VictoriaMetrics
Конспект доки
- Cluster VictoriaMetrics
- vmauth
- vmagent
- vmalert
- Тесты для VictoriaMetrics
- Setup
- Kubernetes Monitoring
Cluster VictoriaMetrics
Фишки
- Может все что может single node версия
- Производительность и расширяемость в ширину
- Поддерживает независимые неймспейсы для данных (aka multi-tenancy)
- Поддерживает репликацию
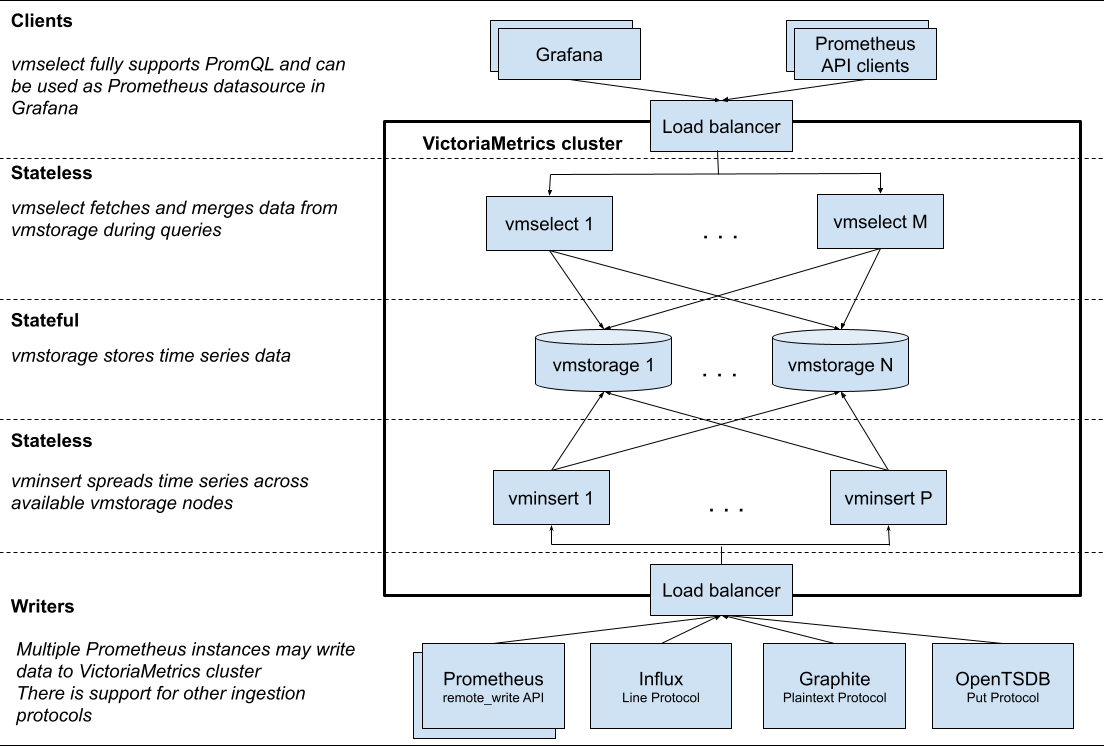
Обзор архитектуры
Кластер состоит из следующих сервисов:
- vmstorage - хранит данные
- vminsert - принимает данные и распределяет их по сторадж-нодам основываясь на хэше от имени метрики и всех ее лейблов
- vmselect - достает данные со стораджей
Каждый сервис может скейлиться независимо от остальных
Стораджи не знают друг о друге и никак друг с другом не коммуницируют, это упрощает авэйлабилити, расширяемость и обслуживаемость
Селекты поддерживают promql и могут быть использованы как prometheus datasource в графане
Мультитенантность
Тенанты определяются с помощью accountID или accountID:projectID, которые находятся внутри запроса
-
accountID/projectIDэто 32 битное целое. Projectid может быть опущен, тогда автоматом будет назначен projectid=0. Дополнительная информация про account или project хранится в отдельной реляционной базе и управляется через vmauth или vmgateway - Тенанты создаются автоматом когда в указанный тенантайди впервые кладуются данные
- Производительность базы не зависит от количества тенантов, она зависит от количества активных метрик во всех тенантах. Метрика считается активной если последний доступ к ней был менее часа назад (если положили или запросили менее часа назад)
- Нельзя сделать один кросстенантный запрос
Cluster setup
Минимальный кластер это
- 1 storage с флагами
-retentionPeriodи-storageDataPath - 1 insert с флагом
-storageNode=<vmstorage_host> - 1 select с флагом
-storageNode=<vmstorage_host>
Соответственно вышеуказанные флаги являются обязательными
vmauth или какой-либо http-loadbalancer ставится перед vmselect/vminsert нодами
Настроить балансер можно основываясь на url-format
Переменные окружения
Каждый флаг может быть задан через перменные окружения
- Должен быть установлен флаг
-envflag.enable - Каждая точка в имени флага должна быть заменена на подчеркивание (был флаг
-insert.maxQueueDuration <duration>стала переменнаяinsert_maxQueueDuration=<duration>) - Повторяющиеся флаги нужно объединить в одну переменную (было два флага
-storageNode <nodeA> -storageNode <nodeB>стала одна переменнаяstorageNode=<nodeA>,<nodeB>) - С помощью флага
-envflag.prefixможно задать префикс для переменных окружения
Monitoring
Каждый компонент отдает метрики в prometheus-совместимом формате на эндпоинте /metrics
Есть официальный и неофициальный дашборды для графаны
Алерты рекомендуется брать из этого конфига
Readonly mode
Стораджи автоматом переходят в ридонли режим когда в -storageDataPath остается мало места, а именно когда его меньше чем указано в -storage.minFreeDiskSpaceBytes
Инсерты в таком случае перестают слать данные в этот сторадж и шлют их в оставшиеся
URL format
Урл для вставки выглядит так - http://<vminsert>:8480/insert/<accountID>/<suffix>, где:
-
<accountID>- 32-ух битное целое обозначающее неймспей (aka тенант). Возможно также использовать вариант -accountID:projectID, где projectID тоже просто число. Если projectID нет, то он равен 0 -
<suffix>- может иметь следующие значения:-
datadog/api/v1/series- не интересно -
influx/writeиinflux/api/v2/write- не интересно -
opentsdb/api/put- не интересно -
prometheusиprometheus/api/v1/write- для вставки данных через Prometheus remote write API -
prometheus/api/v1/import- для импорта данных полученных через/select/<accountID>/prometheus/api/v1/exportу vmselect'а -
prometheus/api/v1/import/native- почти то же самое что выше -
prometheus/api/v1/import/csv- почти то же самое что выше -
prometheus/api/v1/import/prometheus- для импорта метрик в формате OpenMetrics
-
Урл для запросов выглядит так - http://<vmselect>:8481/select/<accountID>/prometheus/<suffix>, где:
-
<accountID>- описано выше -
<suffix>- может иметь следующие значения:-
api/v1/query- PromQL instant query -
api/v1/query_range- PromQL range query -
api/v1/series- series query -
api/v1/labels- возвращает лейблы -
api/v1/label/<label_name>/values- возвращает значения по переданному<label_name> -
federate- возвращает зафедерейтеные метрики -
api/v1/export- экспортит данные в JSON -
api/v1/export/native- экспортит данные в бинарном формате виктории. Потом эти данные могут быть импортированы в другую викторию черезapi/v1/import/native -
api/v1/export/csv- экспорт в CSV -
api/v1/series/count- возвращает общее количество time series -
api/v1/status/tsdb- статистика по TSDB -
api/v1/status/active_queries- текущие запросы -
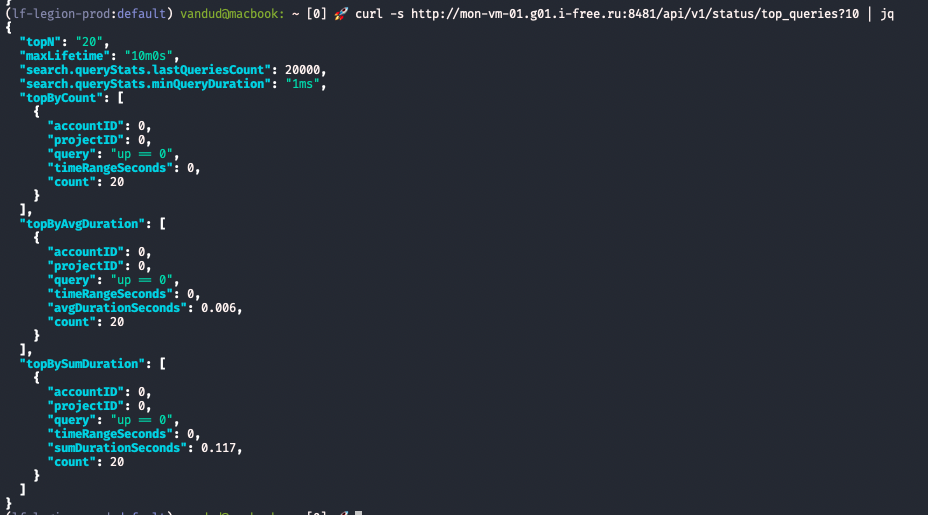
api/v1/status/top_queries- частые и долгие запросы
-
Урл для Graphite Metrics API - http://<vmselect>:8481/select/<accountID>/graphite/<suffix>, где все не интересно:
-
<accountID>- описано выше -
<suffix>- может иметь следующие значения:-
render- не интересно -
metrics/find- не интересно -
metrics/expand- не интересно -
metrics/index.json- не интересно -
tags/tagSeries- не интересно -
tags/tagMultiSeries- не интересно -
tags- не интересно -
tags/<tag_name>- не интересно -
tags/findSeries- не интересно -
tags/autoComplete/tags- не интересно -
tags/autoComplete/values- не интересно -
tags/delSeries- не интересно
-
Урл с простым Web UI - http://<vmselect>:8481/select/<accountID>/vmui/
Урл со статистикой по запросам сквозь все неймспейсы - http://<vmselect>:8481/api/v1/status/top_queries
Урл для удаления тайм серий - http://<vmselect>:8481/delete/<accountID>/prometheus/api/v1/admin/tsdb/delete_series?match[]=<timeseries_selector_for_delete>. Это нельзя делать на регулярной основе, чисто чтобы исправлять ошибки когда заинджестил что-то не то
Пример удаления
vandud@macbook: ~ [0] ? curl -s 'http://mon-vm-01.g01.i-free.ru:8481/select/1/prometheus/api/v1/query_range?query=node_load1\{instance="mon-vm-03.g01.i-free.ru:9100"\}&start=1659557812.652&end=1659559128.166' | jq
{
"status": "success",
"isPartial": false,
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "node_load1",
"instance": "mon-vm-03.g01.i-free.ru:9100",
"job": "monitoring"
},
"values": [
[
1659557812.652,
"0.06"
],
[
1659558112.652,
"0.04"
],
[
1659558412.652,
"0.2"
],
[
1659558712.652,
"0.01"
],
[
1659559012.652,
"0.06"
]
]
}
]
}
}
vandud@macbook: ~ [0] ? curl -s 'http://mon-vm-01.g01.i-free.ru:8481/delete/1/prometheus/api/v1/admin/tsdb/delete_series?match[]=node_load1\{instance="mon-vm-03.g01.i-free.ru:9100"\}'
vandud@macbook: ~ [0] ? curl -s 'http://mon-vm-01.g01.i-free.ru:8481/select/1/prometheus/api/v1/query_range?query=node_load1\{instance="mon-vm-03.g01.i-free.ru:9100"\}&start=1659557812.652&end=1659559128.166' | jq
{
"status": "success",
"isPartial": false,
"data": {
"resultType": "matrix",
"result": []
}
}
vmstorage предоставляет следующие HTTP эндпоинты на 8482 порту:
-
/internal/force_merge- запускает forced compactions на выбранной vmstorage ноде -
/snapshot/create- делает снапшот, который кладется в<storageDataPath>/snapshots, снапшоты можно бэкапить -
/snapshot/list- список снапшотов -
/snapshot/delete?snapshot=<id>- удалить снапшот -
/snapshot/delete_all- удалить все снапшоты
Cluster resizing and scalability
Производительность и вместительность кластера можно увеличивать двумя способами:
- добавляя ресурсы существующим нодам (вертикальное масштабирование)
- увеличивая количество нод (горизонтальное масштабирование)
Подробнее тут https://docs.victoriametrics.com/Cluster-VictoriaMetrics.html#cluster-resizing-and-scalability
Updating / reconfiguring cluster nodes
vmselect, vminsert и vmstorage можно апдейтнуть плавно. Для этого надо засылать им SIGINT после замены бинаря (это же касает обновления конфига)
Cluster availability
- HTTP балансер должен прекращать слать трафик на неисправные vminsert/vmselect
- Кластер остается доступным пока хотя бы один сторадж жив
- vminsert'ы рероутят трафик с нездоровых стораджей на здоровые
- vmselect'ы продолжают выдавать частичные ответы пока жив хотя бы один сторадж. Если консистентность важнее доступности то можно запретить частичные ответы через флаг
-search.denyPartialResponseу vmselect'a (или можно засылать аргументdeny_partial_response=1в запросе)
vmselect не поддерживает частичные ответы на эндпоинтах которые отдают сырые данные (например /api/v1/export*) потому что обычно ожидается что там будут полные данные
Для пущей надежности можно настроить data replication
Capacity planning
VictoriaMetrics использует меньше ресурсов чем конкурирующие решения (Prometheus, Cortex, etc)
Кол-во потребляемых ресурсов зависит от от профиля нагрузки (сколько таймсерий, какой churn rate, какого типа запросы прилетают, количество запросов, etc)
Рекомендуется строить тестовый кластер на продовых нагрузках и отлаживать это все по ходу дела (все сервисы кластера предоставляют метрики)
Количество диска для указанного -retentionPeriod так же можно понять по тестовому кластеру (например если на тестовом стенде за день набралось 10Gb данных, то если мы захотим хранить 100 дней то 10 надо умножить на 100, получится 1Тб диска)
Рекомендуется оставить свободными 50% памяти и процессора чтобы кластер мог безопасно переживать всплески нагрузки
Так же рекомендуется иметь в запасе 20% диска
Советы:
- репликация увеличивает кол-во необходимых ресурсов для кластера потому что vminsert'у приходится складывать один и тот же сэмпл в N стораджей, а vmselect'у приходится постоянно дедуплицировать данные со стораджей (для увеличения производительности с сохранением надежности можно переложить реплицирование на уровень ниже (например делать реплицирование на уровне системы хранения))
- большой кластер из мелких нод лучше чем маленький кластер из жирных нод. Если мы теряем 1 ноду из 10 нодового кластера то нагрузка на оставшиеся повысится всего на 11%, если мы теряем 1 ноду из 3 нодового кластера то нагрузка на оставшиеся вырастет на 50%, это нужно учитывать потому что оставшиеся ноды могут не выдержать повышения нагрузки и кластер может упасть целиком
- чтобы увеличить вместимость активных таймсерий нужно увеличивать ноды вверх или кластер вширь
- медленность запросов может быть решена увеличением cpu на vmselect'ах
- если нужно обрабатывать запросы с высокой скоростью то можно увеличить количество vmselect'ов
- по умолчания vminsert сжимает данные перед отправкой в сторадж для уменьшения нагрузки на сеть, в определенных случаях выгоднее выключить сжатие с помощью флага
-rpc.disableCompression(тогда cpu на vminsert'ах будет потребляться меньше) - аналогично сжимает данные vmstorage перед отправкой их на vmselect и аналогично можно снизить потребление cpu на vmstorage с помощью флага
-rpc.disableCompression
Resource usage limits
По умолчания компоненты кластера настроены на оптимальную работу при типичных нагрузках. В некоторых случаях может потребоваться ограничение потребления некоторых ресурсов. Далее будут рассмотрены флаги для ограничения потребления ресурсов:
-
-memory.allowedPercentи-search.allowedBytesограничивают потребление памяти под различные внутренние кэши, доступны во всех трех компонентах кластера (vminsert, vmstorage, vmselect), но они не ограничивают дополнительное потребление памяти для выполнения запросов -
-search.maxUniqueTimeseriesна vmselect'е ограничивает количество уникальных таймсерий которые могут быть найдены и обработаны в рамках одного запроса. С vmselect'а этот параметр проксируется на vmstorage -
-search.maxQueryDurationна vmselect'е ограничивает длительность выполнения одного запроса, когда запрос выполняется дольше то он завершается и это позволяет экономить cpu и memory при выполнении неожиданно больших и сложных запросов -
-search.maxConcurrentRequestsна vmselect'е ограничивает количество параллельно обрабатываемых запросов на одной vmselect-ноде, большое количество параллельно обрабатываемых запросов увеличивает потребление памяти на vmselect'ах и vmstorage. Например если один запрос требует 100Mb дополнительной памяти, то 100 параллельных таких запросов потребуют 10Gb дополнительной памяти. Лучше ограничивать параллельность, запросы сверх лимита встают в очередь и ждут когда дойдет очередь до их выполнения, у vmselect'ов есть флаг-search.maxQueueDurationкоторый ограничивает длительность ожидания запроса в очереди -
-search.maxSamplesPerSeriesна vmselect'ах ограничивает количество семплов на таймсерию которые может обработать запрос. vmselect последовательно обрабатывает каждый сэмпл из найденной таймсерии на протяжении запроса (таймсерия распаковывается и кладется в память, после чего для распаковынных данных применяется функция из запроса). Этот флаг позволяет ограничить потребление памяти на vmselect'ах -
-search.maxSamplesPerQueryна vmselect'ах ограничивает кол-во сэмплов на весь запрос, позволяет ограничить потребление cpu -
-search.maxSeriesна vmselect'ах ограничивает количество таймсерий которые будут доступны на эндпоинте/api/v1/series(он часто используется графаной для auto-completion метрик), запросы на этот эндпоинт могут отбирать много cpu у vmstorage и vmselect когда в хранилище много метрик или когда high churn rate (затестил, работает так что если на запрос должно вернуть больше айтемов чем указано в лимите, то запрос фейлится) -
-search.maxTagKeysна vmstorage ограничивает кол-во айтемов на эндпоинте/api/v1/labels-search.maxTagValuesна vmstorage ограничивает кол-во айтемов на эндпоинте/api/v1/label/.../values(эти эндпоинты часто используются графаной как и в примере выше) Например вот такие значения-search.maxTagKeys 10 -search.maxTagValues 20приводят к вот такому результату? curl -s http://mon-vm-02.g01.i-free.ru:8481/select/0/prometheus/api/v1/labels | jq { "status": "success", "isPartial": false, "data": [ "__name__", "address", "alertgroup", "alertname", "alertstate", "bios_date", "bios_vendor", "bios_version", "branch", "broadcast" ] } ? curl -s http://mon-vm-02.g01.i-free.ru:8481/select/0/prometheus/api/v1/label/address/values | jq { "status": "success", "isPartial": false, "data": [ "00:00:00:00:00:00", "02:42:12:7a:d4:c2", "02:42:2b:18:51:ef", "02:42:2d:55:16:71", "02:42:3b:88:ee:ef", "02:42:44:fd:51:8c", "02:42:49:06:bb:d3", "02:42:72:54:87:57", "02:42:83:01:2e:6c", "02:42:93:29:1b:95", "02:42:9d:9d:4b:10", "02:42:af:5c:44:16", "02:42:df:bf:b1:58", "0e:c2:e6:fb:3c:e7", "2e:c8:78:38:67:9a", "3a:48:37:8b:2d:74", "42:73:3a:c9:e0:8c", "52:54:00:25:d1:60", "52:54:00:27:dd:62", "52:54:00:33:15:55" ] } -
-storage.maxDailySeriesи-storage.maxHourlySeriesна vmstorage ограничивают кол-во таймсерий которые могут быть добавлены в хранилище за 24 часа или за час (это позволяет бороться с high churn rate
Multi-level cluster setup
Одни vmselect'ы могут обращаться к другим vmselect'ам если они запущены с флагом -clusternativeListenAddr, то же самое с vminsert'ом
Replication and data safety
По умолчанию victoriametrics полагается на надежность хранилища которое выбрано для хранения данных и прописано в -storageDataPath, но так же она поддерживает репликацию на уровне приложения
С помощью ключа -replicationFactor=N на vminsert'ах можно задать количество хранимых копий сэмплов (на разных стораджах). Это гарантирует что все сохраненные данные будут оставаться доступными для запросов если вплоть до N-1 vmstorage'й будет недоступно (ReplicationFactor - 1 = UnavailableNodes)
Кластер должен содержать как минимум 2*N-1 стораджей, где N - фактор репликации
Кластер хранит таймстемпы с миллисекундным разрешением, поэтому флаг -dedup.minScrapeInterval=1ms может быть добавлен на vmselect'ы для дедуплицирования сэмплов получаемых со стораджей
Но надо помнить что реплика это не бэкап, поэтому не забывай про бэкапы
Репликация увеличивает потребление ресурсов, потому что vminsert'у нужно клать две копии в два разных стораджа, а vmselect'у нужно дедуплицировать полученные данные
Для сокращения этих издержек можно передать репликацию на уровень ниже (на систему хранения предоставляющую диск для ВМ)
Deduplication
VictoriaMetrics выбирает сэмпл с наибольшим таймстемпом из сэмплов попадающих в интервал заданный в -dedup.minScrapeInterval. То есть из таймсерии на каждый такой интервал выпадает один сэмпл (если спорный момент когда одинаковый таймстемп у двух сэмплов то выбирается случайный)
Рекомендуется задавать -dedup.minScrapeInterval равным scrape_interval и scrape_interval рекомендуется иметь одинаковым на всех таргетах
Флаг -dedup.minScrapeInterval должен быть проставлен и на vmselect'ах и на vmstorage'ах потому что vmselect пытается лить одну метрику в один сторадж (в идеальных условиях все сэмплы определенной таймсерии будут лежать на одном сторадже), но это поведение может нарушиться если мы будем добавлять/убирать стораджи, если какой-то сторадж будет временно недоступен (зарестартится или произойдет какая-то авария) или на нужном сторадже кончится место, тогда vminsert выберет другой сторадж для этой метрики и часть сэмплов будет на одной ноде, часть на другой
Backups
Рекомендуется периодически делать бэкапы из снапшотов чтобы защититься от пользовательских ошибок таких как случайное удаление данных
Для создания бэкапа:
- Создай снапшот через API
root@mon-vm-02:~# curl -s http://localhost:8482/snapshot/create | jq { "status": "ok", "snapshot": "20220821113230-170D3C49F5660E08" } - Преврати снапшот в бэкап с помощью утилиты vmbackup
Получается бэкап storageDataPathroot@mon-vm-02:~# ./vmbackup-prod -storageDataPath /var/lib/vmstorage-data/ -snapshotName 20220821113230-170D3C49F5660E08 -dst fs:///tmp/test-vm-backuproot@mon-vm-02:~# du -hs /tmp/test-vm-backup/ 67M /tmp/test-vm-backup/ root@mon-vm-02:~# du -hs /var/lib/vmstorage-data/ 68M /var/lib/vmstorage-data/ - Удали снапшот
root@mon-vm-02:~# ls /var/lib/vmstorage-data/snapshots/ 20220821113215-170D3C49F5660E07 root@mon-vm-02:~# curl -s http://localhost:8482/snapshot/delete?snapshot=20220821113215-170D3C49F5660E07 | jq { "status": "ok" } root@mon-vm-02:~# ls /var/lib/vmstorage-data/snapshots/ root@mon-vm-02:~#
Все три пункта можно сделать одной командой
# ./vmbackup-prod -storageDataPath /var/lib/vmstorage-data/ -snapshot.createURL http://localhost:8482/snapshot/create -dst fs:///tmp/test-vm-backup2
Процесс бэкапирования не влияет на производительность кластера, поэтому бэкапы можно делать в любое удобное время
Чтобы восстановить из бэкапа нужно:
- Остановить сторадж
- Восстановить
vmrestore-prod -src fs:///tmp/test-vm-backup -storageDataPath /var/lib/vmstorage-data/ - Запустить сторадж
Profiling
Все компоненты кластера предоставляют хендлеры для профайлинга
-
/debug/pprof/heap- memory -
/debug/pprof/profile- cpu
root@mon-vm-02:~# wget http://localhost:8480/debug/pprof/profile
--2022-08-21 16:02:16-- http://localhost:8480/debug/pprof/profile
Resolving localhost (localhost)... ::1, 127.0.0.1
Connecting to localhost (localhost)|::1|:8480... failed: Connection refused.
