Prometheus
- Getting started
- Configuration/Configuration
- Configuration/Recording rules
- Configuration/Alerting rules
- Configuration/Template examples
- Configuration/Template reference
- Configuration/Unit Testing for Rules
- Configuration/HTTPS and authentication
- Querying/Basics
- Querying/Operators
- Storage
- Federation
- HTTP SD
- Management API
- Disabled Features
Getting started
# Start Prometheus.
# By default, Prometheus stores its database in ./data (flag --storage.tsdb.path).
./prometheus --config.file=prometheus.yml
Добавляем в конфиг
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'vandud'
static_configs:
- targets: ['two.vandud.ru:80']
Рестартуем
И действительно появилось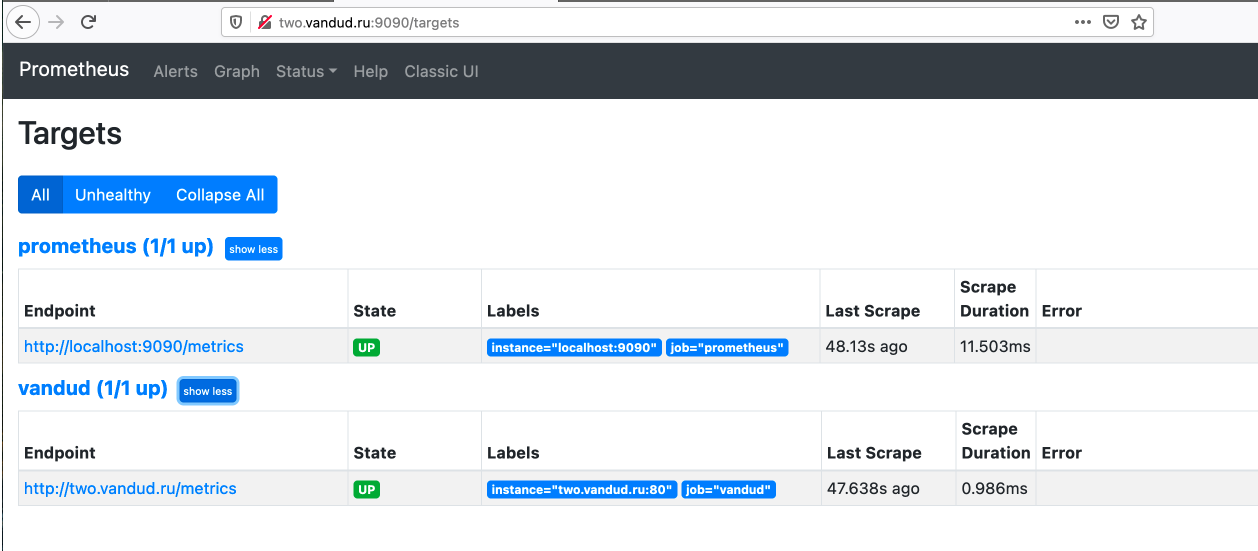
Пока у нас не много метрик, нет проблемы в вычислении функций для них
Но когда их становится много, то вычисление начнет занимать значительное время
В таких случаях можно настроить особые правила по которым prometheus будет аггрегировать данные в новые time series
Эти правила можно описать в отдельном файле
groups:
- name: cpu-node
rules:
- record: job_instance_mode:node_cpu_seconds:avg_rate5m
expr: avg by (job, instance, mode) (rate(node_cpu_seconds_total[5m]))
И подключать в основной конфиг так
rule_files:
- 'prometheus.rules.yml'
Configuration/Configuration
https://prometheus.io/docs/prometheus/latest/configuration/configuration/
Prometheus настраивается через флаги командной строки и конфигурационный файл
Флагами указываются неизменяемые параметры
Конфигом настриваются джобы, инстансы, правила и прочее
./prometheus -h - покажет доступные флаги
Prometheus может релоадить конфигурацию во время работы. Если она нерабочая, то она не применится
Для инициализации релоада есть два пути:
- Послать SIGHUP процессу
- Послать POST запрос на эндпоинт
/-/reload(но для этого должен быть включен флаг--web.enable-lifecycle)
Файлы с правилами также будут перезагружены
global:
# How frequently to scrape targets by default.
[ scrape_interval: <duration> | default = 1m ]
# How long until a scrape request times out.
[ scrape_timeout: <duration> | default = 10s ]
# How frequently to evaluate rules.
[ evaluation_interval: <duration> | default = 1m ]
# The labels to add to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
[ <labelname>: <labelvalue> ... ]
# File to which PromQL queries are logged.
# Reloading the configuration will reopen the file.
[ query_log_file: <string> ]
# Rule files specifies a list of globs. Rules and alerts are read from
# all matching files.
rule_files:
[ - <filepath_glob> ... ]
# A list of scrape configurations.
scrape_configs:
[ - <scrape_config> ... ]
# Alerting specifies settings related to the Alertmanager.
alerting:
alert_relabel_configs:
[ - <relabel_config> ... ]
alertmanagers:
[ - <alertmanager_config> ... ]
# Settings related to the remote write feature.
remote_write:
[ - <remote_write> ... ]
