. Однако для создания, изменения, удаления ролей суперпользователей и изменения членства в них требуется иметь статус суперпользователя; права CREATEROLE в таких случаях недостаточно
- Запуск репликации - Роль должна иметь явное разрешение на запуск потоковой репликации (за исключением суперпользователей, которые пропускают все проверки). Роль, используемая для потоковой репликации, также должна иметь атрибут LOGIN
- Пароль - Пароль имеет значение, если метод аутентификации клиентов требует, чтобы пользователи предоставляли пароль при подключении к базе данных
Атрибуты ролей могут быть изменены после создания командой ALTER ROLE
Для настройки групповой роли сначала нужно создать саму роль:
CREATE ROLE имя;
Обычно групповая роль не имеет атрибута LOGIN, хотя при желании его можно установить
После того как групповая роль создана, в неё можно добавлять или удалять членов, используя команды GRANT и REVOKE:
GRANT групповая_роль TO роль1, ... ;
REVOKE групповая_роль FROM роль1, ... ;
Членом роли может быть и другая групповая роль (потому что в действительности нет никаких различий между групповыми и не групповыми ролями). При этом база данных не допускает замыкания членства по кругу. Также не допускается управление членством роли PUBLIC в других ролях
У роли есть аттрибут INHERIT/NOINHERIT, он указывает на то наследует ли эта роль аттрибуты от родительской роли (в том числе права унаследованные родителем от родителя)
Например:
joe (inherit) -> admin (noinherit) -> wheel (noinherit)
Здесь joe унаследует права от admin, но не от wheel, потому что admin не наследует права от wheel
Но при этом joe может сделать set role wheel и стать ролью wheel со всеми ее правами потому что для переключения на роль достаточно и косвенного членства в ней
Так как роли могут владеть объектами баз данных и иметь права доступа к объектам других, удаление роли не сводится к немедленному действию DROP ROLE. Сначала должны быть удалены и переданы другим владельцами все объекты, принадлежащие роли; также должны быть отозваны все права, данные роли
При попытке выполнить DROP ROLE для роли, у которой сохраняются зависимые объекты, будут выданы сообщения, говорящие, какие объекты нужно передать другому владельцу или удалить
В PostgreSQL имеется набор предопределённых ролей, которые дают доступ к некоторым часто востребованным, но не общедоступным функциям и данным
Подробнее о них https://postgrespro.ru/docs/postgresql/14/predefined-roles
postgres=> select * from pg_roles where rolname like 'pg%';
rolname | rolsuper | rolinherit | rolcreaterole | rolcreatedb | rolcanlogin | rolreplication | rolconnlimit | rolpassword | rolvaliduntil | rolbypassrls | rolconfig | oid
---------------------------+----------+------------+---------------+-------------+-------------+----------------+--------------+-------------+---------------+--------------+-----------+------
pg_database_owner | f | t | f | f | f | f | -1 | ******** | | f | | 6171
pg_read_all_data | f | t | f | f | f | f | -1 | ******** | | f | | 6181
pg_write_all_data | f | t | f | f | f | f | -1 | ******** | | f | | 6182
pg_monitor | f | t | f | f | f | f | -1 | ******** | | f | | 3373
pg_read_all_settings | f | t | f | f | f | f | -1 | ******** | | f | | 3374
pg_read_all_stats | f | t | f | f | f | f | -1 | ******** | | f | | 3375
pg_stat_scan_tables | f | t | f | f | f | f | -1 | ******** | | f | | 3377
pg_read_server_files | f | t | f | f | f | f | -1 | ******** | | f | | 4569
pg_write_server_files | f | t | f | f | f | f | -1 | ******** | | f | | 4570
pg_execute_server_program | f | t | f | f | f | f | -1 | ******** | | f | | 4571
pg_signal_backend | f | t | f | f | f | f | -1 | ******** | | f | | 4200
(11 rows)
Управление базами данных
База данных создаётся SQL-командой CREATE DATABASE. Текущий пользователь автоматически назначается владельцем
Для выполнения команды CREATE DATABASE необходимо подключение к серверу базы данных (при установлении подключения обязательно задается база к которой происходит подключение, поэтому к postgres'у без баз подключиться не выйдет). Первая база данных всегда создаётся командой initdb при инициализации пространства хранения данных. Эта база данных называется postgres
Вторая база данных template1, также создаётся во время инициализации кластера. При каждом создании новой базы данных в рамках кластера по факту производится клонирование шаблона template1. При этом любые изменения сделанные в template1 распространяются на все созданные впоследствии базы данных (то есть изменения в шаблоне отразятся на создаваемых в будущем из этого шаблона базах данных)
Для удобства, есть утилита командной строки для создания баз данных - createdb. Она просто подключается к базе данных postgres и выполняет CREATE DATABASE. Без параметров она создаст базу данных с именем текущего пользователя
Иногда необходимо создать базу данных для другого пользователя и назначить его владельцем, чтобы он мог конфигурировать и управлять ею:
CREATE DATABASE имя_базы OWNER имя_роли;
Лишь суперпользователь может создавать базы данных для других (для ролей, членом которых он не является)
Также существует вторая системная база template0. При инициализации она содержит те же самые объекты, что и template1 (В template0 не следует вносить никакие изменения после инициализации кластера)
Если в команде CREATE DATABASE указать в качестве шаблона template0 вместо template1, вы сможете получить «чистую» пользовательскую базу данных, не содержащую ничего, что могло быть добавлено на месте в template1
Для создания базы данных на основе template0, используйте:
CREATE DATABASE dbname TEMPLATE template0;
Можно создавать дополнительные шаблоны баз данных, и, более того, можно копировать любую базу данных кластера, если указать её имя в качестве шаблона в команде CREATE DATABASE
В таблице pg_database есть два полезных флага для каждой базы данных - столбцы datistemplate и datallowconn:
-
datistemplateуказывает на факт того, что база данных может выступать в качестве шаблона в командеCREATE DATABASE. Если флаг установлен, то для пользователей с правомCREATEDBклонирование доступно; если флаг не установлен, то лишь суперпользователь и владелец базы данных могут её клонировать -
datallowconnуказывает на возможность подключаться к этой базе данных (однако текущие сессии не закрываются при сбросе этого флага). Базаtemplate0обычно помечена какdatallowconn = falseдля избежания любых её модификаций. Иtemplate0, иtemplate1всегда должны быть помечены флагомdatistemplate = true
testdb=# select datname,datistemplate,datallowconn from pg_database ;
datname | datistemplate | datallowconn
-----------+---------------+--------------
benchmark | f | t
template1 | t | t
template0 | t | f
postgres | f | t
testdb | f | t
testdb2 | f | t
(6 rows)
База данных postgres также создаётся при инициализации кластера. Она используется пользователями и приложениями для подключения по умолчанию. Представляет собой всего лишь копию template1, и может быть удалена и повторно создана при необходимости
В базе postgres действительно пусто)))
Для меня это было открытием, я думал что таблицы pg_* находятся внутри нее
You are now connected to database "postgres" as user "postgres".