Connecting to localhost (localhost)|127.0.0.1|:8480... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [application/octet-stream]
Saving to: ‘profile’
profile [ <=> ] 3.83K --.-KB/s in 0s
2022-08-21 16:02:46 (24.4 MB/s) - ‘profile’ saved [3919]
Грузится достаточно долго, этого пугаться не стоит
Далее полученный файл формата pprof можно как-то анализировать
Например:
root@mon-vm-02:~# go tool pprof -http=172.27.247.182:8080 profile # profile это имя файла который мы получили выше
vmalert
vmselect'у можно указать флаг -vmalert.proxyURL и тогда он сможет проксировать некоторые запросы на vmalert
Это нужно для Grafana Alerting UI и можно увидеть интрерфейс vmalert'a через vmselect
Описание доступных флагов у сервисов можно увидеть в хелпе по сервису
vmauth
vmauth это простой auth-proxy, router, и load balancer для VictoriaMetrics
Он читает креды из http-заголовка Authorization (поддерживаются Basic Auth, Bearer token и InfluxDB auth), матчит их с данными из конфига из флага -auth.config и проксирует входящие запросы на указанные в конфиге per-user url_prefix-auth.config может указывать на локальный файл или на http url
Quick start
Минимально достаточно запустить
/path/to/vmauth -auth.config=/path/to/auth/config.yml
vmauth повиснет на 8427 порту и будет роутить приходящие запросы на основе auth.conf
Порт может быть изменен флагом -httpListenAddr
Релоадить конфиг можно отправив процессу SIGHUP сигнал - kill -SIGHUP $MAINPID или сделав запрос на эндпоинт /-/reload
Docker имаджи доступны тут - https://hub.docker.com/r/victoriametrics/vmauth/tags
Load balancing
Каждый url_prefix в auth.config может содержать один урл или список урлов
Ниже видно, что можно сразу урл, а можно список урлов
users:
- bearer_token: "YYY"
url_prefix: "http://localhost:8428"
- username: "cluster-select-account-123"
password: "***"
url_prefix:
- "http://vmselect1:8481/select/123/prometheus"
- "http://vmselect2:8481/select/123/prometheus"
В случае если указан список, vmauth будет балансить запросы между указанными урлами в режиме round-robin
Это полезно для балансинга нагрузки между несколькими vmselect/vminsert
Auth config
-auth.config описывается следующим образом:
# Может быть указано произвольное количество username'ов
# Допустимо указывать несколько одинаковых имен пользователей, но пароли у них должны быть разные
# Такие username'ы могут различаться опцией 'name'
users:
# Запросы с заголовками 'Authorization: Bearer XXXX' и 'Authorization: Token XXXX' будут проксироваться на http://localhost:8428
# Например, http://vmauth:8427/api/v1/query отправится на http://localhost:8428/api/v1/query
- bearer_token: "XXXX"
url_prefix: "http://localhost:8428"
# Запросы с заголовком 'Authorization: Bearer YYY' будут проксироваться на http://localhost:8428
# И к каждому проксируемому запросу будет добавляться заголовок `X-Scope-OrgID: foobar`
- bearer_token: "YYY"
url_prefix: "http://localhost:8428"
headers:
- "X-Scope-OrgID: foobar"
# Пример использования пользователя
# Все запросы к http://vmauth:8427 с Basic Auth (username:password) будут проксироваться на http://localhost:8428
- username: "local-single-node"
password: "***"
url_prefix: "http://localhost:8428"
# Пример использования пользователя с extra_label team=dev.
# Все запросы к http://vmauth:8427 с Basic Auth (username:password) будут проксировать на http://localhost:8428 с аргументом запроса extra_label=team=dev
# Например, запрос к http://vmauth:8427/api/v1/query отправится на http://localhost:8428/api/v1/query?extra_label=team=dev
- username: "local-single-node"
password: "***"
url_prefix: "http://localhost:8428?extra_label=team=dev"
# Пример конфига с пользователем под неймспейс в VictoriaMetrics cluster
# Все запросы к http://vmauth:8427 с Basic Auth (username:password) будут балансироваться между указанными vmselect с указанием конкретного неймспейса
- username: "cluster-select-account-123"
password: "***"
url_prefix:
- "http://vmselect1:8481/select/123/prometheus"
- "http://vmselect2:8481/select/123/prometheus"
# Аналогичное тому что выше но с vminsert'ами
- username: "cluster-insert-account-42"
password: "***"
url_prefix:
- "http://vminsert1:8480/insert/42/prometheus"
- "http://vminsert2:8480/insert/42/prometheus"
# Единый пользователь для селектов и инсертов:
# - Запросы к http://vmauth:8427/api/v1/query, http://vmauth:8427/api/v1/query_range и http://vmauth:8427/api/v1/label/<label_name>/values
# будут проксироваться на следующие урлы в режиме round-robin:
# - http://vmselect1:8481/select/42/prometheus
# - http://vmselect2:8481/select/42/prometheus
# - Запросы к http://vmauth:8427/api/v1/write будут проксироваться на http://vminsert:8480/insert/42/prometheus/api/v1/write с заголовком "X-Scope-OrgID: abc"
- username: "foobar"
url_map:
- src_paths:
- "/api/v1/query"
- "/api/v1/query_range"
- "/api/v1/label/[^/]+/values"
url_prefix:
- "http://vmselect1:8481/select/42/prometheus"
- "http://vmselect2:8481/select/42/prometheus"
- src_paths: ["/api/v1/write"]
url_prefix: "http://vminsert:8480/insert/42/prometheus"
headers:
- "X-Scope-OrgID: abc"
Пример:
root@mon-vm-01:~# cat /etc/victoriametrics/vmauth.yaml
users:
- username: "test-user"
password: "test-password"
url_prefix: "http://localhost:8481"
Запускаем:
./vmauth-prod -eula -auth.config=/etc/victoriametrics/vmauth.yaml
Запрос без указания user/pass:
(ifree-test-k8s:default) vandud@macbook: ~ [0] ? curl 'http://mon-vm-01.g01.i-free.ru:8427/select/0/prometheus/api/v1/query_range?query=1&start=2022-08-31T02:20:00Z&end=2022-08-31T02:22:00Z&step=1m'
missing `Authorization` request header
Запрос с указанием user/pass:
(ifree-test-k8s:default) vandud@macbook: ~ [0] ? curl -s -u test-user:test-password 'http://mon-vm-01.g01.i-free.ru:8427/select/0/prometheus/api/v1/query_range?query=1&start=2022-08-31T02:20:00Z&end=2022-08-31T02:22:00Z&step=1m' | jq
{
"status": "success",
"isPartial": false,
"data": {
"resultType": "matrix",
"result": [
{
"metric": {},
"values": [
[
1661912400,
"1"
],
[
1661912460,
"1"
],
[
1661912520,
"1"
]
]
}
]
}
}
Этот конфиг может содержать плейсхолдеры вида %{ENV_VAR} в которые будут подставлены соответствующие переменные окружения. Это может быть полезно для подстановки секретов в конфиг
Security
Подразумевается что все сервисы расположены в приватной сети и доступны снаружи только сквозь vmauth
Нужно обязательно включать https, потому что иначе пропадает смысл аутентификации через Basic Auth
Флаги -tls* позволяют это сделать
-
-tls- включать ли TLS (aka HTTPS). Флаги-tlsCertFileи-tlsKeyFileдолжны быть проставлены если проставлен флаг-tls -
-tlsCertFile string- путь до файла с сертификатом. Рекомендуются ECDSA сертификаты вместо RSA, потому что RSA медленные -
-tlsKeyFile string- путь до файла с ключом
Как альтернатива можно поставить tls termination proxy перед vmauth
Рекомендуется защитить следующие эндпоинты через authKeys:
-
/-/reloadзащищается паролем через флаг-reloadAuthKeyи внешние пользователи не смогут триггерить релоад конфига -
/flagsзащищается паролем через флаг-flagsAuthkeyи внешние пользователи не смогут получить список флагов -
/metricsзащищается паролем через флагmetricsAuthkeyи внешние пользователи не смогут получить доступ к метрикам -
/debug/pprofзащищается паролем через флагpprofAuthKeyи внешние пользователи не смогут получить профилировачную информацию
Задаем пароль
/usr/local/bin/vmauth -reloadAuthKey reloadpassword -auth.config=/etc/vmauth/auth.yml
И дергаем эндпоинт с этим паролем
curl http://mon-vm-02.g01.i-free.ru:8427/-/reload?authKey=reloadpassword
Monitoring
vmauth предоставляет множество метрик в Prometheus exposition формате на эндпоинте /metrics
Среди них есть метрика vmauth_user_requests_total с лейблом username значение которого равно значению поля username из конфига
Пример:
? curl -s http://mon-vm-01.g01.i-free.ru:8427/metrics | grep vmauth_user_requests_total
vmauth_user_requests_total{username="test-user"} 2
Можно перекрыть username в лейбле с помощью опции name для username:
root@mon-vm-01:~# cat /etc/victoriametrics/vmauth.yaml
users:
- username: "test-user"
name: "not-test-user"
password: "test-password"
url_prefix: "http://localhost:8481"
root@mon-vm-01:~# curl -s http://mon-vm-01.g01.i-free.ru:8427/metrics | grep vmauth_user_requests_total
vmauth_user_requests_total{username="not-test-user"} 0
Эта метрика обнуляется после рестарта
Prifiling
vmauth предоставляет хэндлеры для сбора Go профилей:
- Memory profile - curl http://vmauth:8427/debug/pprof/heap > mem.pprof
- CPU profile - curl http://vmauth:8427/debug/pprof/profile > cpu.pprof
Команда для сбора CPU профиля сперва ждет 30 секунд и только потом возращает результат Собранные профили можно проанализировать утилитой https://github.com/google/pprof Файлы профилей не содержат сенсетивной информации поэтому их можно без страха шарить кому-то
Advanced usage
vmauth имеет еще массу различных флагов, актуальную справку по которым можно увидеть запустив vmauth -help
vmagent
vmagent это маленький но мощный агент который поможет тебе собирать метрики из разных источников и сохранять их в VictriaMetrics или каком-то другом Prometheus-compatible хранилище с поддержкой Prometheus remote_write протокола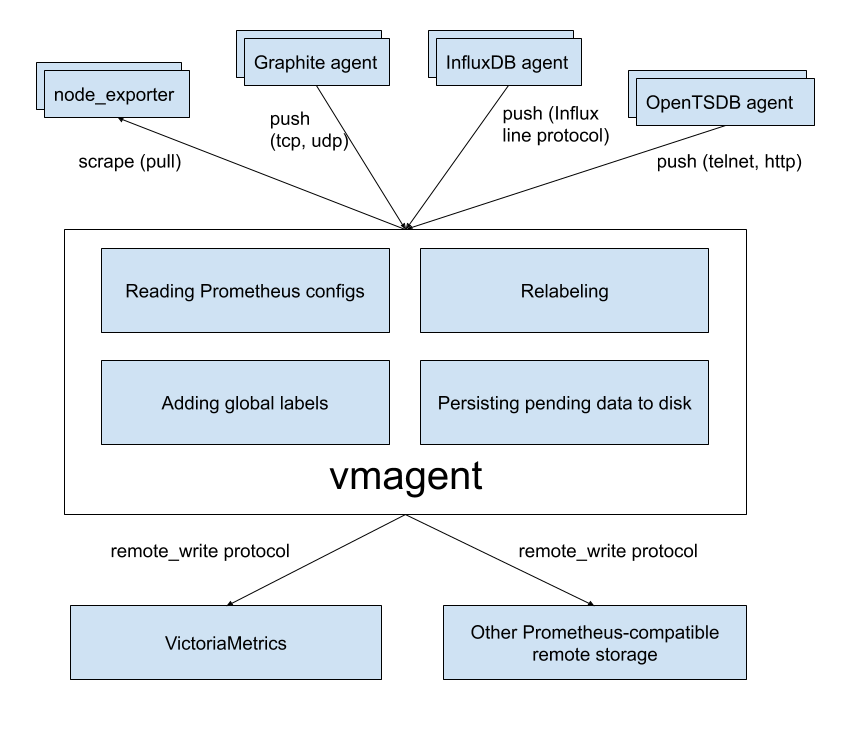
Motivation
vmagent появился потому что пока существовало роскошное хранилище метрик victoriametrics, пользователям также был необходим производительный и не требовательный к ресурсам сборщик метрик который бы складывал метрики в victoriametrics (вместо прожорливого prometheus'а)
Features
- может быть использовать как прямая замена прому для скрейпинга экспортеров
- может читать данные из кафки
- может писать данные в кафку
- может добавлять, удалять и изменять лейблы (relabeling), умеет фильтровать данные перед отправкой в сторадж
- умеет принимать данные через все протоколы поглощения которые поддерживает victoriametrics
- умеет реплицировать собранные метрики одновременно в несколько систем хранения
- нормально работает в условиях плохой связи с удаленным хранилищем. Если нет связи с хранилищем то он буфферизирует собранные данные в буффере указанном в
-remoteWrite.tmpDataPath. Как только связь с хранилищем будет восстановлена, тоvmagentсразу же зашлет все забуфферизированные данные туда. Максимальный размер буффера ограничивается параметром-remoteWrite.maxDiskUsagePerURL - по сравнения с prometheus использует меньше memory, cpu, disk io и network bandwidth
- скрейпинг таргетов может быть размазан на несколько агентов
- эффективно скрейпит жирные таргеты с миллионами таймсерий (например
/federateу прома) - позволяет справляться с high cardinality и high churn rate проблемами через различные ограничения
- может загружать scrape config'и из множества файлов
Quick Start
Скачай подходящий vmutils-* отсюда https://github.com/VictoriaMetrics/VictoriaMetrics/releases и вытащи оттуда бинарь vmagent'a
Базово запустить можно так
./vmagent-prod -remoteWrite.url http://localhost:8480/insert/0/prometheus/api/v1/write -promscrape.config /etc/victoriametrics/vmagent/config.yml
-
-promscrape.config- указываем путь до конфига (vmagent может обработать не все секции prometheus.yml, поэтому можно либо удалить из конфига нерабочие секции, либо добавить флаг-promscrape.config.strictParse=falseчтобы он их игнорил) -
-remoteWrite.urlпуть до хралища
Если скрейпить не надо, то можно запустить вообще с одной опцией
./vmagent-prod -remoteWrite.url http://localhost:8480/insert/0/prometheus/api/v1/write
Тогда агент сможет инджестить в себя пушинговые протоклы и пересылать данные дальше в указанное хранилище
How to push data to vmagent
vmagent поддерживает те же push-based протоколы что и VictoriaMetrics
- DataDog "submit metrics" API
- InfluxDB line protocol via
http://<vmagent>:8429/write - Graphite plaintext protocol if
-graphiteListenAddrcommand-line flag is set - OpenTSDB telnet and http protocols if
-opentsdbListenAddrcommand-line flag is set - Prometheus remote write protocol via
http://<vmagent>:8429/api/v1/write - JSON lines import protocol via
http://<vmagent>:8429/api/v1/import - Native data import protocol via
http://<vmagent>:8429/api/v1/import/native - Prometheus exposition format via
http://<vmagent>:8429/api/v1/import/prometheus - Arbitrary CSV data via
http://<vmagent>:8429/api/v1/import/csv
Configuration update
чтобы vmagent смог перечитать cli-флаги он должен быть рестартанут
vmagent имеет несколько способов перезагрузить конфиги из -promscrape.config, -remoteWrite.relabelConfig и -remoteWrite.urlRelabelConfig:
- можно отправить
SIGHUPkill -SIGHUP `pidof vmagent` - можно отправить запрос на
/http://vmagent:8429/-/reloadэндпоинт
Есть флаг -promscrape.configCheckInterval который позволяет указать vmagent'у что нужно периодически проверять не изменился ли конфиг и подгружать если изменился
Multitenancy
По умолчанию vmagent собирает данные без каких-либо tennant id и просто отправляет их в -remoteWrite.url
Подержка мультитенантности включается когда проставлен флаг -remoteWrite.multitenantURL
Этим флагом задается адрес vmselect'а, куда vmagent будет засылать метрики полученные через push-протокол или собранные с таргетов из конфига
API для пушинга доступен у агента на http://vmagent:8429/insert/<accountID>/..., полученные данные он перенаправит в <-remoteWrite.multitenantURL>/insert/<accountID>/prometheus/api/v1/write
Флаг -remoteWrite.multitenantURL может быть указан несколько раз, тогда агент зареплицирует данные во все указанные remoteWrite хранилища
Чтобы агент скрейпил таргеты и клал собранные данные у нужные неймспейсы нужно чтобы у таргетов был лейбл __tenant_id__ в котором должен быть указан tenantID. Значение этого лейбла будет подставляться в <-remoteWrite.multitnenatURL>/insert/<__tenant_id__>/prometheus/api/v1/write и метрики будут попадать в нужный namespace
Пример
Вот такой конфиг:
---
global:
scrape_interval: 1s
scrape_configs:
- job_name: monitoring
static_configs:
- targets:
- mon-vm-01.g01.i-free.ru:9100
labels:
__tenant_id__: 1
- job_name: mon-test-vms
static_configs:
- targets:
- mon-vm-02.g01.i-free.ru:9100
labels:
__tenant_id__: 2
Вот такая команда запуска:
vmagent-prod -promscrape.config /etc/victoriametrics/vmagent/config.yml -remoteWrite.multitenantURL http://localhost:8480
Получаем в каждом NS метрики по своему хосту:
vandud@macbook: ~ [0] ? curl -s http://mon-vm-03.g01.i-free.ru:8481/select/1/prometheus/api/v1/series?match[]=node_load1 | jq
{
"status": "success",
"isPartial": false,
"data": [
{
"__name__": "node_load1",
"job": "monitoring",
"instance": "mon-vm-01.g01.i-free.ru:9100"
}
]
}
vandud@macbook: ~ [0] ? curl -s http://mon-vm-03.g01.i-free.ru:8481/select/2/prometheus/api/v1/series?match[]=node_load1 | jq
{
"status": "success",
"isPartial": false,
"data": [
{
"__name__": "node_load1",
"job": "mon-test-vms",
"instance": "mon-vm-02.g01.i-free.ru:9100"
}
]
}
Если лейбла с tenantID нет, то данные кладутся в 0 неймспейс
How to collect metrics in Prometheus format
Файл из -promscrape.config читается не полностью, некоторые секции из него игнорируются
vmagent понимает только global и scrape_configs секции, а остальные игнорирует
Можно либо убрать лишние секции из конфига, либо добавить флаг -promscrape.config.strictParse=false который заставит vmagent'a их игнорировать
Пример запуска с невалидным конфигом
root@mon-vm-02:~# ./vmagent-prod -promscrape.config /etc/victoriametrics/vmagent/config.yml -remoteWrite.multitenantURL http://localhost:8480
2022-08-23T12:41:35.988Z info VictoriaMetrics/lib/logger/flag.go:12 build version: vmagent-20220808-173305-tags-v1.80.0-0-gad00f4aaa
2022-08-23T12:41:35.988Z info VictoriaMetrics/lib/logger/flag.go:13 command-line flags
2022-08-23T12:41:35.988Z info VictoriaMetrics/lib/logger/flag.go:20 -promscrape.config="/etc/victoriametrics/vmagent/config.yml"
2022-08-23T12:41:35.988Z info VictoriaMetrics/lib/logger/flag.go:20 -remoteWrite.multitenantURL="http://localhost:8480"
2022-08-23T12:41:35.988Z info VictoriaMetrics/app/vmagent/main.go:103 starting vmagent at ":8429"...