# Settings related to the remote read feature.
remote_read:
[ - <remote_read> ... ]
-
<scrape_config>- эта секция определяет набор целей и параметров для них
Цели могут указываться черезscrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'vandud' static_configs: - targets: ['two.vandud.ru:80','two.vandud.ru:9914']static_configsили через какой-либо механиз service-discovery
-
<file_sd_config>- сервис дискавери основанный на файлах дает более общий способ конфигурирования статических целей используя кастомные механизмы sd
Он читает набор файлов содержащих списокstatic_config'ов
Изменения в них будут применяться автоматически (релоадить не надо)
Файлы могут быть в yaml или json формате- targets: [ - '<host>' ] labels: [ <labelname>: <labelvalue> ... ][ { "targets": [ "<host>", ... ], "labels": { "<labelname>": "<labelvalue>", ... } }, ... ]
-
<static_config>- позволяет перечислить список таргетов и общие для них лейблы# The targets specified by the static config. targets: [ - '<host>' ] # Labels assigned to all metrics scraped from the targets. labels: [ <labelname>: <labelvalue> ... ]
-
<alertmanager_config>- эта секция указывает в какие инстансы алертменеджера prometheus будет слать алерты
Также тут задаются параметры для коммуникации между алертменеджерами и prometheus'ом
Можно статически сконфигурировать черезstatic_configsили использовать сервис дискавери механизмы
-
<remote_write>/<remote_read>- можно настраивать параметры подключения, аутентификацию и прочее
Configuration/Recording rules
В prometheus'e есть два вида правил которые могут быть сконфигурированы и выполняться через регулярные интервалы:
- recording rules
- alerting rules
Правила нужно описать в отдельном файле в yaml и включить в основной конфиг через директиву rule_files
Файлы и правилами не подгружаются автоматически в процессе работы. Чтобы prometheus обновил зарелоадил их, нужно отправить ему SIGHUP
Все правила из файла применятся только если все они описаны корректно. Если хоть где-то ошибка (хоть в одном из множетства файлов), то не применится ни одно
Syntax-checking rules
Проверить файл с правилами на корректность можно утилитой promtool
root@two:~/prometheus-2.27.1.linux-amd64# ./promtool check rules prometheus.rules.yaml
Checking prometheus.rules.yaml
SUCCESS: 1 rules found
root@two:~/prometheus-2.27.1.linux-amd64# echo $?
0
root@two:~/prometheus-2.27.1.linux-amd64# ./promtool check rules prometheus.rules.incorrect.yaml
Checking prometheus.rules.incorrect.yaml
FAILED:
prometheus.rules.incorrect.yaml: yaml: unmarshal errors:
line 1: field gros not found in type rulefmt.RuleGroups
root@two:~/prometheus-2.27.1.linux-amd64# echo $?
1
Как видно выше, она выдает человекочитаемый результат, а так же соответствующий exitcode
Recording rules
Recording rules позволяют предподсчитывать частые или вычислительносложные выражения и сохранять их результат как новую таймсерию
Это особенно полезно для дашбордов (потому что они постоянно запрашивают одно и то же)
Правила записи и оповещений существуют в группе правил
А их имена должны соответствовать правилам именования метрик и лейблов соответственно
groups:
[ - <rule_group> ]
Пример:
groups:
- name: example
rules:
- record: job:http_inprogress_requests:sum
expr: sum by (job) (http_inprogress_requests)
-
<rule_group>- содержит имя группы, интервал и сами правила. Должно быть уникальным в пределах файла -
<rule>- описываются внутри группы. Содержит имя таймсерии в которую будет записывать результат выполнения выражения, само выражение в PromQL и лейблы
Правила алертинга описываются точно так же, только вместо 'record' пишется 'alert' и добавляется аннотация и продолжительность
Configuration/Alerting rules
Правила алертинга позволяют определять состояния используя prometheus expression language и слать алерты во внешние сервисы
Когда выражение возвращает один или несколько элементов на протяжении указанного периода, алерт считается активным для набора лейблов
Defining alerting rules
Правила алертинга конфигурируются так же как и правила записи
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency
-
for- опциональный параметр. Указывает prometheus'у проверять на протяжении указанного периода, то что выражение активно, и только после этого слать алерт. Уже активные, но еще не сработавшие алерты находятся в состоянии ожидания -
labels- тут можно определить набор лейблов для алерта -
annotations- тут можно определить набор информационных лейблов, например описание проблемы или полезные ссылки
Templating
Лейблы и аннотации могут быть затемплейчены через console templates
Переменная $labels содержит пары key/value алерт инстанса
Внешние лейблы могут вызываться через $externalLabels
Переменная $value содержит значение
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
Inspecting alerts during runtime
После того как у нас сработал алерт, мы можем получить time series по этому алерту, в метрике хранится состояние проверки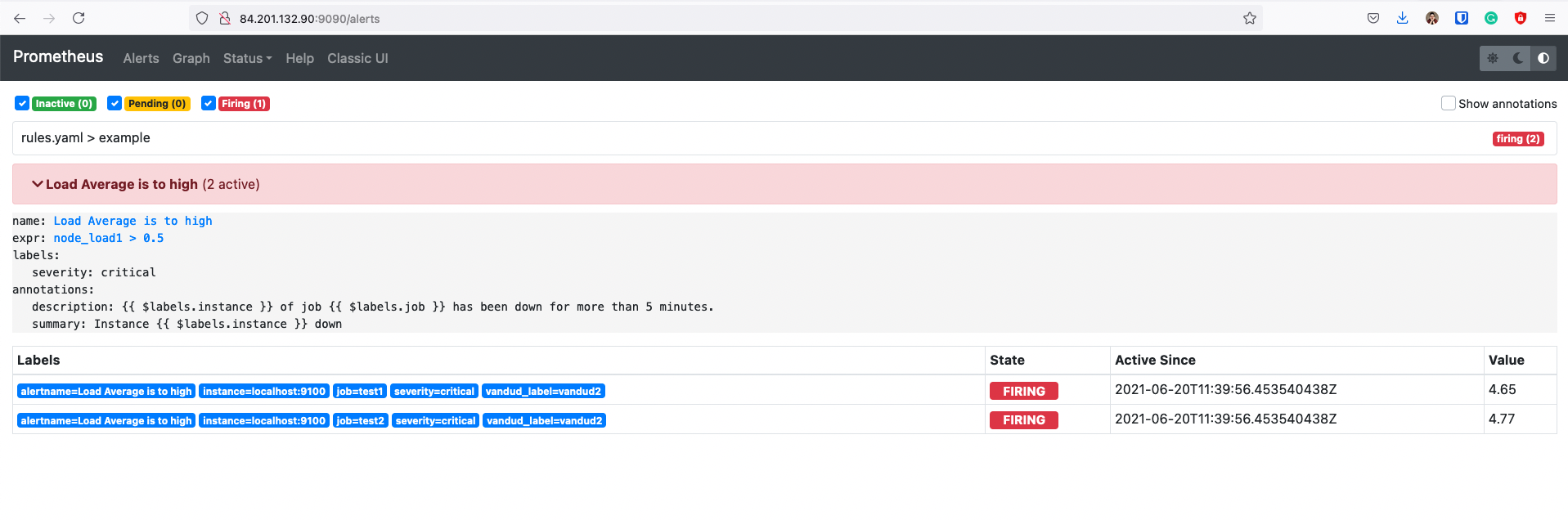