postgres=# \dt ### Внутри пусто
Did not find any relations.
postgres=# \dn
List of schemas
Name | Owner
--------+----------
public | postgres
(1 row)
postgres=# \c testdb
You are now connected to database "testdb" as user "postgres".
testdb=# select * from pg_database; ### А таблицы pg_* доступны и внутри других баз
oid | datname | datdba | encoding | datcollate | datctype | datistemplate | datallowconn | datconnlimit | datlastsysoid | datfrozenxid | datminmxid | dattablespace | datacl
-------+-----------+--------+----------+------------+----------+---------------+--------------+--------------+---------------+--------------+------------+---------------+------------------------------------------------------------
16384 | benchmark | 10 | 0 | C | C | f | t | -1 | 13754 | 726 | 1 | 1663 |
1 | template1 | 10 | 0 | C | C | t | t | -1 | 13754 | 726 | 1 | 1663 | {=c/postgres,postgres=CTc/postgres}
13754 | template0 | 10 | 0 | C | C | t | f | -1 | 13754 | 726 | 1 | 1663 | {=c/postgres,postgres=CTc/postgres}
13755 | postgres | 10 | 0 | C | C | f | t | -1 | 13754 | 726 | 1 | 1663 | {=Tc/postgres,postgres=CTc/postgres,testuser=CTc/postgres}
16415 | testdb | 10 | 0 | C | C | f | t | -1 | 13754 | 726 | 1 | 1663 |
16419 | testdb2 | 10 | 0 | C | C | f | t | -1 | 13754 | 726 | 1 | 1663 |
(6 rows)
testdb=#
PostgreSQL имеет множество параметров конфигурации времени исполнения. Можно выставить специфичные для базы данных значения по умолчанию
Клиенты могут делать это, выполняя команду SET geqo TO off (geqo выбран как пример). Для того чтобы это действовало по умолчанию в конкретной базе данных, необходимо выполнить команду:
ALTER DATABASE mydb SET geqo TO off;
Установка сохраняется, но не применяется тотчас. В последующих подключениях к этой базе данных, эффект будет таким, будто перед началом сессии была выполнена команда SET geqo TO off;. Пользователь по-прежнему может изменять этот параметр во время сессии; ведь это просто значение по умолчанию. Чтобы сбросить такое установленное значение, используйте ALTER DATABASE dbname RESET varname
Базы данных удаляются командой DROP DATABASE. Лишь владелец базы данных или суперпользователь могут удалить базу. Удаление базы данных это необратимая операция
Невозможно выполнить команду DROP DATABASE пока существует хоть одно подключение к заданной базе. Однако можно подключиться к любой другой, в том числе и template1template1 может быть единственной возможностью при удалении последней пользовательской базы данных кластера
Также есть cli-утилита dropdb
Табличные пространства в PostgreSQL позволяют администраторам организовать логику размещения файлов объектов базы данных в файловой системе
Табличные пространства позволяют администратору управлять дисковым пространством для инсталляции PostgreSQL. Это полезно минимум по двум причинам:
- Во-первых, это нехватка места в разделе, на котором был инициализирован кластер и невозможность его расширения. Табличное пространство можно создать в другом разделе и использовать его до тех пор, пока не появится возможность переконфигурирования системы
- Во-вторых, табличные пространства позволяют администраторам оптимизировать производительность согласно бизнес-процессам, связанным с объектами базы данных. Например, часто используемый индекс можно разместить на очень быстром и надёжном, но дорогом SSD-диске. В то же время таблица с архивными данными, которые редко используются и скорость к доступа к ним не важна, может быть размещена в более дешёвом и медленном хранилище
Несмотря на внешнее размещение относительно основного каталога хранения данных PostgreSQL, табличные пространства являются неотъемлемой частью кластера и не могут трактоваться, как самостоятельная коллекция файлов данных. Они зависят от метаданных, расположенных в главном каталоге, и потому не могут быть подключены к другому кластеру, или копироваться по отдельности. Также, в случае потери табличного пространства (при удалении файлов, сбое диска и т. п.), кластер может оказаться недоступным или не сможет запуститься. Таким образом, при размещении табличного пространства во временной файловой системе, например, в RAM-диске, возникает угроза надёжности всего кластера
CREATE TABLESPACE для создания
CREATE TABLESPACE fastspace LOCATION '/mnt/tipasuperssd';
CREATE TABLE foo(i int) TABLESPACE fastspace;
Каталог должен существовать, быть пустым и принадлежать пользователю ОС, под которым запущен PostgreSQL. Все созданные впоследствии объекты, принадлежащие целевому табличному пространству, будут храниться в файлах расположенных в этом каталоге. Каталог не должен размещаться на съёмных или устройствах временного хранения, так как кластер может перестать функционировать из-за потери этого пространства
Создавать табличное пространство должен суперпользователь базы данных, но после этого можно разрешить обычным пользователям его использовать
Когда default_tablespace имеет значение отличное от пустой строки, он будет использоваться неявно в качестве значения параметра TABLESPACE в командах CREATE TABLE и CREATE INDEX, если в самой команде не задано иное
Табличное пространство, связанное с базой данных, также используется для хранения её системных каталогов. Более того, это табличное пространство используется по умолчанию для таблиц, индексов и временных файлов, создаваемых в базе данных, если не указано иное в выражении TABLESPACE, или переменной default_tablespace, или temp_tablespaces (соответственно). Если база данных создана без указания конкретного табличного пространства, то используется пространство, к которому принадлежит копируемый шаблон
При инициализации кластера автоматически создаются два табличных пространства:
-
pg_globalиспользуется для общих системных каталогов -
pg_defaultиспользуется по умолчанию для баз данных template1 и template0 (и соответственно наследуется на создаваемые из этих шаблонов новые базы (если эта настройка не переопределена))
Для удаления пустого табличного пространства используйте команду DROP TABLESPACE (сперва его надо опустошить и только потом удалять)
В pg_tablespaces хранится инфа о табличных пространствах, а также метакоманда \db пожет инфу о них
postgres=# select * from pg_tablespace;
oid | spcname | spcowner | spcacl | spcoptions
-------+------------+----------+--------+------------
1663 | pg_default | 10 | |
1664 | pg_global | 10 | |
16421 | fastspace | 10 | |
(3 rows)
postgres=# \db
List of tablespaces
Name | Owner | Location
------------+----------+-------------------
fastspace | postgres | /mnt/tipasuperssd
pg_default | postgres |
pg_global | postgres |
(3 rows)
PostgreSQL использует символические ссылки для упрощения реализации табличных пространств
Это означает, что табличные пространства могут использоваться только в системах, поддерживающих символические ссылки
Каталог $PGDATA/pg_tblspc содержит символические ссылки, которые указывают на внешние табличные пространства кластера
root@pgsql-edu:/var/lib/postgresql/14/main/pg_tblspc# ls -lha
total 8.0K
drwx------ 2 postgres postgres 4.0K Jan 8 04:37 .