2022-08-23T12:41:35.988Z info VictoriaMetrics/app/vmagent/main.go:128 started vmagent in 0.000 seconds
2022-08-23T12:41:35.988Z info VictoriaMetrics/lib/httpserver/httpserver.go:94 starting http server at http://127.0.0.1:8429/
2022-08-23T12:41:35.988Z info VictoriaMetrics/lib/httpserver/httpserver.go:95 pprof handlers are exposed at http://127.0.0.1:8429/debug/pprof/
2022-08-23T12:41:35.989Z info VictoriaMetrics/lib/promscrape/scraper.go:106 reading Prometheus configs from "/etc/victoriametrics/vmagent/config.yml"
2022-08-23T12:41:35.991Z fatal VictoriaMetrics/lib/promscrape/scraper.go:109 cannot read "/etc/victoriametrics/vmagent/config.yml": cannot parse Prometheus config from "/etc/victoriametrics/vmagent/config.yml": cannot unmarshal data: yaml: unmarshal errors:
line 17: field storage not found in type promscrape.Config; pass -promscrape.config.strictParse=false command-line flag for ignoring unknown fields in yaml config
Пример запуска с ключом -promscrape.config.strictParse=false
root@mon-vm-02:~# ./vmagent-prod -promscrape.config /etc/victoriametrics/vmagent/config.yml -remoteWrite.multitenantURL http://localhost:8480 -promscrape.config.strictParse=false [9/973]
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/logger/flag.go:12 build version: vmagent-20220808-173305-tags-v1.80.0-0-gad00f4aaa
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/logger/flag.go:13 command-line flags
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/logger/flag.go:20 -promscrape.config="/etc/victoriametrics/vmagent/config.yml"
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/logger/flag.go:20 -promscrape.config.strictParse="false"
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/logger/flag.go:20 -remoteWrite.multitenantURL="http://localhost:8480"
2022-08-23T12:42:23.991Z info VictoriaMetrics/app/vmagent/main.go:103 starting vmagent at ":8429"...
2022-08-23T12:42:23.991Z info VictoriaMetrics/app/vmagent/main.go:128 started vmagent in 0.000 seconds
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/httpserver/httpserver.go:94 starting http server at http://127.0.0.1:8429/
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/httpserver/httpserver.go:95 pprof handlers are exposed at http://127.0.0.1:8429/debug/pprof/
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/promscrape/scraper.go:106 reading Prometheus configs from "/etc/victoriametrics/vmagent/config.yml"
2022-08-23T12:42:23.995Z info VictoriaMetrics/lib/promscrape/config.go:117 starting service discovery routines...
2022-08-23T12:42:23.995Z info VictoriaMetrics/lib/promscrape/config.go:123 started service discovery routines in 0.000 seconds
2022-08-23T12:42:23.997Z info VictoriaMetrics/lib/promscrape/scraper.go:403 static_configs: added targets: 2, removed targets: 0; total targets: 2
2022-08-23T12:42:24.699Z info VictoriaMetrics/lib/memory/memory.go:42 limiting caches to 5019416985 bytes, leaving 3346277991 bytes to the OS according to -memory.allowedPercent=60
2022-08-23T12:42:24.701Z info VictoriaMetrics/lib/persistentqueue/fastqueue.go:59 opened fast persistent queue at "vmagent-remotewrite-data/persistent-queue/1_5E2F0F84E74D5D64" with maxInmemoryBlocks=1200, it contains 0 pending bytes
2022-08-23T12:42:24.701Z info VictoriaMetrics/app/vmagent/remotewrite/client.go:169 initialized client for -remoteWrite.url="1:secret-url:2:0"
2022-08-23T12:42:24.724Z info VictoriaMetrics/lib/persistentqueue/fastqueue.go:59 opened fast persistent queue at "vmagent-remotewrite-data/persistent-queue/1_3B7269031AC653CF" with maxInmemoryBlocks=1200, it contains 0 pending bytes
2022-08-23T12:42:24.724Z info VictoriaMetrics/app/vmagent/remotewrite/client.go:169 initialized client for -remoteWrite.url="1:secret-url:1:0"
Важное отличие prometheus можно полностью сконфигурировать через конфиг, а vmagent'у в конфиге можно указать только таргеты которые нужно скрейпить, все остальное у vmagent'a конфигурируется либо через флаги либо через перменные окружения
Файл указанный в -promscrape.config может содержать %{ENV_VAR} плейсхолдеры в которые будут подставлены соответствующие переменные окружения
scrape_config enhancements
vmagent имеет дополнительные опции которые могут быть указаны в секции scrape_configs
-
headers- список http хедеров которые будут добавляться к запросам при скрейпинге. Например туда могут быть подставлены заголовки для аутентификации на экспортереscrape_configs: - job_name: custom_headers headers: - "TenantID: abc" - "My-Auth: TopSecret" -
disable_compression: true- выключает сжатие (по умолчанию запросы от агента сжимаются чтобы экономить трафик) (per job) -
disable_keepalive: true- выключает keep-alive (per-job) -
series_limit: N- ограничивает кол-во таймсерий которые могут соскрейплены с одного таргета -
stream_parse: true- для скрейпинга данных в режиме потока, это полезно когда экспортеры выдают гигантское кол-во метрик и скрейпинг может затягиваться -
scrape_align_interval: duration- не понял как это работает, подробности тут -
scrape_offset: duration- не понял как это работает, подробности тут -
relabel_debug: true- включает дебаг по релейблингу таргетов -
metric_relabel_debug: true- включает дебаг по релейблингу метрик
Loading scrape configs from multiple files
vmagent умеет загружать scrape конфиги из множества файлов указанных в секции scrape_config_files файла указанного в -promscrape.config
root@mon-vm-01:/etc/victoriametrics/vmagent# cat config.yml
scrape_configs:
- job_name: monitoring
static_configs:
- targets:
- mon-vm-03.g01.i-free.ru:8008
labels:
__tenant_id__: 1
scrape_config_files:
- scrape_config_files/test.yaml
root@mon-vm-01:/etc/victoriametrics/vmagent# cat scrape_config_files/test.yaml
- job_name: ns1
static_configs:
- targets:
- mon-test-vm-03x.g01.i-free.ru:9100
- job_name: ns2
static_configs:
- targets:
- mon-test-vm-03x.g01.i-free.ru:9100
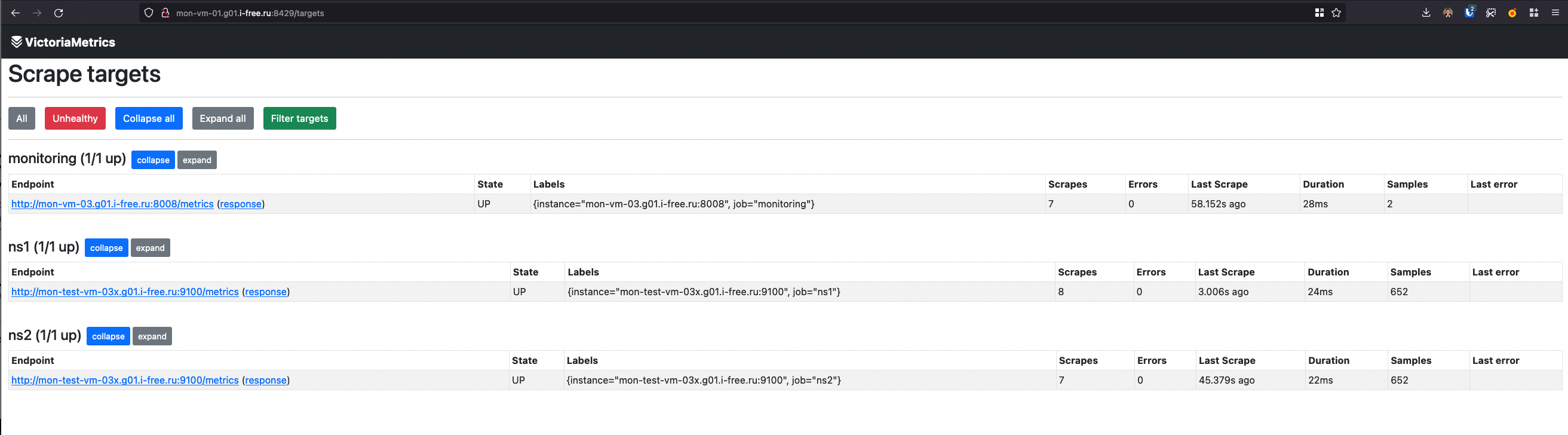
Можно задавать файлы разными способами:
scrape_config_files:
- configs/*.yml
- single_scrape_config.yml
- https://config-server/scrape_config.yml # даже так
Каждый файл из этого списка должен содержать валидные скрейп конфиги (static_configs, *_sd_configs, etc)
Эти файлы могут релоадиться без рестарта
Unsupported Prometheus config sections
vmagent не поддерживает следующие секции из -promscrape.config файла (которые поддерживает пром):
-
remote_write- эта секция заменяется разными-remoteWrite*флагами -
remote_read- не работает вообще, запросы для получения данных доступны у хранилища (например VictoriaMetrics) -
rule_filesиalerting- не работает вообще потому что эту функцию выполняетvmalert
Список поддерживаемых SD https://docs.victoriametrics.com/sd_configs.html
Также не поддерживается refresh_interval для service_discovery, эта опция заменяется флагами -promscrape.*CheckInterval
Adding labels to metrics
Дополнительные лейблы к метрикам можно добавить следующим образом:
-
global -> external_labelsв-promscrape.configфайле, лейблы добавятся на все метрики и таргеты собранные через scrape механизм, не добавятся на метрики полученные через push механизм - Флаг
-remoteWrite.labelлейблы будут добавлены на все метрики перед отправкой в-remoteWrite.url
Например флаг--remoteWrite.label=remotewritelabel=true
- Третий способ - релейблинг
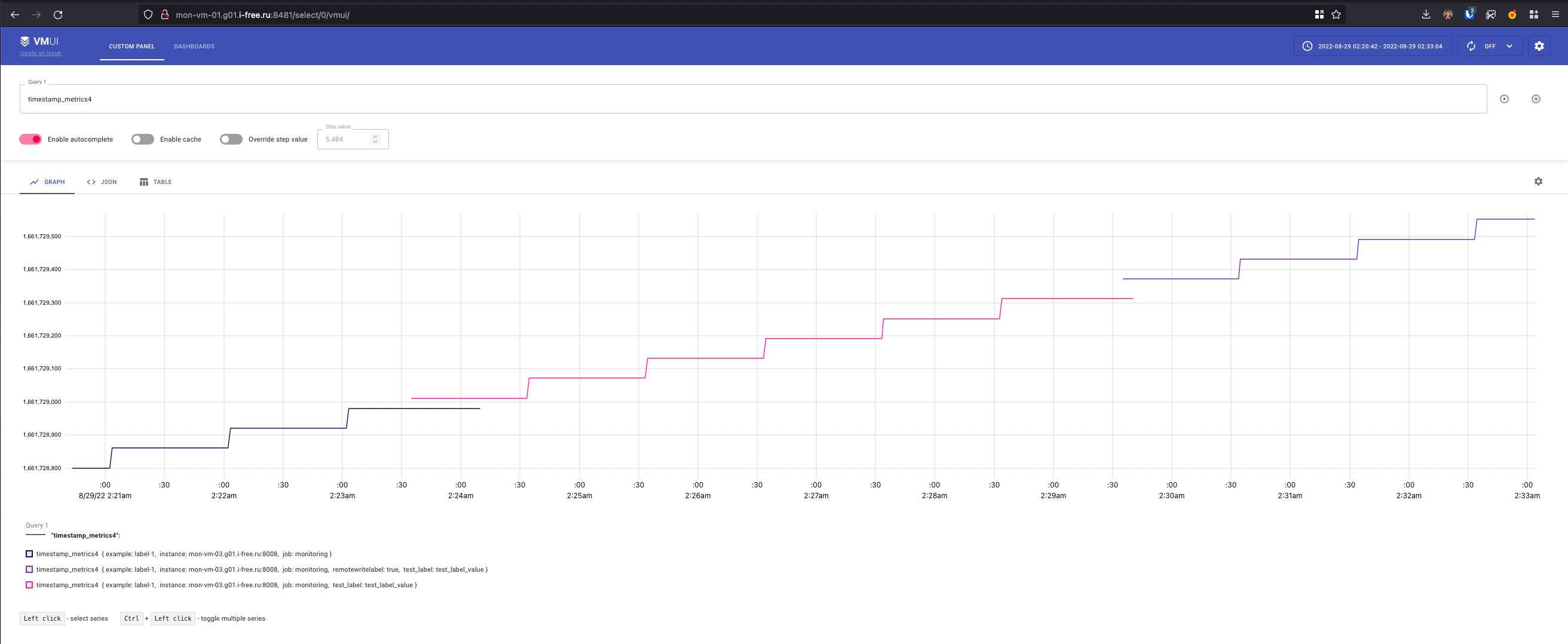
Как я понял
-remoteWrite.labelработает для метрик которые получены агентом через push протоколы и которые он дальше запушит в хранилку. То есть в случае когда агент работает вообще без конфига как гейтвей для пушинга
Automatically generated metrics
vmagent автоматически генерирует следующие метрики для каждого таргета:
-
up- значение1говорит об успешном скрейпе,0об ошибке при скрейпинге (позволяет отслеживать ошибки при скрейпинге) -
scrape_duration_seconds- длительность скрейпа в секундах (позволяет отслеживать медленные скрейпы)
-
scrape_timeout_seconds- значениеscrape_timeoutиз конфига для этого таргета (позволяет отслеживать таргеты чейscrape_duration_secondsприближается к значению изscrape_timeout) -
scrape_samples_scraped- количество сэмплов полученных со скрейпа таргета (позволяет отслеживать таргеты которые выдают слишком много сэмплов) -
scrape_samples_limit- значениеsample_limitиз конфига, метрика экспозится только если лимит задан (позволяет отслеживать таргеты которые экспозят количество метрики приближающееся к лимиту) -
scrape_samples_post_metric_relabeling- количество метрик оставшихся после применения релейблинга (хз зачем) -
scrape_series_added- аппроксимированное количество новых метрик со скрейпа (позволяет отслеживать high churn rate)
Эта метрика будет равна0если установлен флаг-promscrape.noStaleMarkers -
scrape_series_limit- значение изseries_limitдля таргета (метрика будет только если лимит выставлен) -
scrape_series_current- количество метрик которые экспозятся на таргете сейчас (не сэмплы, а именно таймсерии) (позволяет отслеживать приближение к лимиту) -
scrape_series_limit_samples_dropped- количество дропнутых из-за превышения лимита сэмплов
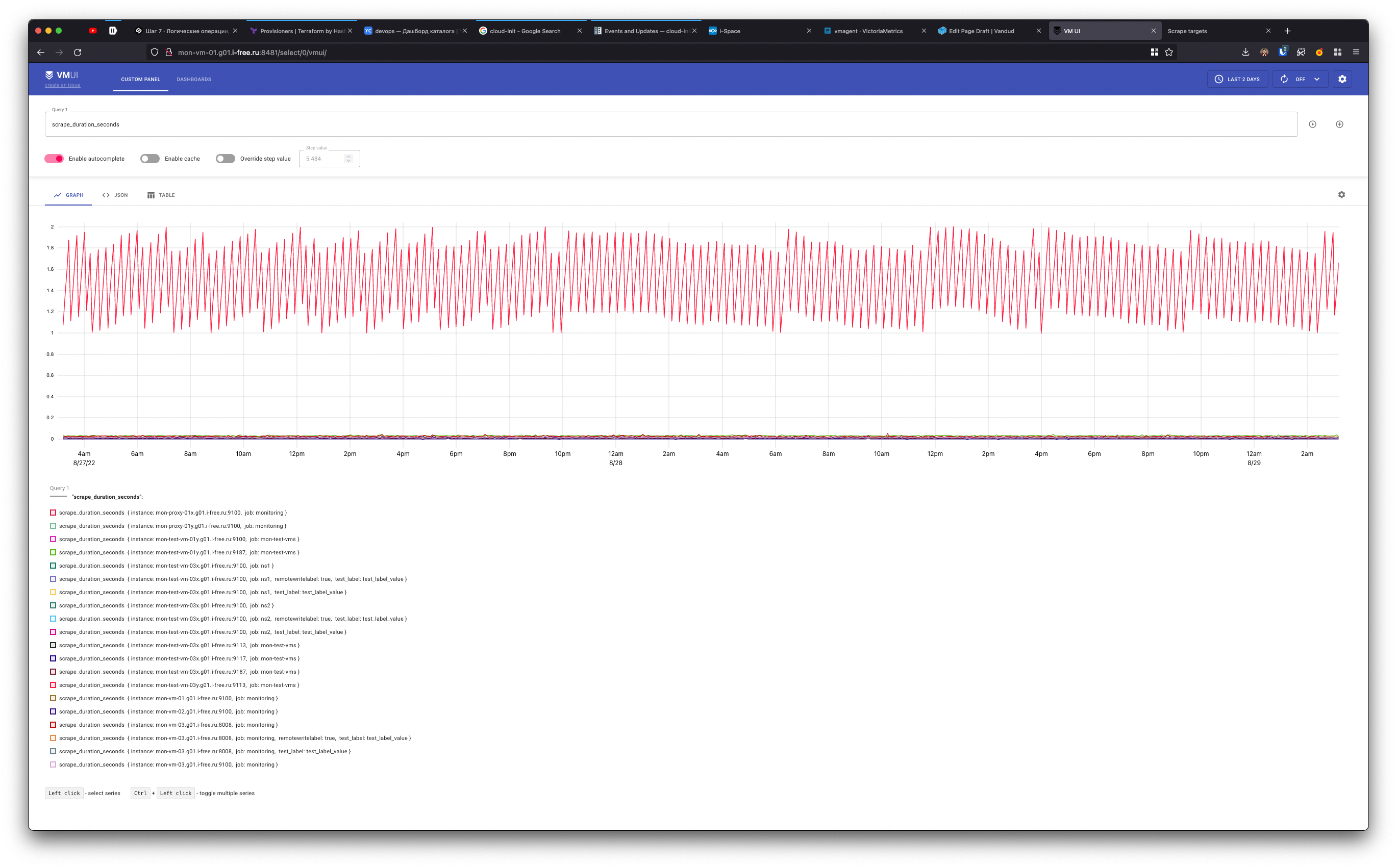
Relabeling
Поддерживается Premetheus-compatible релейблинг и ряд дополнений к нему. Релейблинг может быть определен в следующих местах:
- В секции
scrape_config -> relabel_configsв-promscrape.configфайле. Этот релейблинг используется для изменения лейблов в таргетах и для дроппинга ненужных таргетов. Этот релейблинг можно дебажить опциейrelabel_debug: trueв секцииscrape_config, vmagent будет логировать лейблы до и после релейблинга - В секции
scrape_config -> metric_relabel_configs. Этот релейблинг позволяет модифицировать лейблы метрик и дропать ненужные метрики. Можно дебажить через опциюmetric_relabel_debug: true - В файле
-remoteWrite.relabelConfig. Этот релейблинг позволяет модифицировать лейблы для всех собранных метрик (включая те что получены через push протоколы) и дропать ненужные метрики перед отправкой на-remoteWrite.urlадреса. Можно дебажить флагом-remoteWrite.relabelDebug - В файлах
-remoteWrite.urlRelabelConfig. То же что и выше но для конкретных-remoteWrite.url'ов. Можно дебажить флагом-remoteWrite.urlRelabelDebug
Все файлы с релейблинг конфигами могут содержать плейсхолдеры%{ENV_VAR}, которые будут заменены на соответствующие переменные окружения
https://relabeler.promlabs.com/ поможет отдебажить правила релейблинга
Relabeling enhancements
VictoriaMetrics имеет дополнительные действия для релейблинга поверх стандартных прометеусовских:
-
replace_allreplaces all of the occurrences ofregexin the values ofsource_labelswith thereplacementand stores the results in thetarget_label. For example, the following relabeling config replaces all the occurrences of-char in metric names with_char (e.g.foo-bar-bazmetric name is transformed intofoo_bar_baz):- action: replace_all source_labels: ["__name__"] target_label: "__name__" regex: "-" replacement: "_" -
labelmap_allreplaces all of the occurrences ofregexin all the label names with thereplacement. For example, the following relabeling config replaces all the occurrences of-char in all the label names with_char (e.g.foo-bar-bazlabel name is transformed intofoo_bar_baz):- action: labelmap_all regex: "-" replacement: "_" -
keep_if_equal: keeps the entry if all the label values fromsource_labelsare equal, while dropping all the other entries. For example, the following relabeling config keeps targets if they contain equal values forinstanceandhostlabels, while dropping all the other targets:- action: keep_if_equal source_labels: ["instance", "host"] -
drop_if_equal: drops the entry if all the label values fromsource_labelsare equal, while keeping all the other entries. For example, the following relabeling config drops targets if they contain equal values forinstanceandhostlabels, while keeping all the other targets:- action: drop_if_equal source_labels: ["instance", "host"] -
keep_metrics: keeps all the metrics with names matching the givenregex, while dropping all the other metrics. For example, the following relabeling config keeps metrics withfooandbarnames, while dropping all the other metrics:- action: keep_metrics regex: "foo|bar" -
drop_metrics: drops all the metrics with names matching the givenregex, while keeping all the other metrics. For example, the following relabeling config drops metrics withfooandbarnames, while leaving all the other metrics:- action: drop_metrics regex: "foo|bar"graphite: applies Graphite-style relabeling to metric name. See these docs for details.
The regex value can be split into multiple lines for improved readability and maintainability. These lines are automatically joined with | char when parsed. For example, the following configs are equivalent:
- action: keep_metrics
regex: "metric_a|metric_b|foo_.+"
- action: keep_metrics
regex:
- "metric_a"
- "metric_b"
- "foo_.+"
VictoriaMetrics components support an optional if filter in relabeling configs, which can be used for conditional relabeling. The if filter may contain arbitrary time series selector. For example, the following relabeling rule drops metrics, which don't match foo{bar="baz"} series selector, while leaving the rest of metrics:
- action: keep
if: 'foo{bar="baz"}'
This is equivalent to less clear Prometheus-compatible relabeling rule:
- action: keep
source_labels: [__name__, bar]
regex: 'foo;baz'
Graphite relabeling
Не интересно