Time Series ALERTS хранит только активные и ожидающие алерты
На скрине видно что данные перестали писаться в этот временной ряд после того как алерт перешел в ОК
Единица туда пишется просто так, чтобы писать хоть что-то, смысловой нагрузки единица не несет
Sending alert notifications
Страница с алертами это хороший способ узнать что сломано прямо сейчас
Но это не полноценное решение для нотификаций
Следующим уровнем нужно добавить суммирование, ограничение скорости уведомлений, приглушение и зависимости алертов
В экосистеме prometheus эту роль занимает alertmanager
Прометеус шлет в алертменеджер все подряд, а алертменеджер отсылает только то что нужно (с учетом зависимостей и прочего)
Прометеус может быть настроен на автодискаверинг доступных алертменеджеров
Configuration/Template examples
Прометеус поддерживает шаблонизирование в аннотациях и лейблах алертов
Темплейтирование основано на go templating
Simple alert field templates
alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{$labels.instance}} down"
description: "{{$labels.instance}} of job {{$labels.job}} has been down for more than 5 minutes."
Шаблонизирование выполняется во время каждой итерации во время каждого правила, поэтому шаблонизирование должно быть простым
Если нужно сложное, то рекомендуется переходить по ссылке на консоль
Simple iteration
Консоли можно смотреть тут prometheus.server.local:9090/consoles
{{ range query "up" }}
{{ .Labels.instance }} {{ .Value }}
{{ end }}
Например это отобразит список инстансов и подняты ли они
Переменная по имени . содержит текущие значения
https://prometheus.io/docs/prometheus/latest/configuration/template_examples/
Configuration/Template reference
Прометеус позволяет шаблонизировать аннотации и лейблы для алертов
https://prometheus.io/docs/prometheus/latest/configuration/template_reference/
Configuration/Unit Testing for Rules
Можно использовать утилиту promtool для тестирования правил
# For a single test file.
./promtool test rules test.yml
# If you have multiple test files, say test1.yml,test2.yml,test2.yml
./promtool test rules test1.yml test2.yml test3.yml
https://prometheus.io/docs/prometheus/latest/configuration/unit_testing_rules/
Configuration/HTTPS and authentication
Через ключ --web.config.file можно указать веб конфиг
Файл перечитывается на каждый http запрос
Поэтому изменения принимаются автоматически (без релоадов)
https://prometheus.io/docs/prometheus/latest/configuration/https/
Пример:
tls_server_config:
cert_file: server.crt
key_file: server.key
basic_auth_users:
alice: $2y$10$mDwo.lAisC94iLAyP81MCesa29IzH37oigHC/42V2pdJlUprsJPze
bob: $2y$10$hLqFl9jSjoAAy95Z/zw8Ye8wkdMBM8c5Bn1ptYqP/AXyV0.oy0S8m
Querying/Basics
Прометеус предоставляет язык запросов PromQL (Premetheus Query Language), который позволяет выбирать и аггрегировать timeseries данные в реальном времени
Резльтат запроса может быть отображен в виде графика или таблицы интерфейсе прометеуса или может быть "поглащен" внешней системой через HTTP API
Expression language data types
Выражения и подвыражения в promql могут выполняться в один из четырех типов данных:
-
Instant vector- a set of time series containing a single sample for each time series, all sharing the same timestamp -
Range vector- a set of time series containing a range of data points over time for each time series -
Scalar- a simple numeric floating point value -
String- a simple string value; currently unused
Разные типы подходят для разных кейсов
Например только instant vector может быть отображен на графике
Literals
Строки можно определять в одинарных, двойных кавычках или тиках
PromQL следует принципам из Go, поэтому в двойных или одинарных кавычках \ начинает escape-sequence, за \ может следовать a, b, f, n, r, t, v или \
Конкретный символ может быть задан в octal формате \nnn или hexadecimal \xnn, \unnnn, \Unnnnnnnn
В тиках escape последовательности не обрабатываются. В отличие от Go, Prometheus не отменяет новую строку внутри тиков
"this is a string"
'these are unescaped: \n \\ \t'
`these are not unescaped: \n ' " \t`
Time series Selectors

Instant vector selectors
Instant vector selectors позволяют выбирать нобор timeseries и одно значение из каждого на какой-то конкретный timestamp
Пример ниже выберет все time series которые имеют http_requests_total в metric name:
http_requests_total
Можно сделать более тонкую фильтрацию добавив лейблы в фигрных скобках http_requests_total{label1="label1", label2="label2"}
Кроме знака равенства лейблы можно матчить следующими операторами:
-
=- Select labels that are exactly equal to the provided string -
!=- Select labels that are not equal to the provided string -
=~- Select labels that regex-match the provided string -
!~- Select labels that do not regex-match the provided string
Пример:
http_requests_total{environment=~"staging|testing|development",method!="GET"}
Vector selector должен иметь имя или не менее одного лейбла который матчится с непустой строкой
{job=~".*"} # Bad! Потому что ".*" матчится с пустой строкой
{job=~".+"} # Good!