drwx------ 19 postgres postgres 4.0K Jan 4 00:12 ..
lrwxrwxrwx 1 postgres postgres 17 Jan 8 04:37 16421 -> /mnt/tipasuperssd
root@pgsql-edu:/var/lib/postgresql/14/main/pg_tblspc#
Локализация
Локаль влияет на алфавит, порядок сортировки, форматирование чисел и т. пinitdb инициализирует кластер баз данных по умолчанию с локалью из окружения выполнения, если нужно использовать другую то можно передать аргумент в initdb
initdb --locale=ru_RU
Если в языковом окружении может использоваться более одного набора символов, значение может принимать вид language_territory.codeset. Например, fr_BE.UTF-8 обозначает французский язык (fr), на котором говорят в Бельгии (BE), с кодировкой UTF-8
Иногда целесообразно объединить правила из различных локалей, например, использовать английские правила сравнения и испанские сообщения. Для этой цели существует набор категорий локали, каждая из которых управляет только определёнными аспектами правил локализации:
| name | description |
|---|---|
| LC_COLLATE | Порядок сортировки строк |
| LC_CTYPE | Классификация символов (Что представляет собой буква? Каков её эквивалент в верхнем регистре?) |
| LC_MESSAGES | Язык сообщений |
| LC_MONETARY | Форматирование валютных сумм |
| LC_NUMERIC | Форматирование чисел |
| LC_TIME | Форматирование даты и времени |
Пример использования в initdb
initdb --locale=fr_CA --lc-monetary=en_US
LC_COLLATE и LC_CTYPE нельзя изменить после создания базы так как они влияют на порядок сортировки в индексах (иначе индексы на текстовых столбцах могут повредиться)
Если же клиент и сервер работают с разными локалями, то сообщения, возможно, будут появляться на разных языках в зависимости от того, где они возникают
Для того чтобы стал возможен перевод сообщений на язык, выбранный пользователем, NLS (National Language Support) должен быть выбран на момент сборки (configure --enable-nls)
Локаль влияет на следующий функционал SQL:
- Порядок сортировки в запросах с использованием
ORDER BYили стандартных операторах сравнения текстовых данных - Функции
upper,lower, иinitcap - Операторы поиска по шаблону (
LIKE,SIMILAR TO, и регулярные выражения в стиле POSIX) - Семейство функций
to_char - Возможность использовать индексы с предложениями
LIKE
Недостатком использования отличающихся от C или POSIX локалей в PostgreSQL является влияние на производительность. Это замедляет обработку символов и мешает LIKE использовать обычные индексы. По этой причине используйте локали только в том случае, если они действительно вам нужны
postgres=# select name, setting from pg_settings where name like 'lc_%';
name | setting
-------------+---------
lc_collate | C
lc_ctype | C
lc_messages | C
lc_monetary | C
lc_numeric | C
lc_time | C
(6 rows)
Правила сортировки позволяют устанавливать порядок сортировки и особенности классификации символов в отдельных столбцах или даже при выполнении отдельных операций. Это смягчает последствия того, что параметры базы данных LC_COLLATE и LC_CTYPE невозможно изменить после её создания
Про правила сортировки https://postgrespro.ru/docs/postgresql/14/collation
Еще одна страница которую я не понял https://postgrespro.ru/docs/postgresql/14/multibyte
Регламентные задачи обслуживания базы данных
Базы данных PostgreSQL требуют периодического проведения процедуры обслуживания, которая называется очисткой
Команды VACUUM в PostgreSQL должны обрабатывать каждую таблицу по следующим причинам:
- Для высвобождения или повторного использования дискового пространства, занятого изменёнными или удалёнными строками
- Для обновления статистики по данным, используемой планировщиком запросов PostgreSQL
- Для обновления карты видимости, которая ускоряет сканирование только индекса
- Для предотвращения потери очень старых данных из-за зацикливания идентификаторов транзакций или мультитранзакций
Разные причины диктуют выполнение действий VACUUM с разной частотой и в разном объёме
Существует два варианта VACUUM: обычный VACUUM и VACUUM FULL. Команда VACUUM FULL может высвободить больше дискового пространства, однако работает медленнее. Кроме того, обычная команда VACUUM может выполняться параллельно с использованием производственной базы данных. (При этом такие команды как SELECT, INSERT, UPDATE и DELETE будут выполняться нормально, хотя нельзя будет изменить определение таблицы командами типа ALTER TABLE). Команда VACUUM FULL требует блокировки обрабатываемой таблицы в режиме ACCESS EXCLUSIVE и поэтому не может выполняться параллельно с другими операциями с этой таблицей. По этой причине администраторы, как правило, должны стараться использовать обычную команду VACUUM и избегать VACUUM FULL
Команда VACUUM порождает существенный объём трафика ввода/вывода, который может стать причиной низкой производительности в других активных сеансах
В PostgreSQL команды UPDATE или DELETE не вызывают немедленного удаления старой версии изменяемых строк. Этот подход необходим для реализации эффективного многоверсионного управления конкурентным доступом версия строки не должна удаляться до тех пор, пока она остаётся потенциально видимой для других транзакций. Однако в конце концов устаревшая или удалённая версия строки оказывается не нужна ни одной из транзакций. После этого занимаемое ей место должно быть освобождено и может быть отдано новым строкам, во избежание неограниченного роста потребности в дисковом пространстве. Это происходит при выполнении команды VACUUM
-
VACUUMудаляет неиспользуемые версии строк в таблицах и индексах и помечает пространство свободным для дальнейшего использования. Однако это дисковое пространство не возвращается операционной системе, кроме особого случая, когда полностью освобождаются одна или несколько страниц в конце таблицы и можно легко получить исключительную блокировку таблицы -
VACUUM FULLнапротив, кардинально сжимает таблицы, записывая абсолютно новую версию файла таблицы без неиспользуемого пространства. Это минимизирует размер таблицы, однако может занять много времени