Prometheus staleness markers
Про staleness маркеры - https://www.robustperception.io/staleness-and-promql/ (я не особо понял)
vmagent засылает staleness маркеры в -remoteWrite.url в следующих случаях:
- Если они получены vmagent'ом через remote_write протокол
- Если метрика пропала из списка соскрейпленных метрик, тогда stale маркер выставляется на конкретную метрику
- Если таргет стал недоступен, тогда маркер выставляет на все метрики этого таргета
- Если таргет пропал из списка таргетов, тогда маркеры выставляет на все метрики этого таргета
Для работы маркеров требуется дополнительная память, потому что нужно хранить предыдущий response body для каждого таргета, чтобы сравнивать его с текущим response body. Потребление памяти можно уменить выключив этот функционал флагом -promscrape.noStaleMarkers (он выключает staleness tracking), также этот флаг выключает сервисную метрику scrape_series_added
Stream parsing mode
По умолчанию vmagent сперва записывает весь response body в память, потом парсит его, потом применяет релейблинг и пушит в в -remoteWrite.url. Этот режим работает хорошо в большинстве случаев когда таргет экспозит небольшое количество метрик (меньше 10к). Но этот режим может требовать много памяти когда таргеты экспозят огромное количество метрик. В таких случаях рекомендуется включать stream parsing mode. Когда включен этот режим, vmagent читает response body чанками, немедленно процессит каждый чанк и пушит полученные метрики в remote storage. Это позволяет сохранить потребление памяти когда таргеты экспозят миллионы метрик
Stream parsing mode включается автоматически для таргетов, размер ответа которых превышает значение флага -promscrape.minResponseSizeForStreamParse
Этот режим может быть включен явно в следующих местах:
- Через флаг
-promscrape.streamParse. В этом случае все таргеты из-promscrape.configбудут обрабатываться в этом режиме - Через опцию
stream_parse: trueв секцииscrape_configs. Тогда таргеты описанные в этой секции будут обрабатываться в этом режиме - Через лейбл
__stream_parse__=true, который может быть установлен через релейблинг в секцииrelabel_configs. Тогда режим будет использоваться для конкретных таргетов
Опции
sample_limitиseries_limitне могут быть использованы одновременно с stream parsing mode потому что пропаршенные данные пушатся в сторадж сразу
Scraping big number of targets
Один vmagent может скрейпить десятки тысяч таргетов. Иногда этого может быть недостаточно из-за разных ограничений по ресурсам. В таком случае таргеты можно пошарить между несколькими инстансами vmagent'a (горизонтальное масштабирование). Все vmagent'ы в кластере должны иметь идентичные -promscrape.config с ясным значением флага -promscrape.cluster.memberNum. Значение этого флага должно быть в диапазоне от 0 до N-1, где N это количество vmagent'ов в кластере. Количество vmagent'ов нужно указать в флаге -promscrape.cluster.memberCount
Например следующие две команды поднимут кластер vmagent'ов из двух инстансов и нагрузка будет разделена между ними:
/path/to/vmagent -promscrape.cluster.membersCount=2 -promscrape.cluster.memberNum=0 -promscrape.config=/path/to/config.yml ...
/path/to/vmagent -promscrape.cluster.membersCount=2 -promscrape.cluster.memberNum=1 -promscrape.config=/path/to/config.yml ...
По умолчанию каждый таргет скрейпится только одним vmagent'ом из кластера. Если нужна репликация таргетов между агентами, то нужно проставить флаг -promscrape.cluster.replicationFactor с значением желаемого количества реплик
Например следующие три команды поднимут кластер vmagent'ов из трех нод с фактором репликации - 2. То есть каждый таргет будет скрейпиться какими-то двумя vmagent'ами:
/path/to/vmagent -promscrape.cluster.membersCount=3 -promscrape.cluster.replicationFactor=2 -promscrape.cluster.memberNum=0 -promscrape.config=/path/to/config.yml ...
/path/to/vmagent -promscrape.cluster.membersCount=3 -promscrape.cluster.replicationFactor=2 -promscrape.cluster.memberNum=1 -promscrape.config=/path/to/config.yml ...
/path/to/vmagent -promscrape.cluster.membersCount=3 -promscrape.cluster.replicationFactor=2 -promscrape.cluster.memberNum=2 -promscrape.config=/path/to/config.yml ...
В случае с репликацией нужно включать data deduplication на сторадже указанном в -remoteWrite.url. Флаг -dedup.minScrapeInterval должен быть выставлен в scrape_interval указанный в -promscrape.config
High availability
Для этого можно запустить несколько агентов которые будут скрейпить одинаковые таргеты и пушить в один и тот же сторадж, но нужно чтобы была настроена дедупликация на сторадже
Также рекомендуется указывать разные значения в флагах -promscrape.cluster.name на агентах для более качественной дедупликации
High Availability достигается фактором репликации. То есть каждый таргет опрашивается более чем одним агентом и при потере любого одного агента из кластера, как минимум один продолжает скрейпить таргет
Scraping targets via a proxy
https://docs.victoriametrics.com/vmagent.html#scraping-targets-via-a-proxy
vmagent может скрейпить таргеты сквозь прокси (http, https, socks5). Адрес прокси задается опцией proxy_url в секции scrape_configs:
scrape_configs:
- job_name: foo
proxy_url: https://proxy-addr:1234
Работу через прокси можно законфигурировать следующими опциями:
Cardinality limiter
По умолчанию vmagent не ограничивает количество таймсерий которые могут быть потреблены с каждого таргета. Это ограничение может быть задано в следующих местах:
- Через флаг
-promscrape.seriesLimitPerTarget. Этот лимит будет применяться к каждому таргету из-promscrape.config - Через опцию
series_limitв секцииscrape_config. Этот лимит будет применяться ко всем таргетам из этогоscrape_config - Через лейбл
__series_limit__на таргете который может быть выставлен на конкретный таргет в секцииrelabel_configs
Так же может быть полезной опция sample_limit в секции scrape_config
Метрики сверх лимита будут дропаться
vmagent создает дополнительные сервисные метрики для каждого таргета у которого не нулевой лимит:
-
scrape_series_limit_samples_dropped- количество дропных из-за превышения лимита метрик -
scrape_series_limit- лимит на этот таргет -
scrape_series_current- текущее количество таймсерий для этого таргета
Эти сервисные метрики засылаются в -remoteWrite.url вместе с обычными метриками
Эти метрики позволяют настроить следующие алертинги:
-
scrape_series_current / scrape_series_limit > 0.9- алерт когда количество предоставляемых экспортером метрик приближается к лимиту -
sum_over_time(scrape_series_limit_samples_dropped[1h]) > 0- алерт когда превышен series limit и некоторые метрики начинают дропаться
По умолчанию vmagent не ограничивает количество таймсерий которые отправляются в хранилище указанное в -remoteWrite.url. Этот лимит может быть проставлен следующими флагами:
-
-remoteWrite.maxHourlySeries- лимит на количество уникальных таймсерий которые vmagent может записать в remote storage в течение часа. Полезно для ограничения количества активных таймсерий -
-remoteWrite.maxDailySeries- лимит на количество уникальных таймсерий которые vmagent может записать в remote storage в течение дня. Полезно для ограничения дневного churn rate
Оба лимита могут быть выставлены одновременно. Если любой из этих лимитов достигнут, тогда сэмплы для новых таймсерий будут дропаться и в лог будут писаться сообщения с уровнем WARNING
vmagent экспозит следующие метрики на http://vmagent:8429/metrics:
- vmagent_hourly_series_limit_rows_dropped_total` - количество дропнутых после достижения часового лимита метрик
- vmagent_hourly_series_limit_max_series
- значение из-remoteWrite.maxHourlySeries` - vmagent_hourly_series_limit_current_series` - количество уникальных метрик за последний час
- vmagent_daily_series_limit_rows_dropped_total` - количество дропнутых после достижения дневного лимита метрик
- vmagent_daily_series_limit_max_series
- значение из-remoteWrite.maxDailySeries` - vmagent_daily_series_limit_current_series` - количество уникальных метрик за последнй день
Эти лимиты примерны, обычно расходятся меньше чем на один процент
Monitoring
vmagent экспортирует разные метрики на эндпоинте http://vmagent-host:8429/metrics
Рекомендуется их регулярно скрейпить потому что их анализ в будущем может принести пользу
Есть официальный дашборд для графаны https://grafana.com/grafana/dashboards/12683-vmagent/
vmagent также экспортирует статус для разных таргетов на следующих хэндлерах:
-
http://vmagent-host:8429/targets- человеко-читаемый статус по каждому таргету. Этот урл можно курлануть (то есть один и тот же урл красиво выглядит и в браузере и в терминале)
Можно добавить к запросу аргументshow_original_labels=1и будут показаны оригинальные лейблы до применения релейблинга (это полезно при дебаге релейблинга)
-
http://vmagent-host:8429/api/v1/targets- хэндлер аналогичный прометеусовскому? curl -s http://mon-vm-01.g01.i-free.ru:8429/api/v1/targets | jq 'del(.data.activeTargets[0,1])' { "status": "success", "data": { "activeTargets": [ { "discoveredLabels": { "__address__": "mon-vm-03.g01.i-free.ru:8008", "__metrics_path__": "/metrics", "__scheme__": "http", "__scrape_interval__": "1m0s", "__scrape_timeout__": "10s", "__tenant_id__": "1", "job": "monitoring", "test_label": "test_label_value" }, "labels": { "instance": "mon-vm-03.g01.i-free.ru:8008", "job": "monitoring", "test_label": "test_label_value" }, "scrapePool": "monitoring", "scrapeUrl": "http://mon-vm-03.g01.i-free.ru:8008/metrics", "lastError": "", "lastScrape": "2022-08-29T21:41:33.779+03:00", "lastScrapeDuration": 0.025, "lastSamplesScraped": 2, "health": "up" } ], "droppedTargets": [] } } -
http://vmagent-host:8429/ready- отдает код 200 с текстомOKкогда vmagent завершил инициализацию для всех SD конфигов. Это может быть полезным для налаживания rolling update без потерь скрейпов
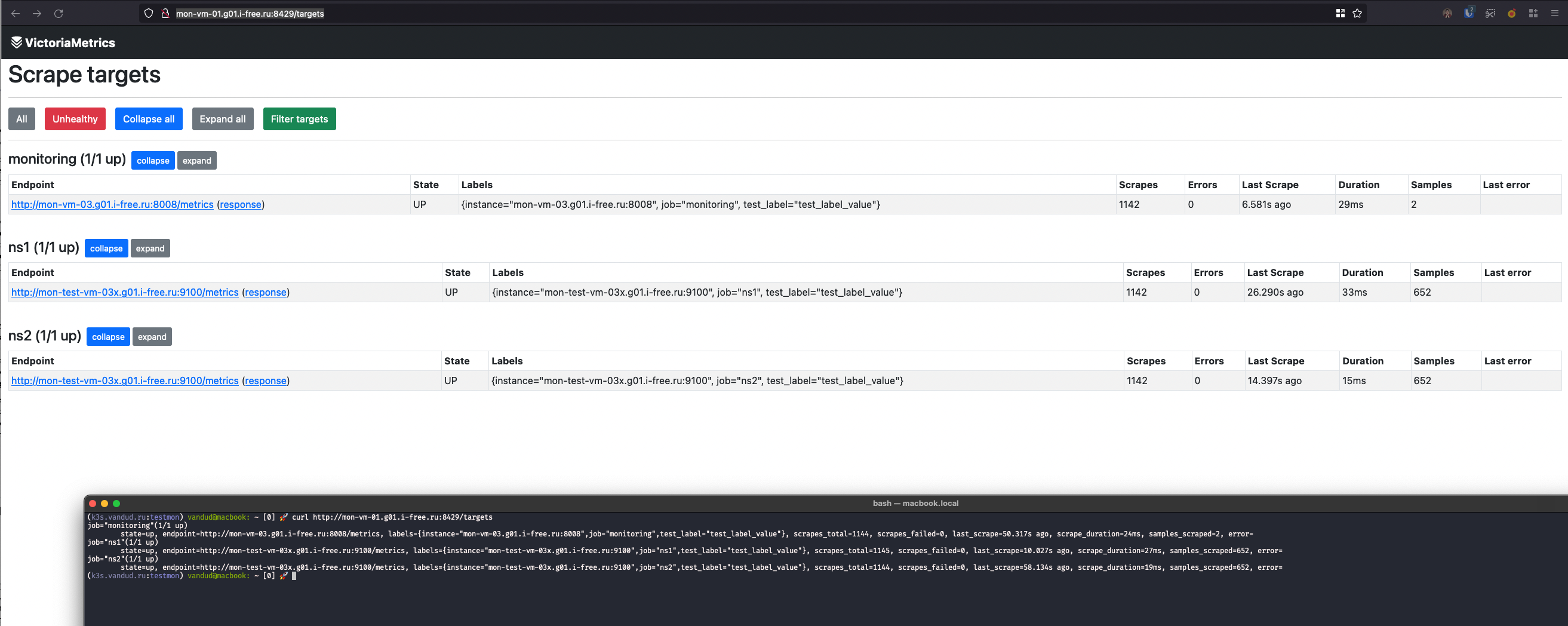

Troubleshooting
- Рекомендуется использовать официальный дашборд для vmagent'a https://grafana.com/grafana/dashboards/12683-vmagent/
- Рекомендуется увеличить ограничение на открытые файлы в системе
ulimit -nпри скрейпинге большого количетсва таргетов, потому что при скрейпинге устанавливается одно tcp соединение на один таргет - Если vmagent потребляет много памяти, то следующие опции могут помочь:
- Выключение staleness tracking'a через флаг
-promscrape.noStaleMarkers - Включение stream parsing mode (если скрейпится гигантское кол-во метрик)
- Уменьшение кол-ва выходных очередей через флаг
-remoteWrite.queues - Уменьшение кол-ва памяти которую может потребить vmagent для in-memory буфферизации через флаги
-memory.allowedPercentили-memory.allowedBytes - Уменьшение кол-ва ядер которые может занять vmagent через переменную окружения
GOMAXPROCS=N, гдеNэто желаемый лимит на ядра - Можно выставить флаг
-promscrape.dropOriginalLabels(подробнее тут)
- Выключение staleness tracking'a через флаг
- Когда vmagent скрейпит много нерабочих таргетов, то о каждой неудаче он сообщает в лог. Эти ошибки можно выключить флагом
-promscrape.suppressScrapeErrors - Урл
/api/v1/targetsполезен для дебагинга процесса релейблинга. Эта страница содержит оригинальные лейблы для таргетов которые дропаются правилами релейблинга (секцияdroppedTargets). По умолчанию в этой секции будет отображено столько таргетов, сколько указано в флаге-promscrape.maxDroppedTargets, если твой сетап дропает больше таргетов, то чтобы увидеть все увеличь значение этого флага. Трэкинг дропаемых таргетов требует дополнительной памяти, поэтому если их у тебя слишком много то это может заметно отразиться на потреблении памяти - Рекомендуется увеличивать значение флага
-remoteWrite.queuesесли значение метрикиvmagent_remotewrite_pending_data_bytesрастет. Также в таком случае рекомендуется увечивать значения флагов-remoteWrite.maxBlockSizeи-remoteWrite.maxRowsPerBlock. Это улучшит производительность поглощения данных ценой потребления памяти - Если ты видишь гэпы в данных которые пушатся агентом в хранилку при установленном флаге
-remoteWrite.maxDiskUsagePerURL, попробуй увеличить количество очередей в-remoteWrite.queues. Такие гэпы могут происходить потому что vmagent не успевает отправлять данные в хранилище и дропает данные из кэша если достигает ограничения из-remoteWrite.maxDiskUsagePerURL - vmagent дропает блоки данных если сторадж отдает
400 Bad Requestили409 Conflict. Количество дропнутых блоков можно отслеживать по метрикеvmagent_remotewrite_packets_dropped_total - Используй
-remoteWrite.queues=1если используется хранилище не поддерживающее out-of-order samples (data backfilling) - vmagent буфферизирует собранные данные в
-remoteWrite.tmpDataPathдо отправки их в-remoteWrite.url. Эта директория может вырастать до больших размеров в ситуациях когда сторадж не доступен долгое время и если флаг-remoteWrite.maxDiskUsagePerURLне задан. В таких случаях если тебе не важны эти данные то можно остановить агента, удалить данные и запустить заново - По умолчанию vmagent маскриует