{job=~".*",method="get"} # Good!
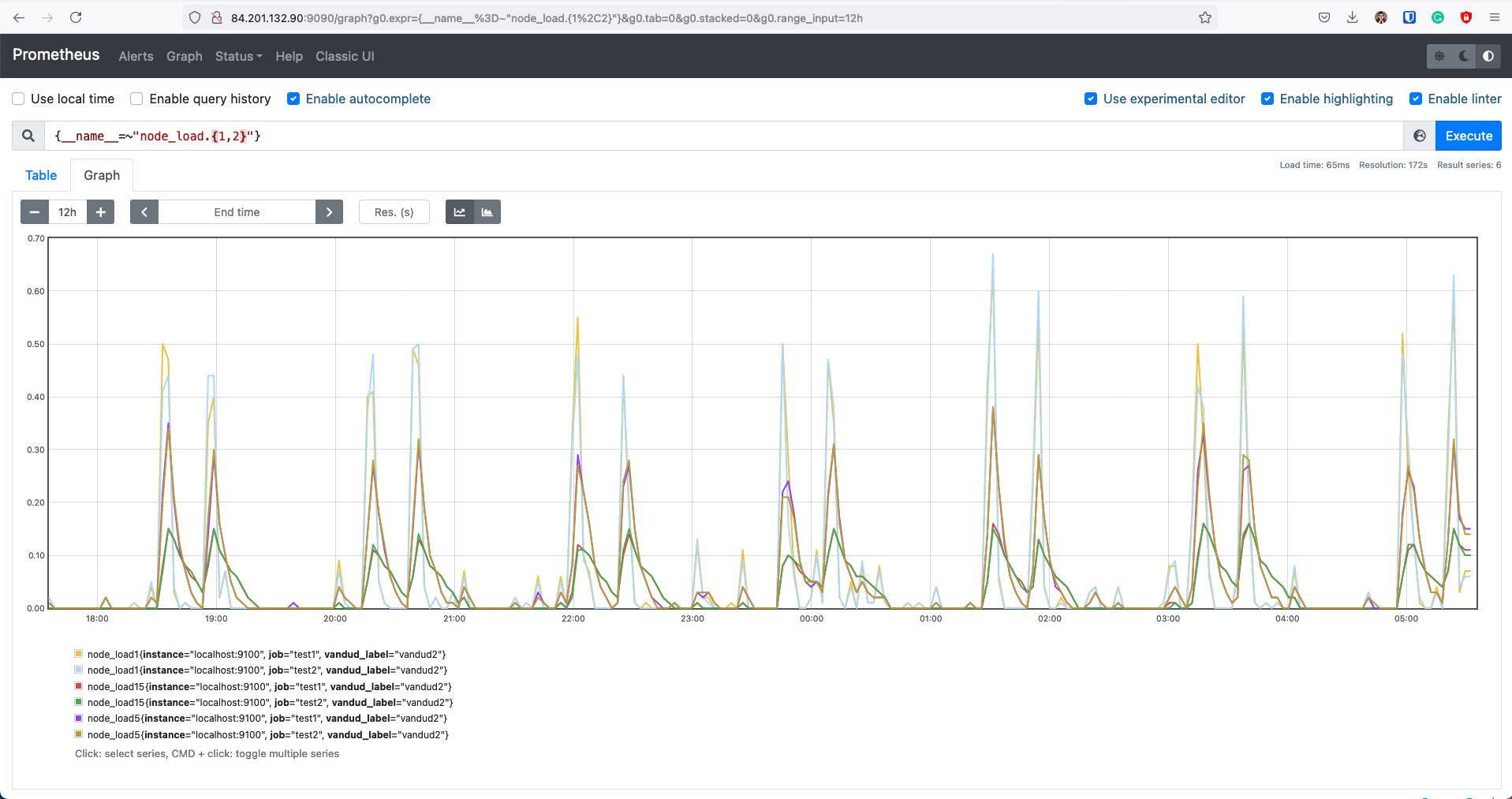
На скрине видно две джобы, хотя на момент выполнения запроса одна из них была удалена. То есть уже собранные данные остаются в базе и доступны для обработки не смотря на отсутствие таргета
Каждая таймсерия идентифицируется именем и набором лейблов. Поэтому если собирать данные по какому-то имени и лейблам, а потом собирать по ним же другие данные, то график просто продолжит строиться из новых данных
Имена метрик можно матчить через внутренний лейбл __name__ (как на скрине выше)http_requests_total -> {__name__="http_requests_total"}
А на следующем скриншоте наоборот
После изменения лейбла появился новый график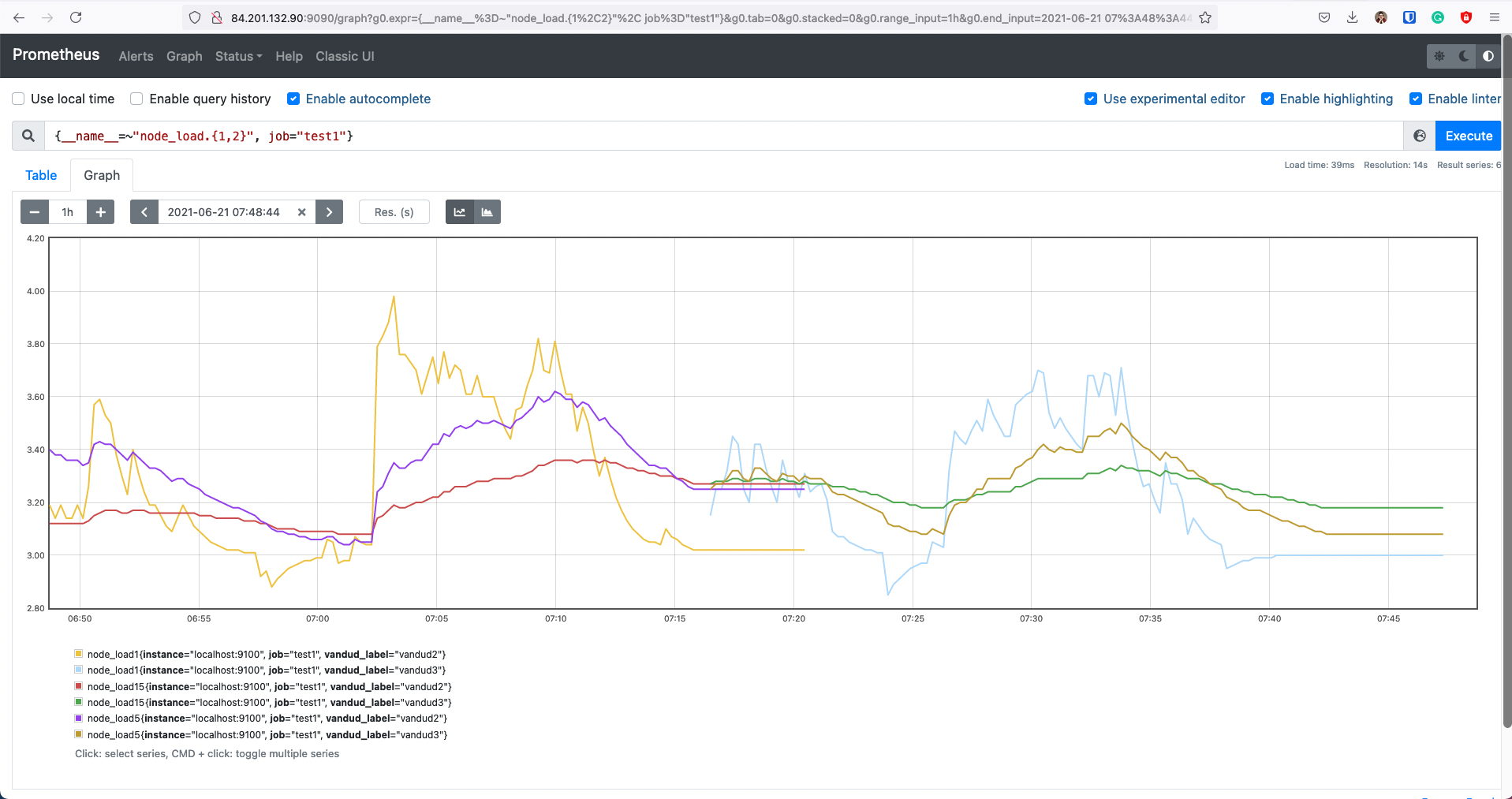
Имя метрики не может одним из этих слов:
- bool
- on
- ignoring
- group_left
- group_right
on{} # Bad!
Обходной путь - использовать лейбл __name__ (если уж очень нужны метрики с такими именами)
Range Vector Selectors
Range Vector selection работает точно так же как и instant vector selection, только возвращается массив значений вместо одного значения
В квадратных скобках указывается за какой промежуток нужно выбрать значения
http_requests_total{job="prometheus"}[5m] # за последние 5 минут
Time Durations
Диапазон указывается числом с приставкой (unit):
-
ms- milliseconds -
s- seconds -
m- minutes -
h- hours -
d- days - assuming a day has always 24h -
w- weeks - assuming a week has always 7d -
y- years - assuming a year has always 365d
Эти юниты (единицы измерения) можно комбинировать, конкатенируя их (1h20m30s), но юниты должны идти от большего к меньшему и могут встречаться лишь однажды (то есть нельзя 10h2h)
Offset modifier
offset позволяет сдвинуть таймсерию на указанное время назад и получить значение метрики из прошлого
http_requests_total offset 5m
Важно отметить что модификатор offset всегда должен идти после селектора
То есть это валидно:
sum(http_requests_total{method="GET"} offset 5m) // GOOD.
А это нет:
sum(http_requests_total{method="GET"}) offset 5m // INVALID.