Обычно цель регулярной очистки — выполнять простую очистку (VACUUM) достаточно часто, чтобы не возникала необходимость в VACUUM FULL. Основная идея такого подхода не в том, чтобы минимизировать размер таблиц, а в том, чтобы поддерживать использование дискового пространства на стабильном уровне. Хотя с помощью VACUUM FULL можно сжать таблицу до минимума и возвратить дисковое пространство операционной системе, большого смысла в этом нет, если в будущем таблица так же вырастет снова. Следовательно, для активно изменяемых таблиц лучше с умеренной частотой выполнять VACUUM, чем очень редко выполнять VACUUM FULL
Планировщик запросов в PostgreSQL, выбирая эффективные планы запросов, полагается на статистическую информацию о содержимом таблиц. Эта статистика собирается командой ANALYZE, которая может вызываться сама по себе или как дополнительное действие команды VACUUM. Статистика должна быть достаточно точной, так как в противном случае неудачно выбранные планы запросов могут снизить производительность базы данных
Демон автоочистки, если он включён, будет автоматически выполнять ANALYZE после существенных изменений содержимого таблицы. Команду ANALYZE можно выполнять для отдельных таблиц и даже просто для отдельных столбцов таблицы, поэтому, если того требует приложение, одни статистические данные можно обновлять чаще, чем другие. Однако на практике обычно лучше просто анализировать всю базу данных, поскольку это быстрая операция, так как ANALYZE читает не каждую отдельную строку, а статистически случайную выборку строк таблицы
В PostgreSQL семантика транзакций MVCC зависит от возможности сравнения номеров идентификаторов транзакций (XID): версия строки, у которой XID добавившей её транзакции больше, чем XID текущей транзакции, относится «к будущему» и не должна быть видна в текущей транзакции. Однако поскольку идентификаторы транзакций имеют ограниченный размер (32 бита), кластер, работающий долгое время (более 4 миллиардов транзакций) столкнётся с зацикливанием идентификаторов транзакций: счётчик XID прокрутится до нуля, и внезапно транзакции, которые относились к прошлому, окажутся в будущем — это означает, что их результаты станут невидимыми
Периодическое выполнение очистки решает эту проблему, потому что процедура VACUUM помечает строки как замороженные, указывая, что они были вставлены транзакцией, зафиксированной достаточно давно, так что эффект добавляющей транзакции с точки зрения MVCC определённо будет виден во всех текущих и будущих транзакциях
MVCC — один из механизмов СУБД для обеспечения параллельного доступа к базам данных, заключающийся в предоставлении каждому пользователю так называемого «снимка» базы, обладающего тем свойством, что вносимые пользователем изменения невидимы другим пользователям до момента фиксации транзакции
На скриншоте ниже открыты две сессии к базе. Изначально testcolumn имел значение value1, далее в рамках транзакции изменяется это значение и проверяется что оно изменилось, при этом во втором окошке эти изменения были не видны пока в первом не был сделан end;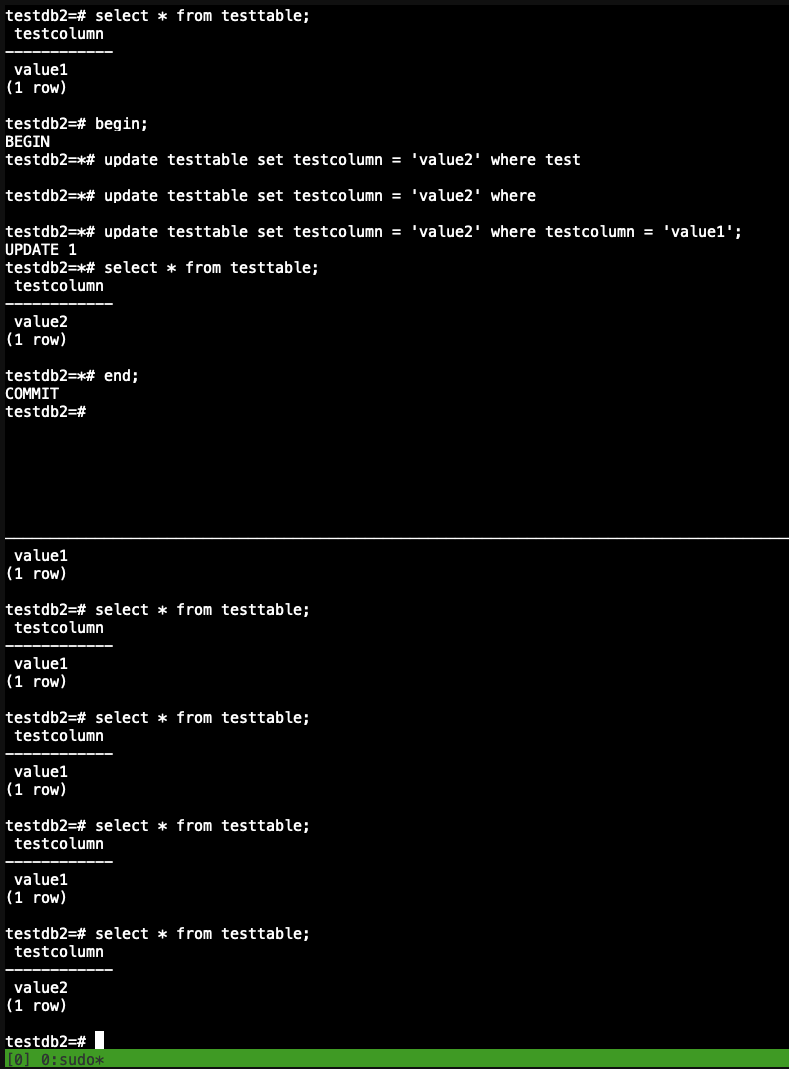
Прочитал по диагонали - https://postgrespro.ru/docs/postgresql/14/routine-vacuuming
В некоторых ситуациях стоит периодически перестраивать индексы, выполняя команду REINDEX или последовательность отдельных шагов по восстановлению индексов
Страницы индексов на основе B-деревьев, которые стали абсолютно пустыми, могут быть использованы повторно. Однако возможность неэффективного использования пространства всё же остаётся: если со страницы были удалены почти все, но не все ключи индекса, страница всё равно остаётся занятой
Кроме того, с B-деревьями доступ по недавно построенному индексу осуществляется немного быстрее, нежели доступ по индексу, который неоднократно изменялся, поскольку в недавно построенном индексе страницы, близкие логически, обычно расположены так же близко и физически
Команда REINDEX проста и безопасна для использования в любых случаях. Эта команда по умолчанию затребует блокировку ACCESS EXCLUSIVE, поэтому её обычно лучше выполнять с указанием CONCURRENTLY, с которым затребуется только SHARE UPDATE EXCLUSIVE
Резервное копирование и восстановление
Существует три фундаментально разных подхода к резервному копированию данных в PostgreSQL:
- Выгрузка в SQL
- Копирование на уровне файлов
- Непрерывное архивирование
Идея, стоящая за методом выгрузки в sql, заключается в генерации текстового файла с командами SQL, которые при выполнении на сервере пересоздадут базу данных в том же самом состоянии, в котором она была на момент выгрузки. PostgreSQL предоставляет для этой цели вспомогательную программу pg_dump. Простейшее применение этой программы выглядит так:
pg_dump имя_базы > файл_дампа
Важное преимущество pg_dump в сравнении с другими методами резервного копирования, описанными далее, состоит в том, что вывод pg_dump обычно можно загрузить в более новые версии PostgreSQL, в то время как резервная копия на уровне файловой системы и непрерывное архивирование жёстко зависят от версии сервера
Дампы, создаваемые pg_dump, являются внутренне согласованными, то есть, дамп представляет собой снимок базы данных на момент начала запуска pg_dump. pg_dump не блокирует другие операции с базой данных во время своей работы
Текстовые файлы, созданные pg_dump, предназначаются для последующего чтения программой psql. Общий вид команды для восстановления дампа:
psql имя_базы < файл_дампа
где файл_дампа — это файл, содержащий вывод команды pg_dump. База данных, заданная параметром имя_базы, не будет создана данной командой, так что вы должны создать её сами из базы template0 перед запуском psql (например, с помощью команды createdb -T template0 имя_базы)
Перед восстановлением SQL-дампа все пользователи, которые владели объектами или имели права на объекты в выгруженной базе данных, должны уже существовать. Если их нет, при восстановлении будут ошибки пересоздания объектов с изначальными владельцами и/или правами. (Иногда это желаемый результат, но обычно нет)