-remoteWrite.urlподsecret-urlв логах и на странице с метриками агента/metrics(этот урл фигурирует в некоторых метриках) потому что этот урл может содержать чувствительные данные (токены, пароли). Флаг-remoteWrite.showURLпозволяет отключить это сокрытие для улучшение дебагобилити# проверяет без флага root@mon-vm-01:~# curl -s http://mon-vm-01.g01.i-free.ru:8429/metrics | grep vmagent_remotewrite_requests_total vmagent_remotewrite_requests_total{url="1:secret-url", status_code="2XX"} 299 root@mon-vm-01:~# vim /etc/systemd/system/vmagent.service; systemctl daemon-reload; systemctl restart vmagent # проверяем после добавления флага root@mon-vm-01:~# curl -s http://mon-vm-01.g01.i-free.ru:8429/metrics | grep vmagent_remotewrite_requests_total vmagent_remotewrite_requests_total{url="1:http://mon-vm-01.g01.i-free.ru:8480/insert/0/prometheus", status_code="2XX"} 0 - By default vmagent evenly spreads scrape load in time. If a particular scrape target must be scraped at the beginning of some interval, then scrape_align_interval option must be used. For example, the following config aligns hourly scrapes to the beginning of hour
scrape_configs: - job_name: foo scrape_interval: 1h scrape_align_interval: 1h - By default vmagent evenly spreads scrape load in time. If a particular scrape target must be scraped at specific offset, then scrape_offset option must be used. For example, the following config instructs vmagent to scrape the target at 10 seconds of every minute
scrape_configs: - job_name: foo scrape_interval: 1m scrape_offset: 10s
Kafka integration
Пока не интересно
Подробности тут
How to build from sources
Пока не интересно
Подробности тут
Profiling
vmagent предоставляет хэндлеры для сбора Go профилей:
- Memory profile -
curl http://vmagent:8429/debug/pprof/heap > mem.pprof - CPU profile -
curl http://vmagent:8429/debug/pprof/profile > cpu.pprof
Команда для сбора CPU профиля сперва ждет 30 секунд и только потом возращает результат
Собранные профили можно проанализировать утилитой https://github.com/google/pprof
Файлы профилей не содержат сенсетивной информации поэтому их можно без страха шарить кому-то
Advanced usage
vmagent имеет еще массу различных флагов, актуальную справку по которым можно увидеть запустив vmagent -help
vmalert
vmalert выполняет список переданных ему alerting и recording rules в указанном в флаге -datasource.url датасорсе который должен быть совместим с Prometheus HTTP API
Для доставки алертов он полагается на Alertmanager путь до которого должен быть прописан в флаге -notifier.url
Результаты работы recording rules vmalert запишет через remote write протокол в указанный -remoteWrite.url
vmalert сильно вдохновлен Prometheus'ом и ставит перед собой цель быть совместимым с его синтаксисом
Features
- Интеграция с VictoriaMetrics TSDB
- Поддержка MetricsQL и валидации вырежений
- Поддержка Prometheus формата alerting rules
- Интеграция с Alertmanager
- Сохранение состояния алертов при рестартах
- Recording/Alerting rules backfilling (
replay) - Легковесный
- Переиспользуемые темплейты для аннотаций
Limitations
vmalert делает запросы в удаленный datasource, поэтому возможны сетевые проблемы, нужно это учитывать при составлении правил (нужны thresholds)
По умолчанию выполнение правил выполняется последовательно в пределах одной группы, но сохранение результатов выполнения в удаленном хранилище является асинхронным. Следовательно, пользователь не должен полагаться на цепочку правил записи, когда результат предыдущего правила записи повторно используется в следующем;
QuickStart
Чтобы начать использовать vmalert нужно:
- list of rules - PromQL/MetricsQL выражения для выполнения
- datasource address - эндпоинт с поддержкой Prometheus HTTP API для применения к нему запросов
- (опционально) notifier address - Alertmanager для обработки, аггрегации алертов и отправки нотификаций. Адрес нотифайера можно получить через SD
- (опционально) remote write address - remote write совместимый сторадж для хранения состояния алертов. Для хранения состояния в множестве хранилищ можно использовать vmagent с настроенными множественными remote writes
- (опционально) remote read address - MetricsQL совместимый datasource откуда vmalert будет восстанавливать состояния алертов
Пример конфигурации vmalert'a:
./bin/vmalert -rule=alert.rules \ # Path to the file with rules configuration. Supports wildcard
-datasource.url=http://localhost:8428 \ # Prometheus HTTP API compatible datasource
-notifier.url=http://localhost:9093 \ # AlertManager URL (required if alerting rules are used)
-notifier.url=http://127.0.0.1:9093 \ # AlertManager replica URL
-remoteWrite.url=http://localhost:8428 \ # Remote write compatible storage to persist rules and alerts state info (required if recording rules are used)
-remoteRead.url=http://localhost:8428 \ # Prometheus HTTP API compatible datasource to restore alerts state from
-external.label=cluster=east-1 \ # External label to be applied for each rule
-external.label=replica=a # Multiple external labels may be set
Нужно отметить что раздельные -remoteWrite.url и -remoteRead.url позволяют использовать vmalert как транспортера данных между горячим, быстрым хранилищем и холодным, долгим (short-term -> long-term) (имеются ввиду record rules)
Если ты запускаешь несколько инстансов vmalert'a и все они подключаются к одному хранилищу и Alertmanager'у, то будет полезным настроить на них различающиеся лейблы, чтобы было понятно кто из них сгенерил алерт
Конфигурация для recording и alerting rules очень похожа на Prometheus rules, каждый rule пренадлежит какой-то group и каждый конфиг может содержать различное количество групп:
groups:
[ - <rule_group>]
Groups
Каждая группа имеет слудующие аттрибуты:
# Имя группы, должно быть уникальным в рамках файла
name: <string>
# Как часто рулы из этой группы должны выполняться
[ interval: <duration> | default = -evaluationInterval flag ]
# Ограничение на количество алертов и таймсерий которые может породить этот рул. 0 - лимита нет
[ limit: <int> | default = 0 ]
# Как много правил будет выполнено за раз в рамках группы. Увеличение параллельности может скорить выполнение правил
[ concurrency: <integer> | default = 1 ]
# Опциональный тип выражения внутри рула. Значением может быть 'graphite' и 'prometheus', второй дефолтный
[ type: <string> ]
# Опциональные дополнительные HTTP URL параметры применяемые для всех запросов к хранилке в рамках выполнения рулов группы
# Например:
# params:
# nocache: ["1"] # disable caching for vmselect
# denyPartialResponse: ["true"] # fail if one or more vmstorage nodes returned an error
# extra_label: ["env=dev"] # apply additional label filter "env=dev" for all requests
# see more details at https://docs.victoriametrics.com#prometheus-querying-api-enhancements
params:
[ <string>: [<string>, ...]]
# Опциональные HTTP хедеры в формате `header-name: value` добавляемые ко всем запросам к хранилке в рамках выполнения рулов группы
# Например:
# headers:
# - "CustomHeader: foo"
# - "CustomHeader2: bar"
# Заголовки выставленные таким образом имеет приоритет выше чем заголовки добавленные через флаг `-datasource.headers`
headers:
[ <string>, ...]
# Опциональный список лейблов добавляемых каждому рулу в группе
# Эти лейблы имеют приоритет выше чем external labels
labels:
[ <labelname>: <labelvalue> ... ]
rules:
[ - <rule> ... ]
Rules
Каждое правило содержит поле expr с PromQL/MetricsQL выражением. vmalert выполняет это выражение и дальше действует в зависимости от типа правила
Есть два типа правил:
- alerting - Alerting rules позволяют описать условия срабатывания алерта через поле
exprи отправить нотификацию в Alertmanager если результат выполнения не пустой - recording - Recording rules позволяют описать поле
exprрезультат применения которого далее будет забэкфиллен в-remoteWrite.url. Recording rules нужны для предподсчета часто используемых или вычислительно сложных выражений
vmalert не разрешает наличие дубликатов - рулов с одинаковой комбинацией имени, выражения и лейблов в рамках одной группы
Alerting rules
Синтаксис алерт рулов следующий:
# Имя алерта, должно проходить правила валидации имен метрик
alert: <string>
# Выражение. Язык выражения зависит от значения в поле `type` группы
expr: <string>
# Алерт считается "горящим" после того как в течение этого времени (из поля for) его expr возвращал не пустоту
# Алерт который срабатыват в течение времени меньшего чем for находится в состоянии pending
# Если этот параметр отсутсвует или проставлен в 0, то алерт будет срабатывать сразу
[ for: <duration> | default = 0s ]
# Лейблы для добавления или оверрайдинга под каждый алерт
labels:
[ <labelname>: <tmpl_string> ]
# Аннотации под каждый алерт
annotations:
[ <labelname>: <tmpl_string> ]
Templating
Разрешено использовать Go templating в аннотациях для форматирования данных, перебора или выполнения выражений. Следующие переменные доступны к использованию в темплейтинге:
| Variable | Description | Example |
|---|---|---|
$value или .Value
|
Текущее значение алерта | Number of connections is {{ $value }} |
$activeAt или .ActiveAt
|
Момент времени когда алерт стал активным (pending или firing) | http://vm-grafana.com/panelId=xx?from={{($activeAt.Add (parseDurationTime "1h")).Unix}}&to={{($activeAt.Add (parseDurationTime "-1h")).Unix}} |
$labels или .Labels
|
Список лейблов алерта | Too high number of connections for {{ .Labels.instance }} |
$alertID или .AlertID
|
alert's ID сгенерированный vmalert'ом | Link: vmalert/alert?group_id={{.GroupID}}&alert_id={{.AlertID}} |
$groupID или .GroupID
|
alert's group ID сгенерированный vmalert'ом | Link: vmalert/alert?group_id={{.GroupID}}&alert_id={{.AlertID}} |
$expr или .Expr
|
Выражение алерта. Может быть использована для генерации ссылки на график в графане или для чего-то еще | /api/v1/query?query={{ $expr |
$externalLabels или .ExternalLabels
|
Список лейблов настроенных через флаг -external.label
|
Issues with {{ $labels.instance }} (datacenter-{{ $externalLabels.dc }}) |
$externalURL или .ExternalURL
|
URL настроенный через флаг -external.url, используется когда vmalert спрятан за проксей |
Visit {{ $externalURL }} for more details |
Reusable templates
Как и в прометеусе, в vmalert'e есть reusable templates
Для их использования нужно описать темплейт в файле и подключить файл через флаг -rule.templates
Например есть описанный темплейт с именем grafana.filter:
{{ define "grafana.filter" -}}
{{- $labels := .arg0 -}}
{{- range $name, $label := . -}}
{{- if (ne $name "arg0") -}}
{{- ( or (index $labels $label) "All" ) | printf "&var-%s=%s" $label -}}
{{- end -}}
{{- end -}}
{{- end -}}
И он может быть использован в аннотации следующим образом:
groups:
- name: AlertGroupName
rules:
- alert: AlertName
expr: any_metric > 100
for: 30s
labels:
alertname: 'Any metric is too high'
severity: 'warning'
annotations:
dashboard: '{{ $externalURL }}/d/dashboard?orgId=1{{ template "grafana.filter" (args .CommonLabels "account_id" "any_label") }}'
Флаг -rule.templates поддерживает вайлдкарды чтобы подсасывать сразу много файлов. Контент темплейт-файлов может быть зарелоажен на лету
Recording rules
Синтаксис recording rules следующий:
# Имя алерта, должно проходить правила валидации имен метрик
record: <string>
# Выражение. Язык выражения зависит от значения в поле `type` группы
expr: <string>
# Лейблы для добавления или оверрайдинга которые будут добавлены до сохранения результата
labels:
[ <labelname>: <labelvalue> ]
Чтобы рекординг рулы работали нужно чтобы присутствовал флаг -remoteWrite.url
Alerts state on restarts
vmalert не имеет локального хранилища, поэтому состояния алертов хранятся в опертивной памяти. Следовательно после рестарта vmalert'a стейты алертов будут потеряны. Чтобы этого избежать нужно чтобы vmalert был сконфигурирован со следующими флагами:
-
-remoteWrite.url- URL до хранилища в котором vmalert будет хранить стейты алертов с помощью таймсерийALERTSиALERTS_FOR_STATE. Это абсолютно рядовые таймсерии, такие же как и все остальные. Стейт алертов записывается в-remoteWrite.urlпри каждом прогоне правил (rule evaluation) -
-remoteRead.url- URL до хранилища из которого vmalert будет восстанавливать состояния алертов после рестарта (запрашивая метрикуALERTS_FOR_STATE)
Оба флага нужны для нормального хранения состояний алертов. Процесс восстановления может фейлиться если таймсерии нет в указанном -remoteRead.url или если она не обновлялась за последний час (контролируется флагом remoteRead.lookback) или если полученный стейт не матчится с текущей конфигурацией vmalert'a
Multitenancy
Есть следующие варинты для алертинга и рекординга при мультитенантном сетапе:
- Можно запустить несколько vmalert'ов, по одному на каждый тенант, и прописать каждому конкретный тенант
-datasource.url=http://vmselect:8481/select/123/prometheus, аналогично с флагами-remoteWrite.urlи-remoteRead.url - Можно указывать параметр
tenantдля каждой группы, но для этого нужно использовать энтерпрайз версию с флагом-clusterModegroups: - name: rules_for_tenant_123 tenant: "123" rules: # Rules for accountID=123 - name: rules_for_tenant_456:789 tenant: "456:789" rules: # Rules for accountID=456, projectID=789
Когда установлен флаг -clusterMode, флаги -datasource.url, -remoteRead.url и -remoteWrite.url должны содержать просто хостнейм и порт, часть урла с тенантом (например /select/123/prometheus) будет добавлена vmalert'ом автоматически на основе тенанта из конфига
Пример запуска:
root@mon-vm-01:~# ./vmalert-prod -rule=/etc/victoriametrics/vmalert/rules.yml -datasource.url=http://mon-vm-01.g01.i-free.ru:8481 -notifier.url=http://mon-vm-01.g01.i-free.ru:9093 -clusterMode -eula
Copyright 2018-2022 VictoriaMetrics, Inc - All Rights Reserved.