Пример, питимунтный диапазон неделю назад:
rate(http_requests_total[5m] offset 1w)
Задавая отрицательный offset можно двигаться вперед во времени
Но для этого нужно включить этот функционал опцией --enable-feature=promql-negative-offset
@ modifier
Позволяет изменить evaluation time для конкретного instant или range vector в запросе
В векторе будут значения на момент времени указанный через @ в timestamp
Другими словами этот модификатор позволяет вернуть значение метирки на конкретный момент времени
Но его тоже нужно включать опцией --enable-feature=promql-at-modifier
И он так же должен следовать за селектором
sum(http_requests_total{method="GET"} @ 1609746000) // GOOD.
sum(http_requests_total{method="GET"}) @ 1609746000 // INVALID.
Работает и с range vectors
От указанного таймстемпа отступит указанное количество времени и покажет значения которые входят в диапазон между timestamp и timestamp-period
В следующих двух примерах это так же видно
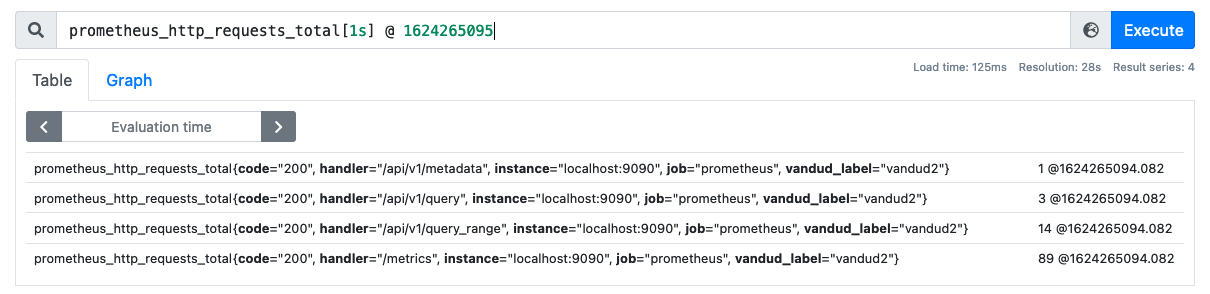

At модификатор можно комбинировать с offset
Не важно в каком порядке
offset будет применяться относительно timestamp
Запросы ниже вернут одно и то же
# offset after @
http_requests_total @ 1609746000 offset 5m
# offset before @
http_requests_total offset 5m @ 1609746000
Так же можно использовать функции start() и end()
Subquery
Подзапрос позволяет запустить мгновенный (istant) запрос для заданного диапазона и разрешения (resolution)
Результат подзапроса это range vector
instant_query [<range>:<resolution>]
Пример
quantile_over_time(0.95, rate(node_network_receive_bytes_total[5m])[1h:1m])
Comments
Комменты начинаются с решетки, коммент - вся строка
# This is a comment
Gotchas
https://prometheus.io/docs/prometheus/latest/querying/basics/#gotchas
Querying/Operators
Язык запросов поддерживает логические и арифметические операторы
Arithmetic binary operators
-
+- addition -
-- subtraction -
*- multiplication -
/- division -
%- modulo -
^- power/exponentiation
Их можно указывать между scalar/scalar, vector/scalar, и vector/vector парами
(vector - instant vector)
При vector/scalar оператор применяется к каждому элементу вектора и числу
При vector/vector оператор применяется к каждому элементу из левого вектора и сответствующему из правого (матчинг по лейблам, лейблы должны совпадать полностью)
Результатом становится результирующий вектор без имени
Несовпавшие элементы отбрасываются
Storage
Прометеус включает в себя локальную TSDB на диске
Но также может интегрироваться с remote стораджами
Local storage
TSDB хранит данные в кастомном высокоэффективном формате на локальном диске
Группирует блоки данных по два часа
Каждый двухчасовой блок состоит из директории которая хранит:
- Поддиректория с чанками данных для этого промежутка времени
- Файл с метаданными
- Индексный файл (который индексирует имена метрик и лейблы в таймсерии из поддериктории chunks)
Сэмплы в папке chunks сгруппированы в один или более файл размером до 512М каждый
Когда таймсерии удаляются через API, команда удаления записывается в tombstone файл (вместо немедленного удаления данных /querying/api/#delete-series) до следующего сжатия (compaction)
Текущий двухчасовой блок данных хранится в памяти и не является полностью постоянным. WAL (write ahead log) защитит от потери данных из памяти (при рестарте), этот лог может быть проигран (replayed) для восстановления данных
WAL файлы хранятся в папке wal сегментами по 128M. В них хранятся сырые данные, которые не могут быть сжаты и их размер значительно больше обычных блоков данных
Хранится не менее трех wal-файлов, высоконагруженные серверы могут иметь больше трех чтобы уместить двухчасовой период
./data
├── 01BKGV7JBM69T2G1BGBGM6KB12
│ └── meta.json