По умолчанию, если происходит ошибка SQL, программа psql продолжает выполнение. Если же запустить psql с установленной переменной ON_ERROR_STOP, это поведение поменяется и psql завершится с кодом 3 в случае возникновения ошибки SQL:
psql --set ON_ERROR_STOP=on имя_базы < файл_дампа
В любом случае вы получите только частично восстановленную базу данных. В качестве альтернативы можно указать, что весь дамп должен быть восстановлен в одной транзакции, так что восстановление либо полностью выполнится, либо полностью отменится. Включить данный режим можно, передав psql аргумент -1 или --single-transaction. Выбирая этот режим, учтите, что даже незначительная ошибка может привести к откату восстановления, которое могло продолжаться несколько часов
После восстановления резервной копии имеет смысл запустить ANALYZE для каждой базы данных, чтобы оптимизатор запросов получил полезную статистику
Программа pg_dump выгружает только одну базу данных в один момент времени и не включает в дамп информацию о ролях и табличных пространствах (так как это информация уровня кластера, а не самой базы данных). Для удобства создания дампа всего содержимого кластера баз данных предоставляется программа pg_dumpall, которая делает резервную копию всех баз данных кластера, а также сохраняет данные уровня кластера, такие как роли и определения табличных пространств. Простое использование этой команды:
pg_dumpall > файл_дампа
Полученную копию можно восстановить с помощью psql:
psql -f файл_дампа postgres
pg_dump/pg_dumpall умеют сжимать и писать параллельно в несколько файлов дампа
Альтернативной стратегией резервного копирования является непосредственное копирование файлов, в которых PostgreSQL хранит содержимое базы данных; Вы можете использовать любой способ копирования файлов по желанию, например:
tar -cf backup.tar /usr/local/pgsql/data
Однако существуют два ограничения, которые делают этот метод непрактичным или как минимум менее предпочтительным по сравнению с pg_dump:
- Чтобы полученная резервная копия была годной, сервер баз данных должен быть остановлен. Такие полумеры, как запрещение всех подключений к серверу, работать не будут (отчасти потому что tar и подобные средства не получают мгновенный снимок состояния файловой системы, но ещё и потому, что в сервере есть внутренние буферы). Необходимо отметить, что сервер нужно будет остановить и перед восстановлением данных.
- Если вы ознакомились с внутренней организацией базы данных в файловой системе, у вас может возникнуть соблазн скопировать или восстановить только отдельные таблицы или базы данных в соответствующих файлах или каталогах. Это не будет работать, потому что информацию, содержащуюся в этих файлах, нельзя использовать без файлов журналов транзакций, pg_xact/*, которые содержат состояние всех транзакций. Без этих данных файлы таблиц непригодны к использованию. Разумеется также невозможно восстановить только одну таблицу и соответствующие данные pg_xact, потому что в результате нерабочими станут все другие таблицы в кластере баз данных. Таким образом, копирование на уровне файловой системы будет работать, только если выполняется полное копирование и восстановление всего кластера баз данных
Наличие WAL делает возможным Point-in-Time Recovery
- В качестве начальной точки для восстановления необязательно иметь полностью согласованную копию на уровне файлов. Внутренняя несогласованность копии будет исправлена при воспроизведении журнала (практически то же самое происходит при восстановлении после краха). Таким образом, согласованный снимок файловой системы не требуется, вполне можно использовать tar или похожие средства архивации
- Поскольку при воспроизведении можно обрабатывать неограниченную последовательность файлов WAL, непрерывную резервную копию можно получить, просто продолжая архивировать файлы WAL. Это особенно ценно для больших баз данных, полные резервные копии которых делать как минимум неудобно
- Воспроизводить все записи WAL до самого конца нет необходимости. Воспроизведение можно остановить в любой точке и получить целостный снимок базы данных на этот момент времени. Таким образом, данная технология поддерживает восстановление на момент времени: можно восстановить состояние базы данных на любое время с момента создания резервной копии
- Если непрерывно передавать последовательность файлов WAL другому серверу, получившему данные из базовой копии того же кластера, получается система тёплого резерва: в любой момент мы можем запустить второй сервер и он будет иметь практически текущую копию баз данных
Программы pg_dump и pg_dumpall не создают копии на уровне файловой системы и не могут применяться как часть решения по непрерывной архивации. Создаваемые ими копии являются логическими и не содержат информации, необходимой для воспроизведения WAL
Для успешного восстановления с применением непрерывного архивирования, вам необходима непрерывная последовательность заархивированных файлов WAL, начинающаяся не позже, чем с момента начала копирования. Так что для начала вы должны настроить и протестировать процедуру архивирования файлов WAL до того, как получите первую базовую копию
WAL пишется бесконечно, а postgres физически делит эту последовательность на файлы сегментов WAL, которые обычно имеют размер 16 МиБ (хотя размер сегмента может быть изменён при initdb). Файлы сегментов получают цифровые имена, которые отражают их позицию в абстрактной последовательности WAL. Когда архивирование WAL не применяется, система обычно создаёт только несколько файлов сегментов и затем «перерабатывает» их, меняя номер в имени ставшего ненужным файла на больший. Предполагается, что файлы сегментов, содержимое которых предшествует последней контрольной точке, уже не представляют интереса и могут быть переработаны