For any questions please contact info@victoriametrics.com
2022-08-30T15:55:25.798Z info VictoriaMetrics/lib/logger/flag.go:12 build version: vmalert-20220808-174744-tags-v1.80.0-enterprise-0-gccf72e410
2022-08-30T15:55:25.798Z info VictoriaMetrics/lib/logger/flag.go:13 command-line flags
2022-08-30T15:55:25.798Z info VictoriaMetrics/lib/logger/flag.go:20 -clusterMode="true"
2022-08-30T15:55:25.798Z info VictoriaMetrics/lib/logger/flag.go:20 -datasource.url="http://mon-vm-01.g01.i-free.ru:8481"
2022-08-30T15:55:25.798Z info VictoriaMetrics/lib/logger/flag.go:20 -eula="true"
2022-08-30T15:55:25.798Z info VictoriaMetrics/lib/logger/flag.go:20 -notifier.url="http://mon-vm-01.g01.i-free.ru:9093"
2022-08-30T15:55:25.798Z info VictoriaMetrics/lib/logger/flag.go:20 -rule="/etc/victoriametrics/vmalert/rules.yml"
2022-08-30T15:55:25.799Z info VictoriaMetrics/app/vmalert/main.go:149 reading rules configuration file from "/etc/victoriametrics/vmalert/rules.yml"
2022-08-30T15:55:25.800Z info VictoriaMetrics/lib/httpserver/httpserver.go:94 starting http server at http://127.0.0.1:8880/
2022-08-30T15:55:25.800Z info VictoriaMetrics/lib/httpserver/httpserver.go:95 pprof handlers are exposed at http://127.0.0.1:8880/debug/pprof/
2022-08-30T15:56:11.271Z info VictoriaMetrics/app/vmalert/group.go:304 group "alert.rules" started; interval=1m0s; concurrency=1
2022-08-30T15:57:11.280Z error VictoriaMetrics/app/vmalert/group.go:321 group "alert.rules": rule "Node_State": failed to execute: failed to execute query "up == 0": error getting response from http://mon-vm-01.g01.i-free.ru:8481/select/1/prometheus/api/v1/query?query=up+%3D%3D+0&step=60s&time=1661875020: Post "http://mon-vm-01.g01.i-free.ru:8481/select/1/prometheus/api/v1/query?query=up+%3D%3D+0&step=60s&time=1661875020": EOF
Если в конфиге не указан тенант, то будет использоваться тенант из флага -defaultTenant.prometheus или -defaultTenant.graphite (в зависимости от поля type группы)
Если тенант не указан в конфиге и не указан флагом то будет ошибка:
root@mon-vm-01:~# ./vmalert-prod -rule=/etc/victoriametrics/vmalert/rules.yml -datasource.url=http://mon-vm-01.g01.i-free.ru:8481 -notifier.url=http://mon-vm-01.g01.i-free.ru:9093 -clusterMode -eula
Copyright 2018-2022 VictoriaMetrics, Inc - All Rights Reserved.
For any questions please contact info@victoriametrics.com
2022-08-30T16:19:33.935Z info VictoriaMetrics/lib/logger/flag.go:12 build version: vmalert-20220808-174744-tags-v1.80.0-enterprise-0-gccf72e410
2022-08-30T16:19:33.936Z info VictoriaMetrics/lib/logger/flag.go:13 command-line flags
2022-08-30T16:19:33.936Z info VictoriaMetrics/lib/logger/flag.go:20 -clusterMode="true"
2022-08-30T16:19:33.936Z info VictoriaMetrics/lib/logger/flag.go:20 -datasource.url="http://mon-vm-01.g01.i-free.ru:8481"
2022-08-30T16:19:33.936Z info VictoriaMetrics/lib/logger/flag.go:20 -eula="true"
2022-08-30T16:19:33.936Z info VictoriaMetrics/lib/logger/flag.go:20 -notifier.url="http://mon-vm-01.g01.i-free.ru:9093"
2022-08-30T16:19:33.936Z info VictoriaMetrics/lib/logger/flag.go:20 -rule="/etc/victoriametrics/vmalert/rules.yml"
2022-08-30T16:19:33.936Z info VictoriaMetrics/app/vmalert/main.go:149 reading rules configuration file from "/etc/victoriametrics/vmalert/rules.yml"
2022-08-30T16:19:33.937Z fatal VictoriaMetrics/app/vmalert/main.go:152 cannot parse configuration file: errors(1): invalid group "alert.rules" in file "/etc/victoriametrics/vmalert/rules.yml": group "alert.rules" must contain `tenant` section if `-clusterMode` enabled
root@mon-vm-01:~#
Указываем флаг с дефолтным тенантом и все работает:
root@mon-vm-01:~# ./vmalert-prod -rule=/etc/victoriametrics/vmalert/rules.yml -datasource.url=http://mon-vm-01.g01.i-free.ru:8481 -notifier.url=http://mon-vm-01.g01.i-free.ru:9093 -clusterMode -eula -defaultTenant.prometheus=1
Copyright 2018-2022 VictoriaMetrics, Inc - All Rights Reserved.
For any questions please contact info@victoriametrics.com
2022-08-30T16:20:33.848Z info VictoriaMetrics/lib/logger/flag.go:12 build version: vmalert-20220808-174744-tags-v1.80.0-enterprise-0-gccf72e410
2022-08-30T16:20:33.848Z info VictoriaMetrics/lib/logger/flag.go:13 command-line flags
2022-08-30T16:20:33.848Z info VictoriaMetrics/lib/logger/flag.go:20 -clusterMode="true"
2022-08-30T16:20:33.848Z info VictoriaMetrics/lib/logger/flag.go:20 -datasource.url="http://mon-vm-01.g01.i-free.ru:8481"
2022-08-30T16:20:33.848Z info VictoriaMetrics/lib/logger/flag.go:20 -defaultTenant.prometheus="1"
2022-08-30T16:20:33.848Z info VictoriaMetrics/lib/logger/flag.go:20 -eula="true"
2022-08-30T16:20:33.848Z info VictoriaMetrics/lib/logger/flag.go:20 -notifier.url="http://mon-vm-01.g01.i-free.ru:9093"
2022-08-30T16:20:33.848Z info VictoriaMetrics/lib/logger/flag.go:20 -rule="/etc/victoriametrics/vmalert/rules.yml"
2022-08-30T16:20:33.849Z info VictoriaMetrics/app/vmalert/main.go:149 reading rules configuration file from "/etc/victoriametrics/vmalert/rules.yml"
2022-08-30T16:20:33.850Z info VictoriaMetrics/lib/httpserver/httpserver.go:94 starting http server at http://127.0.0.1:8880/
2022-08-30T16:20:33.850Z info VictoriaMetrics/lib/httpserver/httpserver.go:95 pprof handlers are exposed at http://127.0.0.1:8880/debug/pprof/
Topology examples
Следующие секции показывают как может быть использован vmalert в различных сценариях
Отметим что не все флаги из примеров обязательны:
-
-remoteWrite.urlи-remoteRead.urlнужны только если у тебя есть recording rules или если ты хочешь сохранять стейт алертов при рестартах vmalert'a -
-notifier.urlнужен если у тебя есть alerting rules
Single-node VictoriaMetrics
Простейшая конфигурация когда используется одна нода VictoriaMetrics и как datasource, и как хранилище стейтов алертов:
./bin/vmalert -rule=rules.yml \ # Path to the file with rules configuration. Supports wildcard
-datasource.url=http://victoriametrics:8428 \ # VM-single addr for executing rules expressions
-remoteWrite.url=http://victoriametrics:8428 \ # VM-single addr to persist alerts state and recording rules results
-remoteRead.url=http://victoriametrics:8428 \ # VM-single addr for restoring alerts state after restart
-notifier.url=http://alertmanager:9093 # AlertManager addr to send alerts when they trigger
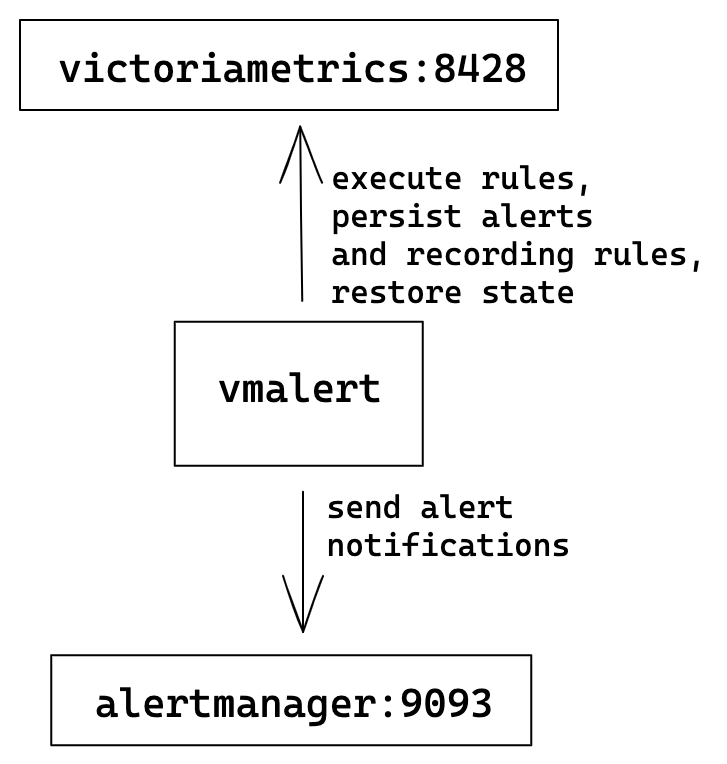
Cluster VictoriaMetrics
В кластерной версии VictoriaMetrics имеет выделенные компоненты для записи и чтения данных: vminsert и vmselect
vmselect используется для получения данных из хранилища для выполнения рулов
vminsert используется для сохранения результатов работы recording rules и для сохранения стейтов алертов
Пример конфигурации:
./bin/vmalert -rule=rules.yml \ # Path to the file with rules configuration. Supports wildcard
-datasource.url=http://vmselect:8481/select/0/prometheus # vmselect addr for executing rules expressions
-remoteWrite.url=http://vminsert:8480/insert/0/prometheus # vminsert addr to persist alerts state and recording rules results