├── 01BKGTZQ1SYQJTR4PB43C8PD98
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── 01BKGTZQ1HHWHV8FBJXW1Y3W0K
│ └── meta.json
├── 01BKGV7JC0RY8A6MACW02A2PJD
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── chunks_head
│ └── 000001
└── wal
├── 000000002
└── checkpoint.00000001
└── 00000000
Прометеус не кластеризуется и не реплицируется, поэтому с ним нужно обходиться как с single node database
Рекомендуется использовать raid и snapshots
При правильной архитектуре данные можно хранить годами
Как альтернатива может быть использован какой-либо external storage через remote read/write API
Compaction
Двухчасовые блоки компануются в фоне в долгие блоки данных
У Прометеуса есть несколько флагов для конфигурирования локального хранилища
Вот наиважнейшие из них:
-
--storage.tsdb.path- Путь куда будет записываться база данных. По умолчаниюdata/ -
--storage.tsdb.retention.time- Когда удалять старые данные. Defaults to 15d -
--storage.tsdb.retention.size- [EXPERIMENTAL] Размер удерживаемых данных. Сначала удаляются более старые данные. Defaults to 0 or disabled. Units supported: B, KB, MB, GB, TB, PB, EB. Ex: "512MB" -
--storage.tsdb.retention- Deprecated in favor ofstorage.tsdb.retention.time -
--storage.tsdb.wal-compression- Включает сжатие wal. В зависимости от твоих данных может уменьшить вдвое размер данных с низкой нагрузкой на процессор. Включено по умолчанию начиная с 2.20.0 версии (это нужно учитывать если захочется задаунгрейдить пром до версии без этой функции (более старый чем 2.11.0 не сможет понять wal-файл, и wal придется удалить))
Prometheus хранит 1-2 байта на сэмпл. Поэтому для расчета того сколько дискового пространства потребуется для сервера, нужно воспользоваться этой формулой:
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample
Чтобы снизить размер поглощаемых данных можно снизить количество таймсерий (убавить целей или убавить таймсерий на цель), или можно увеличить scrape interval
Если локальный сторадж повредился по каким-то причинам, то лучшая стратегия это выключить prometheus и удалить storage directory, также можно попробовать удалить только какой-то конкретный блок данных или wal
Этот метод имеет место быть потому что Прометей не годится для длительного хранения данных, внешние решения сделают это лучше и надежнее
Если одновременно указаны и time и size retention, то будет использован тот кто сработает первее
Блоки удаляются целиком за раз после того как их срок действия полностью истек (поэтому это может занять до двух часов)
Remote storage integrations
Локальный сторадж имеет ограничения, поэтому вместо того чтобы решать проблемы кластеризации, прометеус предоставляет интерфейс для интеграции с remote storages
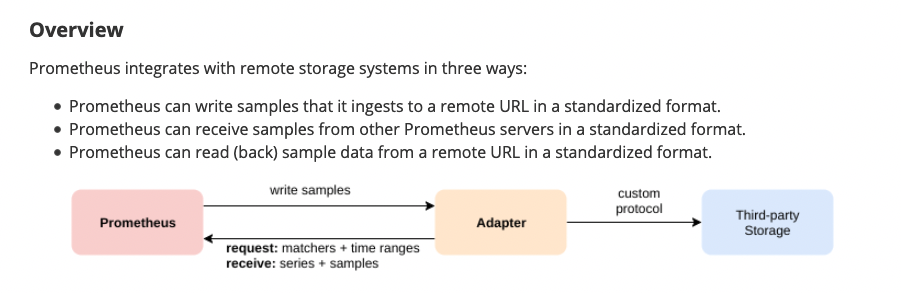
Чтобы включить приемник (receiver) нужно указать флаг --enable-feature=remote-write-receiver, тогда дефолтный эндпоинт для remote write будет /api/v1/write
Note that on the read path, Prometheus only fetches raw series data for a set of label selectors and time ranges from the remote end. All PromQL evaluation on the raw data still happens in Prometheus itself. This means that remote read queries have some scalability limit, since all necessary data needs to be loaded into the querying Prometheus server first and then processed there. However, supporting fully distributed evaluation of PromQL was deemed infeasible for the time being.
Backfilling for Recording Rules
Когда создается новое recording rules, для него еще нет исторических данных, они появляются со временем
Утилита promtool позволяет сгенерировать исторические данные для правила
$ promtool tsdb create-blocks-from rules --help
Добавил правило
$ cat rule
groups:
- name: example
rules:
- record: job:load_average_1:rate