При архивировании данных WAL необходимо считывать содержимое каждого файла-сегмента, как только он заполняется, и сохранять эти данные куда-то, прежде чем файл-сегмент будет переработан и использован повторно. В зависимости от применения и доступного аппаратного обеспечения, возможны разные способы «сохранить данные куда-то»
Чтобы у администратора баз данных была гибкость в этом плане, PostgreSQL пытается не делать каких-либо предположений о том, как будет выполняться архивация. Вместо этого, PostgreSQL позволяет администратору указать команду оболочки, которая будет запускаться для копирования завершённого файла-сегмента в нужное место. Эта команда может быть простой как cp, а может вызывать сложный скрипт оболочки — это решать вам
Чтобы включить архивирование WAL, установите в параметре конфигурации wal_level уровень replica (или выше), в archive_mode — значение on, и задайте желаемую команду оболочки в параметре archive_command. На практике эти параметры всегда задаются в файле postgresql.conf
Например
archive_command = 'test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f'
Будет преобразована для каждого нового wal-файла в что-то похожее на
test ! -f /mnt/server/archivedir/00000001000000A900000065 && cp pg_wal/00000001000000A900000065 /mnt/server/archivedir/00000001000000A900000065
Команда архивирования будет запущена от имени того же пользователя, от имени которого работает сервер PostgreSQL. Поскольку архивируемые последовательности файлов WAL фактически содержат всё, что есть в вашей базе данных, вам нужно будет защитить архивируемые данные от посторонних глаз; например, сохраните архив в каталог, чтение которого запрещено для группы и остальных пользователей
Важно, чтобы команда архивирования возвращала нулевой код завершения, если и только если она завершилась успешно. Получив нулевой результат, PostgreSQL будет полагать, что файл успешно заархивирован и удалит его или переработает. Однако ненулевой код состояния скажет PostgreSQL, что файл не заархивирован; попытки заархивировать его будут периодически повторяться, пока это не удастся. Следовательно если что-то случится с бэкапилкой (например кончится место на удаленном сервере), то wal-файлы не будут удаляться и может закончиться место на сервере с postgres'ом, это нужно учитывать и писать скрипт-архиватор с умом
При написании команды архивирования вы должны иметь в виду, что имена файлов для архивирования могут иметь длину до 64 символов и содержать любые комбинации из цифр, точек и букв ASCII
Конфигурационные файлы (такие как postgresql.conf, pg_hba.conf и pg_ident.conf), измененяются вручную, а не через SQL. Поэтому имеет смысл разместить конфигурационные файлы там, где они будут заархивированы обычными процедурами копирования файлов
Команда архивирования вызывается, только когда сегмент WAL заполнен до конца, поэтому при маленьком трафике может возникать большая задержка между завершением транзакции и ее архивированием
Чтобы ограничить время жизни неархивированных данных, можно установить archive_timeout, чтобы сервер переключался на новый файл сегмента WAL как минимум с заданной частотой. Заметьте, что неполные файлы, архивируемые досрочно из-за принудительного переключения по тайм-ауту, будут иметь тот же размер, что и заполненные файлы. Таким образом, устанавливать очень маленький archive_timeout — неразумно; это приведёт к неэффективному заполнению архива
Если вы хотите на время остановить архивирование, это можно сделать, например, задав в качестве значения archive_command пустую строку (''). В результате файлы WAL будут накапливаться в каталоге pg_wal/, пока не будет восстановлена действующая команда archive_command
pg_dumpcreates a logical backup, that is a series of SQL statements that, when executed, create a new database that is logically like the original onepg_basebackupcreates a physical backup, that is a copy of the files that constitute the database cluster. You have to use recovery to make such a backup consistent
The main differences are:
- pg_dump typically takes longer and creates a smaller backup
- With pg_dump you can back up one database or parts of a database, while pg_basebackup always backs up the whole cluster
- A backup created by pg_dump is complete, while you need WAL archives to restore a backup created with pg_basebackup (unless you used the default option -X stream, in which case the backup contains the WAL segments required to make the backup consistent)
- With a logical backup you can only restore the state of the database at backup time, while with a physical backup you can restore any point in time after the end of the backup, provided you archived the required WAL segments
- You need pg_basebackup to create a standby server, pg_dump won't do
Проще всего получить базовую резервную копию, используя программу pg_basebackup. Эта программа сохраняет базовую копию в виде обычных файлов или в архиве tar
Создаем бэкап и перекачиваем его на другой сервер
root@pgsql-edu:/tmp# sudo -u postgres pg_basebackup -D /tmp/pgback/ -Ft -Xs -P
73159/73159 kB (100%), 2/2 tablespaces
root@pgsql-edu:/tmp# ls -lh pgback/
total 88M
-rw------- 1 postgres postgres 2.5K Jan 10 03:21 16421.tar
-rw------- 1 postgres postgres 264K Jan 10 03:21 backup_manifest
-rw------- 1 postgres postgres 72M Jan 10 03:21 base.tar
-rw------- 1 postgres postgres 17M Jan 10 03:21 pg_wal.tar
root@pgsql-edu:/tmp# scp -r pgback/* user@192.168.0.29:/tmp/back/.
user@192.168.0.29's password:
16421.tar 100% 2560 7.8MB/s 00:00
backup_manifest 100% 263KB 248.1MB/s 00:00
base.tar 100% 71MB 278.8MB/s 00:00
pg_wal.tar 100% 16MB 307.2MB/s 00:00
На втором сервере выключаем постгрес и распаковываем это все (находясь в PGDATA)
tar -xf /tmp/back/16421.tar -C /mnt/tipasuperssd
tar -xf /tmp/back/base.tar -C .
tar -xf /tmp/back/pg_wal.tar -C ./pg_wal/
Запускаем, проверяем
root@pgsql-1:/tmp/back# sudo -u postgres psql
psql (14.1 (Debian 14.1-1.pgdg110+1))
Type "help" for help.
postgres=# \c testdb
You are now connected to database "testdb" as user "postgres".