-remoteRead.url=http://vmselect:8481/select/0/prometheus # vmselect addr for restoring alerts state after restart
-notifier.url=http://alertmanager:9093 # AlertManager addr to send alerts when they trigger
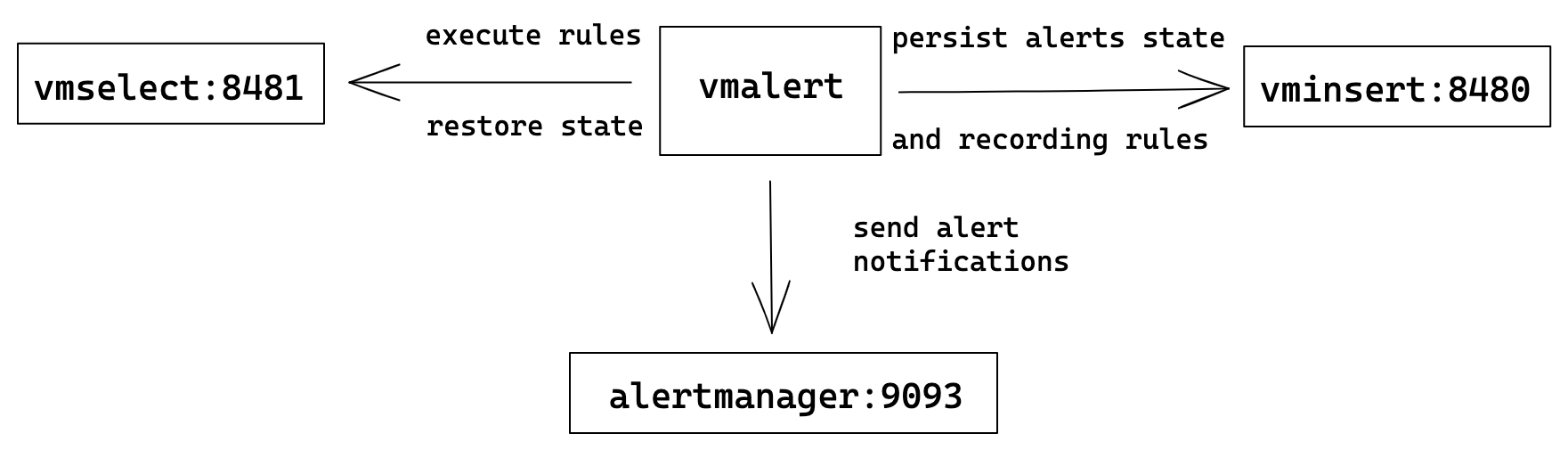
vminsert'ов и vmselect'ов может быть много
Если ты хочешь распределить нагрузку на эти компоненты то добавь балансер и указывай vmalert'у адрес балансера
HA vmalert
Для High Availability можно поднять несколько идентичных vmalert'ов которые будут выполнять одинаковые рулы в одном и том же datasource, складывать результаты их работы в одно и то же хранилище и слать алерты в одни и те же alertmanager'ы
Пример конфигурации:
./bin/vmalert -rule=rules.yml \ # Path to the file with rules configuration. Supports wildcard
-datasource.url=http://victoriametrics:8428 \ # VM-single addr for executing rules expressions
-remoteWrite.url=http://victoriametrics:8428 \ # VM-single addr to persist alerts state and recording rules results
-remoteRead.url=http://victoriametrics:8428 \ # VM-single addr for restoring alerts state after restart
-notifier.url=http://alertmanager1:9093 \ # Multiple AlertManager addresses to send alerts when they trigger
-notifier.url=http://alertmanagerN:9093 # The same alert will be sent to all configured notifiers

Чтобы избежать дублирования результатов работы recording rules нужно просто настроить дедупликацию на сторадже
Рекомендуется использовать значение для флага -dedup.minScrapeInterval большее или равное значению evaluation_interval у vmalert'a
Если есть неконсистентные или "прыгающие" значения у таймсерий сгенеренных vmalert'ом, то можно выключить -datasource.queryTimeAlignment
Из-за выравнивания в HA сетапе (когда более одного vmalert'a обрабатывают recording rules) несколько vmalert'ов будут генерить таймсерии с одинаковыми таймстемпами, но из-за бэкфиллинга (backfilling) значения могут отличаться, это зааффектит логику дедупликации и датапоинты могут "прыгать"
Alertmanager автоматически дедуплицирует алерты с одинаковыми лейблами (поэтому нужно чтобы все vmalert'ы имели идентичные конфиги)
Не забудьте настроить cluster mode для Alertmanager'а для большей доступности
Downsampling and aggregation via vmalert
vmalert не может модифицировать уже существующие данные. Но он может запускать recording rules и записывать результат в -remoteWrite.url, это позволяет аггрегировать данные. Например следующее правило будет подсчитывать среднее значение метрикиhttp_requests на 5 минутном интервале:
- record: http_requests:avg5m
expr: avg_over_time(http_requests[5m])
Каждый раз когда это правило будет выполняться, vmalert будет записывать результат его работы как новую таймсерии с именем http_requests:avg5m в указанный -remoteWrite.url
vmalert запускает правила с периодичностью указанной в -evaluationInterval или в параметре interval указанном для группы
Интервал позволяет контролировать разрешение произведенных таймсерий (чем чаще выполняется тем четче получается)
Возможность задавать интервал позволяет даунсемлить метрики, например следующее правило будет выполяться раз в пять минут, соответственно новые сэмплы в ней будут реже чем в исходной метрике:
groups:
- name: my_group
interval: 5m
rules:
- record: http_requests:avg5m
expr: avg_over_time(http_requests[5m])
Тот факт что для vmalert'a источник данных и пункт записи сгенеренных данных задаются раздельными флагами (-datasource.url и -remoteWrite.url), позволяет читать данные из одного хранилища, даунсэмплить их и записывать получившиеся метрики в другое хранилище
Следующий пример демонстрирует как может выглядеть сетап где vmalert берет данные из горячего хранилища, обрабатывает их и записывает результат в холодное
- горячее - с маленьким ретеншеном, быстрыми дисками, используется для оперативного мониторинга
- холодное - с большим ретеншеном, медленными/дешевыми дисками, с низким разрешением
С помощью vmalert'a пользователь может настроить recording rules для преобразования данных из горячих в холодные
./bin/vmalert -rule=downsampling-rules.yml \ # Path to the file with rules configuration. Supports wildcard
-datasource.url=http://raw-cluster-vmselect:8481/select/0/prometheus # vmselect addr for executing recordi ng rules expressions
-remoteWrite.url=http://aggregated-cluster-vminsert:8480/insert/0/prometheus # vminsert addr to persist recording rules results
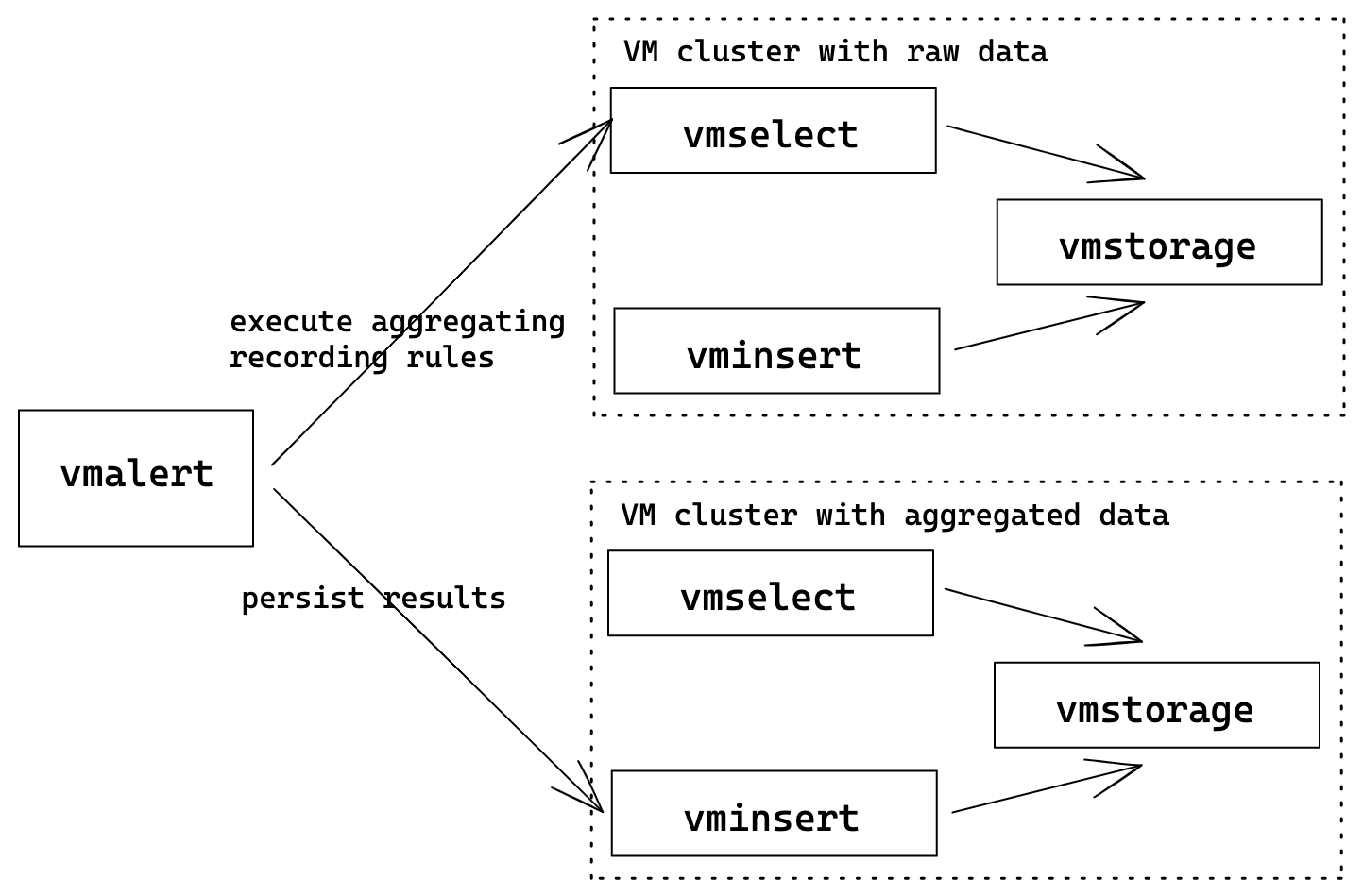
Функцию replay можно использовать для трансформирования исторических данных
Флаги -remoteRead.url и -notifier.url опискаются когда мы используем vmalert только для применения recording rules
Multiple remote writes
Для указания пункта сохранения данных используется флаг -remoteWrite.url, но он принимает в себя только одно значение. Чтобы сохранять данные в множество хранилищ рекомендуется использовать vmagent как fan-out proxy:
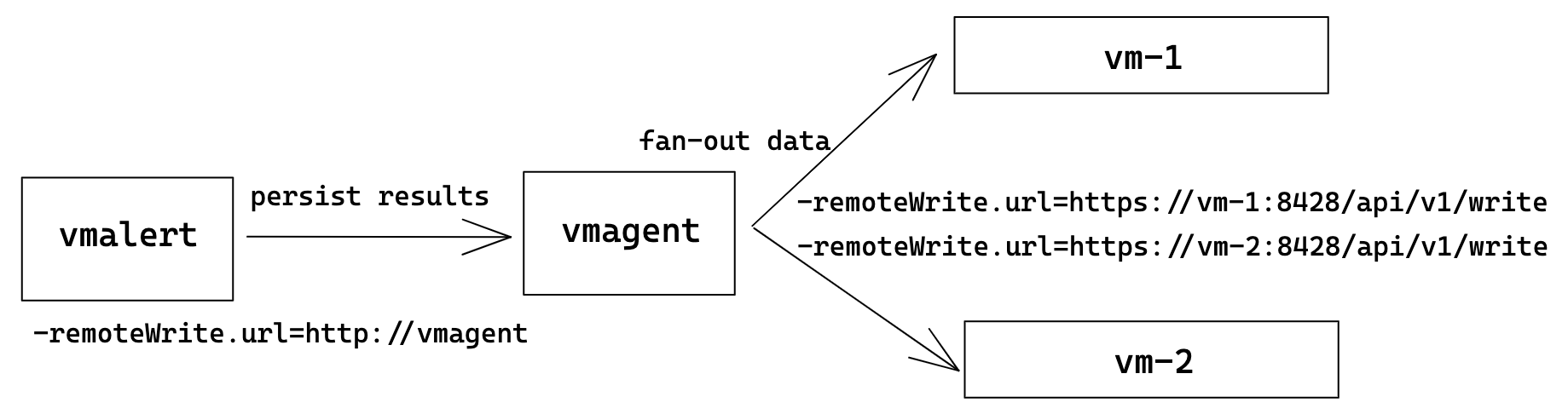
При такой топологии vmalert шлет данные в vmagent, который в свою очередь кладет полученные данные в указанные у него -remoteWrite.url
Использование vmagent'a дает ряд дополнительных фич, таких как сохранение данных когда сторадж не доступен или модификация таймсерий через релейблинг
Web
vmalert предоставляет фронтенд который доступен на -httpListenAddr. Он предоставляет он предоставляет метрики и данные по алертам (как у прометеуса):
-
http://<vmalert-addr>- UI
-
http://<vmalert-addr>/api/v1/rules- список групп и рулов
-
http://<vmalert-addr>/api/v1/alerts- список активных алертов
-
http://<vmalert-addr>/vmalert/api/v1/alert?group_id=<group_id>&alert_id=<alert_id>- статус конкретного алерта в JSON, используется как alert source для Alertmanager'a
-
http://<vmalert-addr>/vmalert/alert?group_id=<group_id>&alert_id=<alert_id>- WEB UI страница по конкретному алерту
-
http://<vmalert-addr>/metrics- метрики -
http://<vmalert-addr>/-/reload- хэндлер для релоада конфигурации
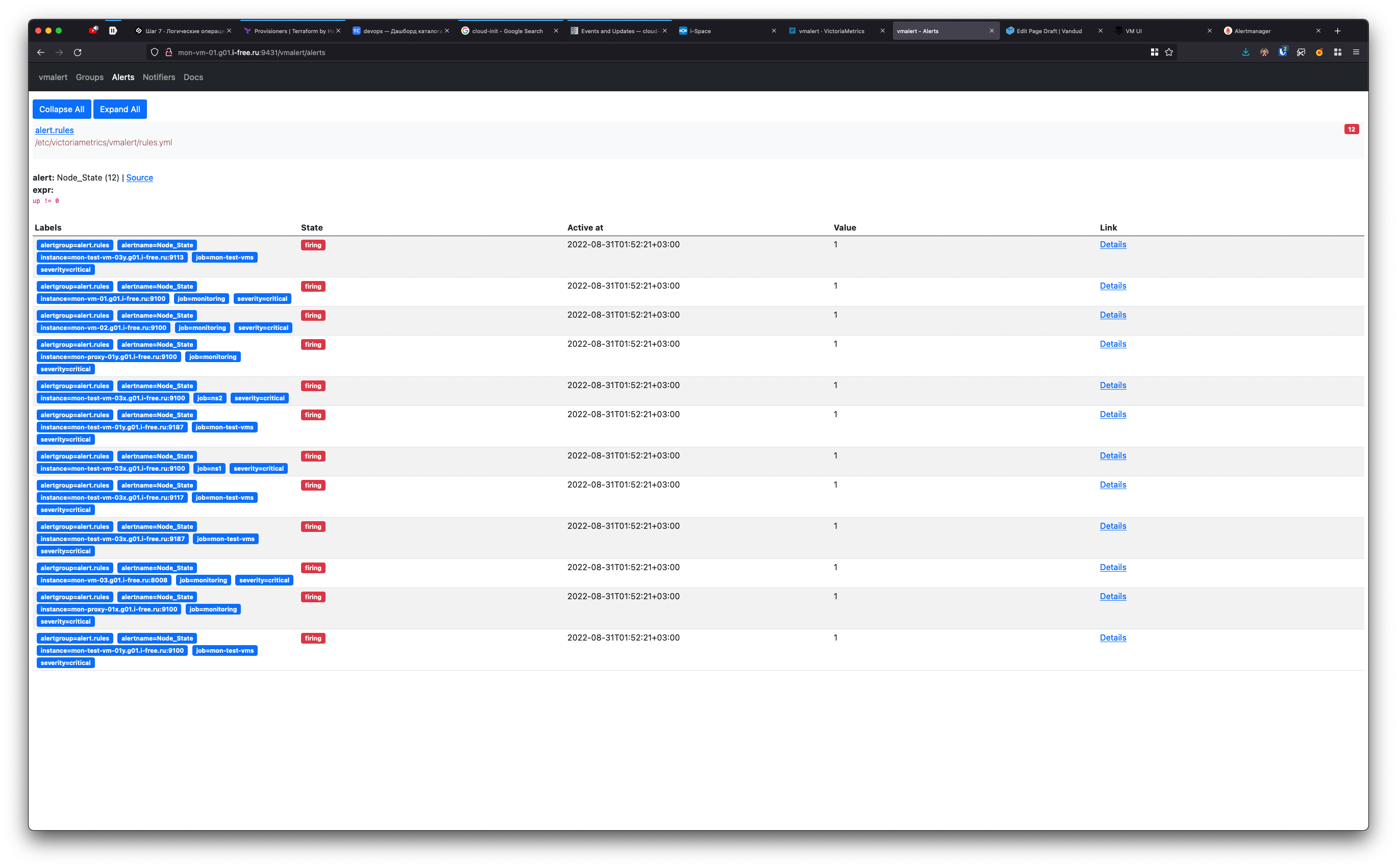
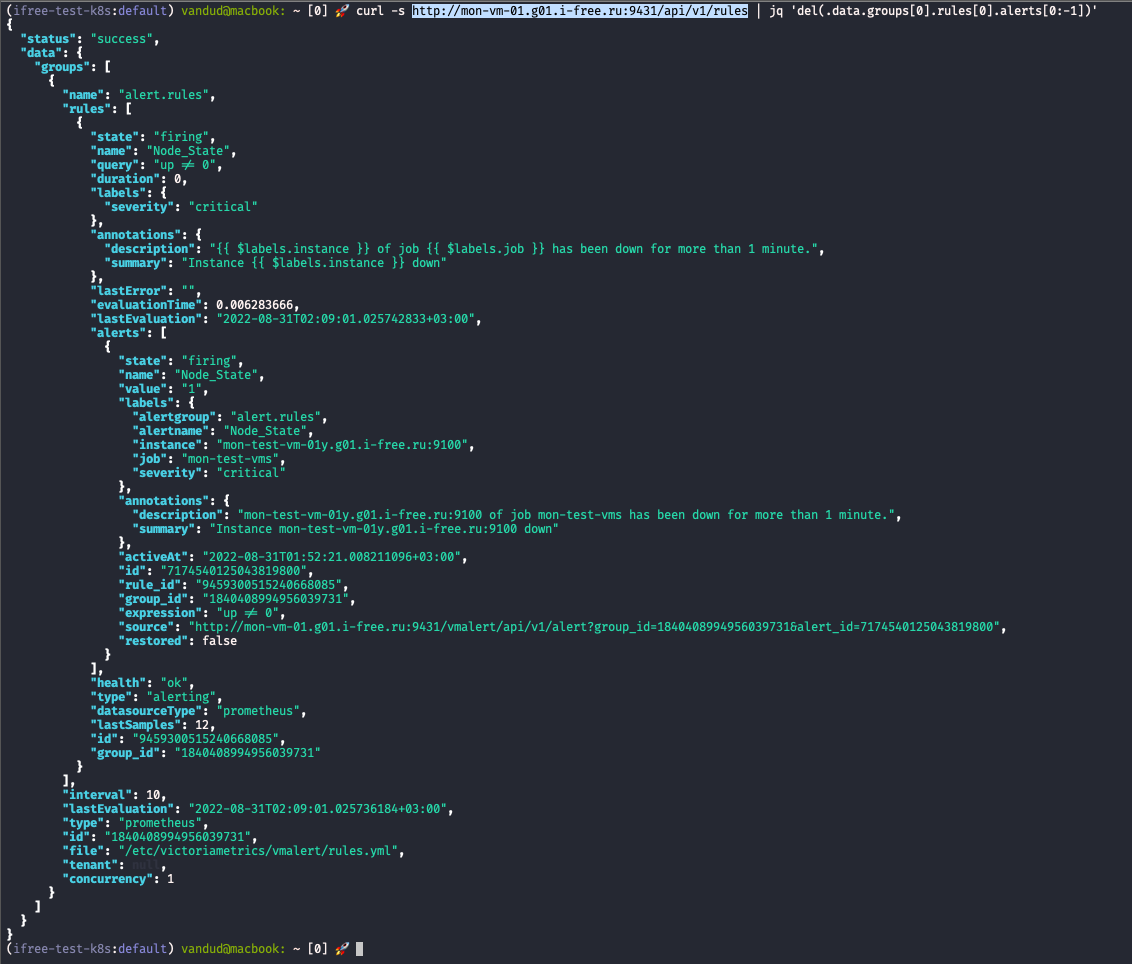
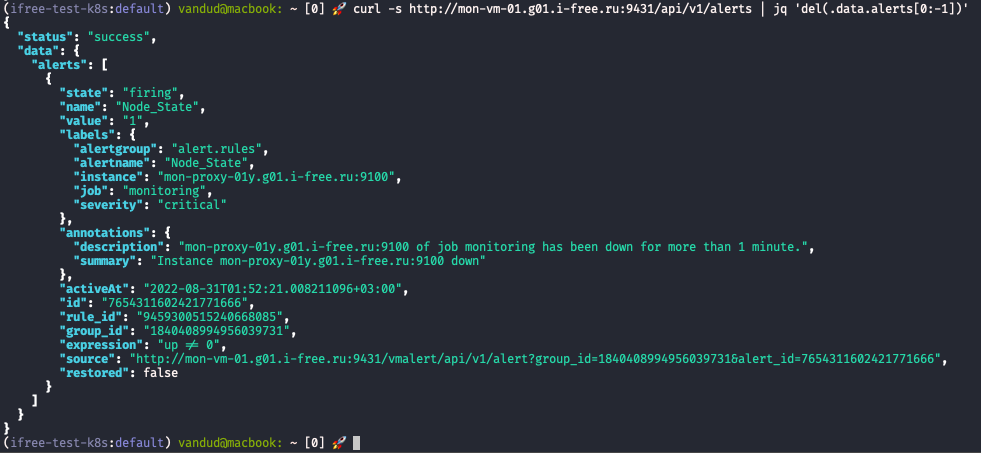
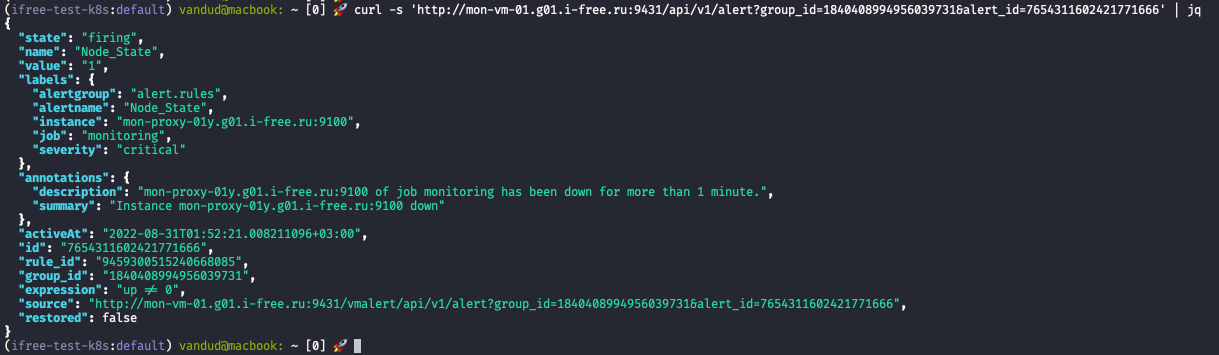
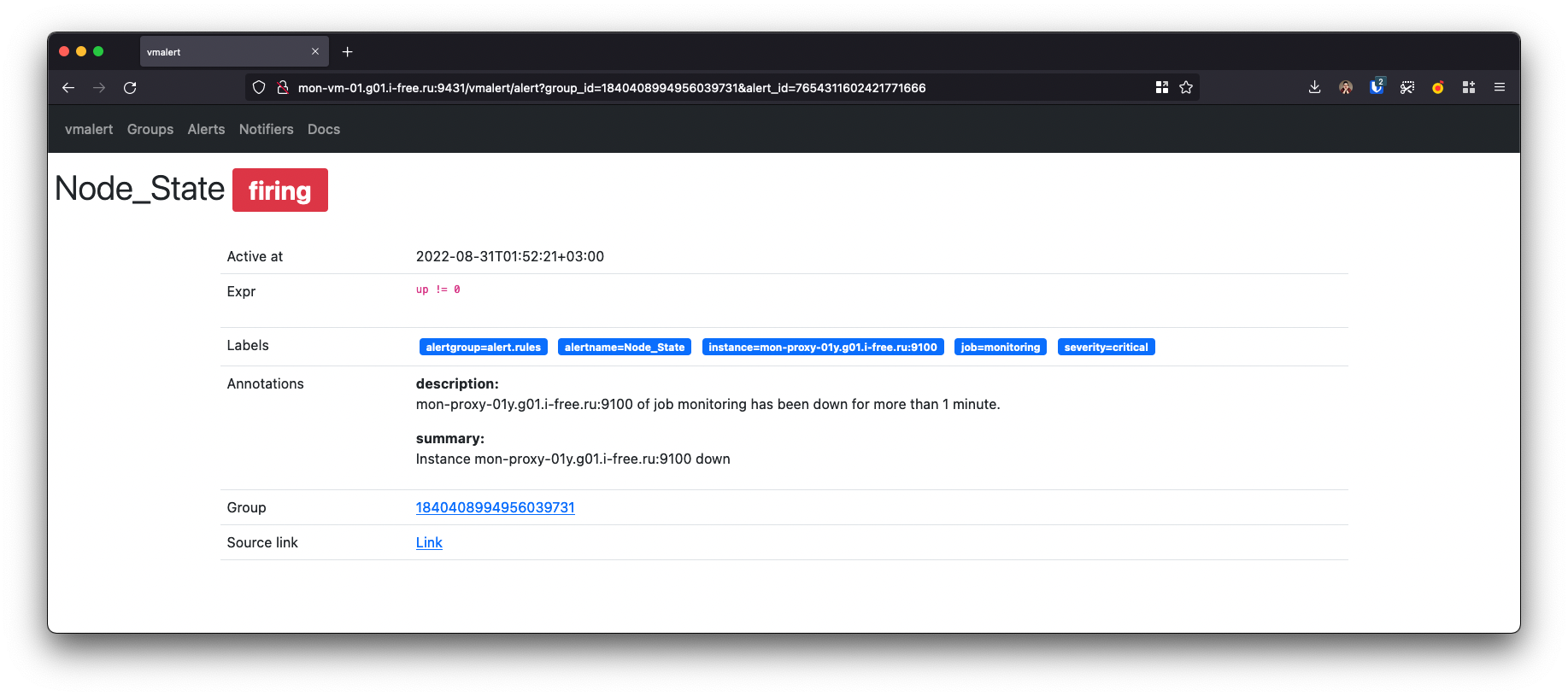
WEB UI vmalert'a может быть доступным из Виктории
Для этого ей нужно указать флаг -vmalert.proxyURL
Это нужно например для графаны
Graphite
Не интересно
Rules backfilling
vmalert поддерживает alerting и recording rules backfilling (aka replay). В реплей моде он может применить правила на указанный временной диапазон и записать результат в указанный remote storage
How it works
В replay mode vmalert работает как cli утилита и завершается сразу после завершения работы
root@mon-vm-01:~# ./vmalert-prod --datasource.url=http://localhost:8481/select/0/prometheus --notifier.url=http://localhost:9093 -remoteWrite.url=http://localhost:8480/insert/0/prometheus --rule=/etc/victoriametrics/vmalert/rules.yml -eula -replay.timeFrom=2022-08-31T02:20:00Z -replay.timeTo=2022-08-31T02:30:00Z
Copyright 2018-2022 VictoriaMetrics, Inc - All Rights Reserved.