expr: rate(node_load1[60m])
Данных пока нет

$ sudo !!
sudo promtool tsdb create-blocks-from rules --start 1624547613 --end 1624554804 --url http://84.201.175.11:9090 --output-dir=/var/lib/prometheus/metrics2 /etc/prometheus/rule
level=info backfiller="new rule importer from start" 24Jun2115:13UTC=" to end" 24Jun2117:13UTC=(MISSING)
level=info backfiller="processing group" name=/etc/prometheus/rule;example
level=info backfiller="processing rule" id=0 name=job:load_average_1:rate
И данные появились
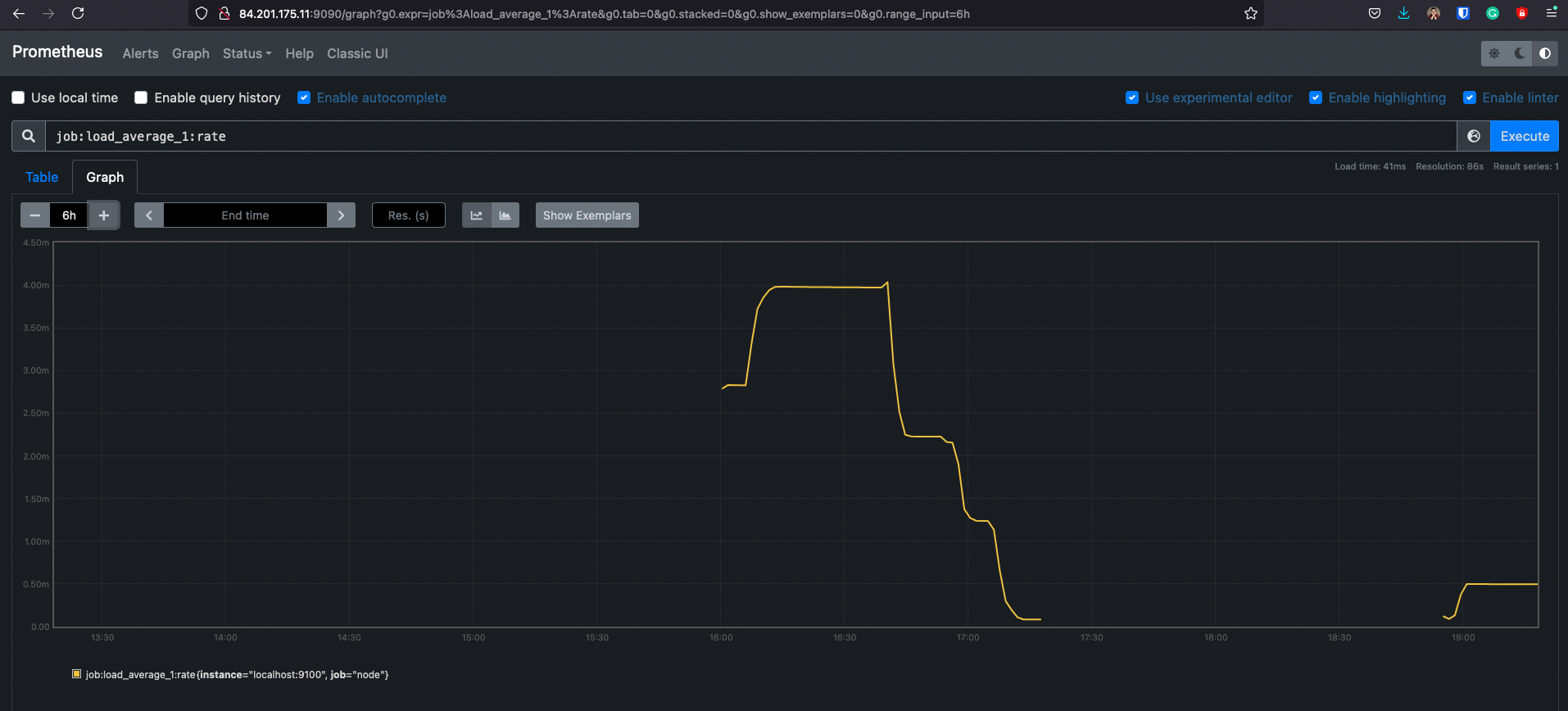
Но с этим нужно быть аккуратным
https://prometheus.io/docs/prometheus/latest/storage/#usage-0
Federation
Федерация позволяет скрейпить выбранные таймсерии другим прометеус сервером
Use cases
Обычно федерация используется для масштабируемых сетапов или для переноса связанных метрик из одного прометеуса в другой
Hierarchical federation
Иерархическая федерация позволяет масштабироваться до сред с десятками ДЦ и миллионами нод
В таком случае топология похожа на дерево, где наверху находятся high-level prometheus собирающие агрегированные данные и имеющие большое количество подчиненных серверов
Низкоуровневые сервера могут собирать и хранить высокоточные данные, и отправлять вышестоящему серверу обработанные
Тогда у нас будет общая картина со всех ДЦ в одном главном прометеусе, и высокоточная картина в каждом ДЦ по отдельности
Cross-service federation
Кросс-сервисная федерация позволяет прометеусу собирать данные из другого прометеуса
Таким образом можно настроить алертинг и запросинг из одного прометеуса по данным сразу из двух прометеусов
Configuring federation
Любой прометеус сервер дает доступ к данным по эндпоинту /federate

Чтобы настроит федерацию, нужно указать серверу назначения что нужно скрейпить метрики с сервера источника с эндпоинта /federate
Также нужно указать honor_labels чтобы сервер назначения не перезаписывал лейблы
Пример конфига
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
static_configs:
- targets:
- 'source-prometheus-1:9090'
- 'source-prometheus-2:9090'
- 'source-prometheus-3:9090'
HTTP SD
Прометеус предоставляет http service discovery который дополняет поддерживаемые sd механизмы и является альтернативой для file based sd
Comparison between File-Based SD and HTTP SD
| Item | File SD | HTTP SD |
|---|---|---|
| Event Based | Yes, via inotify | No |
| Update frequency | Instant, thanks to inotify | Following refresh_interval |
| Format | Yaml or JSON | JSON |
| Transport | Local file | HTTP/HTTPS |
| Security | File-Based security | TLS, Basic auth, Authorization header, OAuth2 |
inotify - функционал ядра позволяющий приложениям подписываться на события связанные с файлами
HTTP SD сервис нужно писать самостоятельно на основе этой доки
https://prometheus.io/docs/prometheus/latest/http_sd/
Management API
Прометеус предоставляет набор APIs для упрощения автоматизации и интеграции
Возвращают 200 когда все ок доступны из коробки
GET /-/healthy
GET /-/ready
Включаются флагом --web.enable-lifecycle
PUT /-/reload # SIGHUP
POST /-/reload
PUT /-/quit # SIGTERM
POST /-/quit
Disabled Features
Список выключенных по умолчанию фич
Kоторые включаются через ключ --enable-feature=feature1,feature2:
--enable-feature=promql-at-modifier - Позволяет указать таймстемп на который нужно обсчитать запрос--enable-feature=expand-external-labels - Заменяет ${var} или $var в external_labels на текущие переменные окружения--enable-feature=promql-negative-offset - Позволяет перемещаться по таймсерии в будущее чтобы делать предикты--enable-feature=remote-write-receiver - Разрешает remote write реквесты от других прометеусов--enable-feature=exemplar-storage - /disabled_features/#exemplars-storage