testdb=# select * from testtable order by id desc limit 3;
id | date
-----+------------------------------
181 | Mon Jan 10 00:35:09 UTC 2022
180 | Mon Jan 10 00:35:09 UTC 2022
179 | Mon Jan 10 00:35:09 UTC 2022
(3 rows)
По-нормальному про восстановление - https://postgrespro.ru/docs/postgresql/14/continuous-archiving
Перечитать вторую половину
Отказоустойчивость, балансировка нагрузки и репликация
Некоторые решения применяют синхронизацию, позволяя только одному серверу изменять данные. Сервер, который может изменять данные, называется сервером чтения/записи, ведущим или главным сервером. Сервер, который отслеживает изменения на ведущем, называется ведомым или резервным сервером. Резервный сервер, к которому нельзя подключаться до тех пор, пока он не будет повышен до главного, называется сервером тёплого резерва, а тот, который может принимать соединения и обрабатывать запросы только на чтение, называется сервером горячего резерва
Сравнение решений для репликации https://postgrespro.ru/docs/postgresql/14/different-replication-solutions
Обычно разумно подбирать ведущий и резервный серверы так, чтобы они были максимально похожи, как минимум с точки зрения базы данных. Тогда в частности, пути, связанные с табличными пространствами, могут передаваться без изменений. Таким образом, как на ведущем, так и на резервных серверах должны быть одинаковые пути монтирования для табличных пространств при использовании этой возможности БД. Учитывайте, что если CREATE TABLESPACE выполнена на ведущем сервере, новая точка монтирования для этой команды уже должна существовать на резервных серверах до её выполнения
архитектура оборудования должна быть одинаковой — например, трансляция журналов с 32-битной на 64-битную систему не будет работать
В общем случае трансляция журналов между серверами с различными основными версиями PostgreSQL невозможна
ведущий и резервный серверы, имеющие разные корректирующие версии, могут работать успешно. Тем не менее формально такая возможность не поддерживается, поэтому рекомендуется поддерживать одинаковую версию ведущего и резервных серверов, насколько это возможно. При обновлении корректирующей версии безопаснее будет в первую очередь обновить резервные серверы — новая корректирующая версия с большей вероятностью прочитает файл WAL предыдущей корректирующей версии, чем наоборот
PostgreSQL реализует трансляцию журналов на уровне файлов, передавая записи WAL по одному файлу (сегменту WAL) единовременно. Файлы WAL (размером 16 МБ) можно легко и эффективно передать на любое расстояние, будь то соседний сервер, другая система в местной сети или сервер на другом краю света
Существует окно, когда возможна потеря данных при отказе сервера: будут утеряны ещё не переданные транзакции (wal-файлы). Размер этого окна при трансляции файлов журналов может быть ограничен параметром archive_timeout, который может принимать значение меньше нескольких секунд. Тем не менее подобные заниженные значения могут потребовать существенного увеличения пропускной способности, необходимой для трансляции файлов
резервный сервер может обрабатывать читающие запросы. В этом случае он называется сервером горячего резерва
Сервер переходит в режим ожидания, если в каталоге данных при запуске сервера есть файл standby.signal
резервного, последовательно применяет файлы WAL, полученные от главного. Резервный сервер может читать файлы WAL из архива WAL (см. restore_command) или напрямую с главного сервера по соединению TCP (потоковая репликация). Резервный сервер также будет пытаться восстановить любой файл WAL, найденный в кластере резервного в каталоге pg_wal. Это обычно происходит после перезапуска сервера, когда он применяет заново файлы WAL, полученные от главного сервера перед перезапуском. Но можно и вручную скопировать файлы в каталог pg_wal, чтобы применить их в любой момент времени
Режим резерва завершается и сервер переключается в обычный рабочий режим при получении команды pg_ctl promote, в результате вызова pg_promote() или при обнаружении файла-триггера (promote_trigger_file). Перед переключением сервер восстановит все файлы WAL, непосредственно доступные из архива или pg_wal, но пытаться подключиться к главному серверу он больше не будет
Для запуска резервного сервера нужно восстановить резервную копию, снятую с ведущего. Затем нужно создать файл standby.signal в каталоге данных кластера резервного сервера. Задайте в restore_command обычную команду копирования файлов из архива WAL
Команда restore_command должна немедленно завершиться при отсутствии файла; сервер повторит эту команду при необходимости
При необходимости потоковой репликации задайте в primary_conninfo параметры строки соединения для libpq, включая имя (или IP-адрес) сервера и всё, что требуется для подключения к ведущему серверу. Если ведущий требует пароль для аутентификации, пароль также должен быть указан в primary_conninfo
При потоковой репликации резервный сервер может работать с меньшей задержкой, чем при трансляции файлов. Резервный сервер подключается к ведущему, который передаёт поток записей WAL резервному в момент их добавления, не дожидаясь окончания заполнения файла WAL
Потоковая репликация асинхронна по умолчанию (см. Подраздел 27.2.8), то есть имеется небольшая задержка между подтверждением транзакции на ведущем сервере и появлением этих изменений на резервном. Тем не менее эта задержка гораздо меньше, чем при трансляции файлов журналов, обычно в пределах одной секунды, если резервный сервер достаточно мощный и справляется с нагрузкой. При потоковой репликации настраивать archive_timeout для уменьшения окна потенциальной потери данных не требуется
При потоковой репликации без постоянной архивации на уровне файлов, сервер может избавиться от старых сегментов WAL до того, как резервный получит их. В этом случае резервный сервер потребует повторной инициализации из новой базовой резервной копии. Этого можно избежать, установив для wal_keep_size достаточно большое значение, при котором сегменты WAL будут защищены от ранней очистки, либо настроив слот репликации для резервного сервера. Если с резервного сервера доступен архив WAL, этого не требуется, так как резервный может всегда обратиться к архиву для восполнения пропущенных сегментов
При запуске резервного сервера с правильно установленным primary_conninfo резервный подключится к ведущему после воспроизведения всех файлов WAL, доступных из архива. При успешном установлении соединения можно увидеть walreceiver на резервном сервере и соответствующий процесс walsender на ведущем
Важным индикатором стабильности работы потоковой репликации является количество записей WAL, созданных на ведущем, но ещё не применённых на резервном сервере. Задержку можно подсчитать, сравнив текущую позиции записи WAL на ведущем с последней позицией WAL, полученной на резервном сервере. Эти позиции можно узнать, воспользовавшись функциями pg_current_wal_lsn на ведущем и pg_last_wal_receive_lsn на резервном, соответственно
Список процессов-передатчиков WAL можно получить через представление pg_stat_replication
# leader
postgres=# select pg_current_wal_lsn();
-[ RECORD 1 ]------+----------
pg_current_wal_lsn | 0/B67F558
# follower
postgres=# select pg_last_wal_receive_lsn();
-[ RECORD 1 ]-----------+----------
pg_last_wal_receive_lsn | 0/B68EED8
Большая разница между pg_current_wal_lsn и полем sent_lsn может указывать на то, что главный сервер работает с большой нагрузкой
# leader
postgres=# select pg_current_wal_lsn();
-[ RECORD 1 ]------+----------
pg_current_wal_lsn | 0/B7889F8
postgres=# select sent_lsn from pg_stat_replication where application_name = 'pgsql-patroni-2';
-[ RECORD 1 ]-------
sent_lsn | 0/B789F88
Тогда как разница между sent_lsn и pg_last_wal_receive_lsn на резервном может быть признаком задержек в сети или большой нагрузки резервного сервера
# leader
postgres=# select sent_lsn from pg_stat_replication where application_name = 'pgsql-patroni-2';
-[ RECORD 1 ]-------
sent_lsn | 0/B81D6E0
# follower
postgres=# select pg_last_wal_receive_lsn();
-[ RECORD 1 ]-----------+----------
pg_last_wal_receive_lsn | 0/B8204C0
На сервере горячего резерва состояние процесса-приёмника WAL можно получить через представление pg_stat_wal_receiver
# follower
postgres=# select * from pg_stat_wal_receiver;
-[ RECORD 1 ]---------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 93032
status | streaming
receive_start_lsn | 0/A000000
receive_start_tli | 3
written_lsn | 0/B925DB8
flushed_lsn | 0/B925DB8
received_tli | 3
last_msg_send_time | 2022-02-21 23:26:39.140219+00
last_msg_receipt_time | 2022-02-21 23:26:39.140284+00
latest_end_lsn | 0/B925DB8
latest_end_time | 2022-02-21 23:26:39.140219+00
slot_name | pgsql_patroni_2
sender_host | 192.168.0.153
sender_port | 5432
conninfo | user=replicator passfile=/var/lib/postgresql/.pgpass_patroni host=192.168.0.153 port=5432 sslmode=prefer application_name=pgsql-patroni-2 gssencmode=prefer channel_binding=prefer
Большая разница между pg_last_wal_replay_lsn и полем flushed_lsn свидетельствует о том, что WAL поступает быстрее, чем удаётся его воспроизвести
postgres=# select pg_last_wal_replay_lsn();
-[ RECORD 1 ]----------+----------
pg_last_wal_replay_lsn | 0/C199EC0
postgres=# select flushed_lsn from pg_stat_wal_receiver;
-[ RECORD 1 ]----------
flushed_lsn | 0/C19BC68
Представление pg_stat_replication отображает что-либо лишь на лидере, на резервах вывод будет пустым
Слоты репликации автоматически обеспечивают механизм сохранения сегментов WAL, пока они не будут получены всеми резервными и главный сервер не будет удалять строки, находящиеся в статусе recovery conflict даже при отключении резервного
Каждый слот репликации обладает именем, состоящим из строчных букв, цифр и символов подчёркивания
Имеющиеся слоты репликации и их статус можно просмотреть в представлении pg_replication_slots
postgres=# \x
Expanded display is on.
postgres=# select * from pg_replication_slots;
-[ RECORD 1 ]-------+----------------
slot_name | pgsql_patroni_2
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 3625184
xmin | 150906
catalog_xmin |
restart_lsn | 0/C2DC580
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |
two_phase | f
-[ RECORD 2 ]-------+----------------
slot_name | pgsql_patroni_3
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 3625159
xmin | 150913
catalog_xmin |
restart_lsn | 0/C2DC580
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |
two_phase | f
По умолчанию в PostgreSQL потоковая репликация асинхронна. Если ведущий сервер выходит из строя, некоторые транзакции, которые были подтверждены, но не переданы на резервный, могут быть потеряны. Объём потерянных данных пропорционален задержке репликации на момент отработки отказа
Если ведущий сервер отказывает, резервный должен начать процедуры отработки отказа
Если отказывает резервный сервер, никакие действия по отработке отказа не требуются
Когда ведущий сервер отказывает и резервный сервер становится новым ведущим, а затем старый ведущий включается снова, необходим механизм для предотвращения возврата старого к роли ведущего. Иногда его называют STONITH (Shoot The Other Node In The Head, «Выстрелите в голову другому узлу»), что позволяет избежать ситуации, когда обе системы считают себя ведущими, и в результате возникают конфликты и потеря данных
Термин «горячий резерв» используется для описания возможности подключаться к серверу и выполнять запросы на чтение, в то время как сервер находится в режиме резерва или восстановления архива
Когда параметр hot_standby на резервном сервере установлен в true, то он начинает принимать соединения сразу как только система придёт в согласованное состояние в процессе восстановления. Для таких соединений будет разрешено только чтение, запись невозможна даже во временные таблицы
Транзакции, запущенные в режиме горячего резерва, никогда не получают ID транзакции и не могут быть записаны в журнал предзаписи. Поэтому при попытке выполнить некоторые действия возникнут ошибки
В режиме горячего резерва параметр transaction_read_only всегда имеет значение true и изменить его нельзя. Но если не пытаться модифицировать содержимое БД, подключение к серверу в этом режиме не отличается от подключений к обычным базам данных. При отработке отказа или переключении ролей база данных переходит в обычный режим работы. Когда сервер меняет режим работы, установленные сеансы остаются подключёнными. После выхода из режима горячего резерва становится возможным запускать пишущие транзакции (даже в сеансах, начатых ещё в режиме горячего резерва)
События на ведущем сервере оказывают влияние на резервный. В результате имеется потенциальная возможность отрицательного влияния или конфликта между ними. Наиболее простой для понимания конфликт — быстродействие: если на ведущем происходит загрузка очень большого объёма данных, то происходит создание соответствующего потока записей WAL на резервный сервер. Таким образом, запросы на резервном конкурируют за системные ресурсы, например, ввод-вывод
Так же может возникнуть дополнительный тип конфликта на сервере горячего резерва. Этот конфликт называется жёстким конфликтом, оказывает влияние на запросы, приводя к их отмене, а в некоторых случаях и к обрыву сессии для разрешения конфликтов
В этих случаях на ведущем сервере просто происходит ожидание; пользователю следует выбрать какую их конфликтующих сторон отменить. Тем не менее на резервном нет выбора: действия из WAL уже произошли на ведущем, поэтому резервный обязан применить их. Более того, позволять обработчику WAL ожидать неограниченно долго может быть крайне нежелательно, так как отставание резервного сервера от ведущего может всё возрастать. Таким образом, механизм обеспечивает принудительную отмену запросов на резервном сервере, которые конфликтуют с применяемыми записями WAL
Примером такой проблемы может быть ситуация: администратор на ведущем сервере выполнил команду DROP TABLE для таблицы, которая сейчас участвует в запросе на резервном. Понятно, что этот запрос нельзя будет выполнять дальше, если команда DROP TABLE применится на резервном. Если бы этот запрос выполнялся на ведущем, команда DROP TABLE ждала бы его окончания. Но когда на ведущем выполняется только команда DROP TABLE, ведущий сервер не знает, какие запросы выполняются на резервном, поэтому он не может ждать завершения подобных запросов. Поэтому если записи WAL с изменением прибудут на резервный сервер, когда запрос будет продолжать выполняться, возникнет конфликт. В этом случае резервный сервер должен либо задержать применение этих записей WAL (и всех остальных, следующих за ними), либо отменить конфликтующий запрос, чтобы можно было применить DROP TABLE
Если конфликтный запрос короткий, обычно желательно разрешить ему завершиться, ненадолго задержав применение записей WAL, но слишком большая задержка в применении WAL обычно нежелательна. Поэтому механизм отмены имеет параметры max_standby_archive_delay и max_standby_streaming_delay, которые определяют максимально допустимое время задержки применения WAL. Конфликтующие запросы будут отменены, если они длятся дольше допустимого времени задержки применения очередных записей WAL