For any questions please contact info@victoriametrics.com
2022-08-30T23:37:12.757Z info VictoriaMetrics/lib/logger/flag.go:12 build version: vmalert-20220808-174744-tags-v1.80.0-enterprise-0-gccf72e410
2022-08-30T23:37:12.757Z info VictoriaMetrics/lib/logger/flag.go:13 command-line flags
2022-08-30T23:37:12.757Z info VictoriaMetrics/lib/logger/flag.go:20 -datasource.url="http://localhost:8481/select/0/prometheus"
2022-08-30T23:37:12.757Z info VictoriaMetrics/lib/logger/flag.go:20 -eula="true"
2022-08-30T23:37:12.757Z info VictoriaMetrics/lib/logger/flag.go:20 -notifier.url="http://localhost:9093"
2022-08-30T23:37:12.757Z info VictoriaMetrics/lib/logger/flag.go:20 -remoteWrite.url="http://localhost:8480/insert/0/prometheus"
2022-08-30T23:37:12.757Z info VictoriaMetrics/lib/logger/flag.go:20 -replay.timeFrom="2022-08-31T02:20:00Z"
2022-08-30T23:37:12.757Z info VictoriaMetrics/lib/logger/flag.go:20 -replay.timeTo="2022-08-31T02:30:00Z"
2022-08-30T23:37:12.757Z info VictoriaMetrics/lib/logger/flag.go:20 -rule="/etc/victoriametrics/vmalert/rules.yml"
Replay mode:
from: 2022-08-31 02:20:00 +0000 UTC
to: 2022-08-31 02:30:00 +0000 UTC
max data points per request: 1000
Group "alert.rules"
interval: 1m0s
requests to make: 1
max range per request: 16h40m0s
> Rule "Node_State" (ID: 9459300515240668085)
1 / 1 [---------------------------------------------------------------------------------------------------------------------------------------------------------] 100.00% ? p/s
> Rule "recorded_metric" (ID: 331216927271362772)
1 / 1 [---------------------------------------------------------------------------------------------------------------------------------------------------------] 100.00% ? p/s
2022-08-30T23:37:14.792Z info VictoriaMetrics/app/vmalert/replay.go:81 replay finished! Imported 11 samples
Группы обрабатываются поочередно, правила в группах обрабатыватся поочередно (concurrency нет)
vmalert шлет выражение рула на эндпоинт /query_range указанного -datasource.url
В примере выше был сделан примерно такой запрос (здесь результат изменен для краткости):
(ifree-test-k8s:default) vandud@macbook: ~ [0] ? curl -s 'http://mon-vm-01.g01.i-free.ru:8481/select/0/prometheus/api/v1/query_range?query=1&start=2022-08-31T02:20:00Z&end=2022-08-31T02:30:00Z&step=1m' | jq 'del(.data.result[0].values[0:-1])'
{
"status": "success",
"isPartial": false,
"data": {
"resultType": "matrix",
"result": [
{
"metric": {},
"values": [
[
1661913000,
"1"
]
]
}
]
}
}
Полученные данные процессятся в соответствии с rule type и бэкфиллятся в -remoteWrite.url
vmalert использует evaluationInterval указанный через флаг или указанный в параметрах группы
Так же он автоматически выключает кэш на стороне VictoriaMetrics засылая ей параметр nocache=1, это позволяет предотвратить загрязнение кэша и нежелательное корректирование временных границ на протяжении backfilling'a
Результат реплея рекординг рулов должен совпадать с тем как если бы эти рулы выполнялись естественным путем
Результат реплея алертинг рулов это таймсерия ALERTS отражающая стейты алертов. Реплей алертрулов позволяет посмотреть как вел бы себя алерт в прошлом
Addtional configuration
Дополнительные необязательные флаги для реплея:
-
-replay.maxDatapointsPerQuery- максимальное количество сэмплов которые можно получить в ответ на запрос. При более высоких значениях будет сделано меньшее количество запросов на протяжении реплея -
-replay.ruleRetryAttempts- когда датасорс не отвечает на запрос, vmalert сделает указанное количество повторных попыток на каждый рул (то есть это лимит на количество повторов per rule) -
-replay.rulesDelay- задержка между рулами. Это применимо в случаях когда одни рулы зависят от других. Смысл в том что сторадж может иметь задержку между тем как данные в него отправлены и когда они будут доступны на чтение. Рекомендуется держать значение этого флага равным или большим чем-remoteWrite.flushInterval -
-replay.disableProgressBar- выключает прогресс бар. Это может быть полезно потому что лог работы может быть очень большим, и он не форматируется как типичный лог, а это может зааффектить систему сбора логов
Limitations
- Graphite engine не поддерживается для бэкфиллинга
-
querytemplate function выключена ради производительности - Параметр
limitв группах не имеет влияния на процесс реплея
Monitoring
vmalert экспозит различные метрики на эндпоинте /metrics
Есть официальный дашборд для графаны https://grafana.com/grafana/dashboards/14950-vmalert/
Profiling
vmalert предоставляет хэндлеры для сбора Go профилей:
- Memory profile - curl http://vmalert/debug/pprof/heap > mem.pprof
- CPU profile - curl http://vmalert/debug/pprof/profile > cpu.pprof
Команда для сбора CPU профиля сперва ждет 30 секунд и только потом возращает результат
Собранные профили можно проанализировать утилитой https://github.com/google/pprof
Файлы профилей не содержат сенсетивной информации поэтому их можно без страха шарить кому-то
Configuration
Flags
vmalert имеет еще массу различных флагов, актуальную справку по которым можно увидеть запустив vmalert -help
Hot config reload
Плавно релоаднуть конфигурацию можно следующими образами:
- Послать
SIGHUPсигнал процессу - Послать GET запрос на эндпоинт
/-/reload - Настроить флаг
-configCheckIntervalдля автоматического периодического релоада
URL params
Чтобы добавить какие-то дополнительные параметры для datasource.url, remoteWrite.url или remoteRead.url можно просто добавить их в url. Например - -datasource.url=http://localhost:8428?nocache=1
Чтобы добавить такие параметры для конкретных групп правил можно добавить секцию params в конфиге:
groups:
- name: TestGroup
params:
denyPartialResponse: ["true"]
extra_label: ["env=dev"]
Параметры используются только для применения выражений из правил, если происходит конфликт между параметрами из конфига и из флага то параметры из конфига будут иметь более высокий приоритет
Notifier configuration file
Notifier может быть законфигурирован через конфиг указанный в флаге -notifier.config:
./bin/vmalert -rule=app/vmalert/config/testdata/rules.good.rules \
-datasource.url=http://localhost:8428 \
-notifier.config=app/vmalert/notifier/testdata/consul.good.yaml
Конфиг позволяет описать статические нотифайеры и обнаруженные через Consul или DNS
static_configs:
- targets:
- localhost:9093
- localhost:9095
consul_sd_configs:
- server: localhost:8500
services:
- alertmanager
dns_sd_configs:
- names:
- my.domain.com
type: 'A'
port: 9093
Список всех нотифайеров виден в UI
Спецификация конфига:
# Per-target Notifier timeout when pushing alerts.
[ timeout: <duration> | default = 10s ]
# Prefix for the HTTP path alerts are pushed to.
[ path_prefix: <path> | default = / ]
# Configures the protocol scheme used for requests.
[ scheme: <scheme> | default = http ]
# Sets the `Authorization` header on every request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: <string> ]
[ password: <secret> ]
[ password_file: <string> ]
# Optional `Authorization` header configuration.
authorization:
# Sets the authentication type.
[ type: <string> | default: Bearer ]
# Sets the credentials. It is mutually exclusive with
# `credentials_file`.
[ credentials: <secret> ]
# Sets the credentials to the credentials read from the configured file.
# It is mutually exclusive with `credentials`.
[ credentials_file: <filename> ]
# Configures the scrape request's TLS settings.
# see https://prometheus.io/docs/prometheus/latest/configuration/configuration/#tls_config
tls_config:
[ <tls_config> ]
# List of labeled statically configured Notifiers.
static_configs:
targets:
[ - '<host>' ]
# List of Consul service discovery configurations.
# See https://prometheus.io/docs/prometheus/latest/configuration/configuration/#consul_sd_config
consul_sd_configs:
[ - <consul_sd_config> ... ]
# List of DNS service discovery configurations.
# See https://prometheus.io/docs/prometheus/latest/configuration/configuration/#dns_sd_config
dns_sd_configs:
[ - <dns_sd_config> ... ]
# List of relabel configurations for entities discovered via service discovery.
# Supports the same relabeling features as the rest of VictoriaMetrics components.
# See https://docs.victoriametrics.com/vmagent.html#relabeling
relabel_configs:
[ - <relabel_config> ... ]
# List of relabel configurations for alert labels sent via Notifier.
# Supports the same relabeling features as the rest of VictoriaMetrics components.
# See https://docs.victoriametrics.com/vmagent.html#relabeling
alert_relabel_configs:
[ - <relabel_config> ... ]
Конфигурация может быть плавно релоаднута
Тесты для VictoriaMetrics
- мультитенантность определяется
accountIdиprojectId, если projectId не указан то он автоматом устанавливается в0
вопрос: если указывать projectId как 0 или не указывать совсем то результат будет одинаковым? - проверить работу флага
-rpc.disableCompressionна инсертах и сторажах (похоже в нашем кейсе сжатие не нужно) - нужно нагенерить данных на год и протестировать производительность работы кластера на новых и старых данных (нужно понять есть ли просадка производительности при long term хранении)
- нужно понять как тарифицировать пользователей, за хранение метрик (per Gb) или за запросы в хранилище (они ж грузят кластер) или все вместе или еще как-то...
- что по энтерпрайз версии? что вообще такое enterprise у victoriametrics? мы можем использовать энтерпрайз бинари бесплатно?
- агент для мультитенантности использует лейблы, вопрос: лейбл может быть прям на метрике? или только на таргете? может ли клиент просунуть такой лейбл в свои экспортеры и заложить свои данные в чужой неймспейс? если да то как обезопаситься?
scrape_interval,scrape_align_interval,scrape_offset- как работает?- как работает staleness? на что влияет?
- при включенном дебаге релейблинга метрики будут дропаться или все же сохраняться?
Setup
Используется версия 1.80.0 - https://github.com/VictoriaMetrics/VictoriaMetrics/releases/tag/v1.80.0
https://github.com/VictoriaMetrics/VictoriaMetrics/releases/download/v1.80.0/victoria-metrics-linux-amd64-v1.80.0-cluster.tar.gz
https://github.com/VictoriaMetrics/VictoriaMetrics/releases/download/v1.80.0/vmutils-linux-amd64-v1.80.0.tar.gz
vmalert придется использовать версии enterprise
Указанные выше архивы содержат бинари с приложениями
Все приложения из обоих архивов распакованы в /usr/local/bin/*
Из имен бинарей убрано окончание -prod: vmstorage-prod -> vmstorage
root@mon-vm-01:/usr/local/bin# ls -1
vmagent-prod
vmalert-prod
vmauth-prod
vmbackup-prod
vmctl-prod
vminsert-prod
vmrestore-prod
vmselect-prod
vmstorage-prod
root@mon-vm-01:/usr/local/bin# ls -1 | cut -d'-' -f1 | xargs -I{} mv {}-prod {}
root@mon-vm-01:/usr/local/bin# ls -1
vmagent
vmalert
vmauth
vmbackup
vmctl
vminsert
vmrestore
vmselect
vmstorage
Создан пользователь victoriametrics с группой victoriametrics
useradd -d /nonexistent -M -r -s /usr/sbin/nologin -U victoriametrics
systemd service взят отсюда - https://github.com/VictoriaMetrics/ansible-playbooks/blob/master/roles/vmagent/templates/vmagent.service.j2
Вот такой шаблон для списка сервисов:
- vmagent
- vmalert
- vmauth
- vminsert
- vmselect
- vmstorage
[Unit]
Description=VictoriaMetrics ${app}
After=network.target
[Service]
Type=simple
User=victoriametrics
Group=victoriametrics
EnvironmentFile=/etc/${app}/${app}.conf
ExecStart=/usr/local/bin/${app} -envflag.enable
ExecReload=/bin/kill -SIGHUP $MAINPID
SyslogIdentifier=${app}
Restart=always
PrivateTmp=yes
ProtectHome=yes
NoNewPrivileges=yes
ProtectSystem=full
ProtectControlGroups=true
ProtectKernelModules=true
ProtectKernelTunables=yes
[Install]
WantedBy=multi-user.target
Создать сервисы:
root@mon-vm-01:~# echo 'vmagent
vmalert
vmauth
vminsert
vmselect
vmstorage' | xargs -I{} sh -c "sed -e 's/\${app}/{}/g' app.service > {}.service"
root@mon-vm-01:~# cat vmagent.service
[Unit]
Description=VictoriaMetrics vmagent
After=network.target
[Service]
Type=simple
User=victoriametrics
Group=victoriametrics
EnvironmentFile=/etc/vmagent/vmagent.conf
ExecStart=/usr/local/bin/vmagent -envflag.enable
SyslogIdentifier=vmagent
Restart=always
PrivateTmp=yes
ProtectHome=yes
NoNewPrivileges=yes
ProtectSystem=full
ProtectControlGroups=true
ProtectKernelModules=true
ProtectKernelTunables=yes
[Install]
WantedBy=multi-user.target
root@mon-vm-01:~# mv !(app.service) /etc/systemd/system/.
root@mon-vm-01:~# ls
app.service
root@mon-vm-01:~# systemctl daemon-reload
root@mon-vm-01:~# systemctl status vmagent
● vmagent.service - Description=VictoriaMetrics vmagent
Loaded: loaded (/etc/systemd/system/vmagent.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Заэнейблить сервисы:
root@mon-vm-01:~# echo 'vmagent
vmalert
vmauth
vminsert
vmselect
vmstorage' | xargs -I{} systemctl enable {}
Created symlink /etc/systemd/system/multi-user.target.wants/vmagent.service → /etc/systemd/system/vmagent.service.
Created symlink /etc/systemd/system/multi-user.target.wants/vmalert.service → /etc/systemd/system/vmalert.service.
Created symlink /etc/systemd/system/multi-user.target.wants/vmauth.service → /etc/systemd/system/vmauth.service.
Created symlink /etc/systemd/system/multi-user.target.wants/vminsert.service → /etc/systemd/system/vminsert.service.
Created symlink /etc/systemd/system/multi-user.target.wants/vmselect.service → /etc/systemd/system/vmselect.service.
Created symlink /etc/systemd/system/multi-user.target.wants/vmstorage.service → /etc/systemd/system/vmstorage.service.
Приложения конфигурируются через переменные окружения (https://docs.victoriametrics.com/Cluster-VictoriaMetrics.html#environment-variables)
В файле /etc/${app}/${app}.conf лежит список переменных в формате:
insert_maxQueueDuration=<duration>
...
То есть это просто имя флага где точка заменена на подчеркивание
Создать папки для конфигов приложений:
root@mon-vm-01:~# echo 'vmagent
vmalert
vmauth
vminsert
vmselect
vmstorage' | xargs -I{} sh -c "mkdir /etc/{}; chmod 755 /etc/{}"
root@mon-vm-01:~# ls -1 /etc/ | grep vm
vmagent
vmalert
vmauth
vminsert
vmselect
vmstorage
vmalert взят из enterprise версии https://github.com/VictoriaMetrics/VictoriaMetrics/releases/download/v1.80.0/vmutils-linux-amd64-v1.80.0-enterprise.tar.gz
Конфигурирование:
- vmstorage:
-storageDataPath-/var/lib/vmstoragemkdir /var/lib/vmstorage chown -R victoriametrics:victoriametrics /var/lib/vmstorage
- vmselect:
-cacheDataPath-/var/lib/vmselect
node_exporter версии 1.3.1 - https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz
Пользователь:
useradd -d /nonexistent -M -r -s /usr/sbin/nologin -U node_exporter
systemd service:
[Unit]
Description=Node Exporter
After=network.target
[Service]
Type=simple
User=node_exporter
Group=node_exporter
ExecStart=/usr/local/bin/node_exporter
SyslogIdentifier=node_exporter
Restart=always
PrivateTmp=yes
ProtectHome=yes
NoNewPrivileges=yes
ProtectSystem=full
ProtectControlGroups=true
ProtectKernelModules=true
ProtectKernelTunables=yes
[Install]
WantedBy=multi-user.target
windows_exporter 0.19.0
https://github.com/prometheus-community/windows_exporter/releases/tag/v0.19.0
https://github.com/prometheus-community/windows_exporter
mon-proxy-01
аналогичным всем остальным утилитам способ установлен vmauth
Порты везде открываются через AWX
Для решения вот этой проблемы https://github.com/VictoriaMetrics/VictoriaMetrics/issues/3061 используется nginx
Со следующей конфигурацией:
root@mon-proxy-01x:/etc/vmauth# cat /etc/nginx/sites-enabled/default
upstream vminsert {
server mon-vm-01.g01.i-free.ru:8480;
server mon-vm-02.g01.i-free.ru:8480;
server mon-vm-03.g01.i-free.ru:8480;
}
upstream vmselect {
server mon-vm-01.g01.i-free.ru:8481;
server mon-vm-02.g01.i-free.ru:8481;
server mon-vm-03.g01.i-free.ru:8481;
}
server {
listen 8428;
location /insert {
proxy_pass http://vminsert;
}
location /select {
proxy_pass http://vmselect;
}
}
Alertmanager version - 0.24.0
https://github.com/prometheus/alertmanager/releases/download/v0.24.0/alertmanager-0.24.0.linux-amd64.tar.gz
Бинари alertmanager и amtool кладутся в /usr/local/bin/.
Пользователь:
useradd -d /nonexistent -M -r -s /usr/sbin/nologin -U alertmanager
Создать папку для хранения стейтов алертов (что акнуто, что отправлено, итд):
mkdir /var/lib/alertmanager; chown -R alertmanager:alertmanager /var/lib/alertmanager
Папка для конфигов:
mkdir /etc/alertmanager; chown -R alertmanager:alertmanager /etc/alertmanager/
systemd service:
root@mon-vm-01:~# cat /etc/systemd/system/alertmanager.service
[Unit]
Description=Alertmanager
After=network.target
[Service]
Type=simple
User=alertmanager
Group=alertmanager
ExecStart=/usr/local/bin/alertmanager --config.file=/etc/alertmanager/main.yaml --storage.path=/var/lib/alertmanager/ --log.level=debug --cluster.peer=mon-vm-02.g01.i-free.ru:9094 --cluster.peer=mon-vm-03.g01.i-free.ru:9094
ExecReload=/bin/kill -SIGHUP $MAINPID
SyslogIdentifier=alertmanager
Restart=always
PrivateTmp=yes
ProtectHome=yes
NoNewPrivileges=yes
ProtectSystem=full
ProtectControlGroups=true
ProtectKernelModules=true
ProtectKernelTunables=yes
[Install]
WantedBy=multi-user.target
grafana
stable релиз по инструкции - https://grafana.com/docs/grafana/latest/setup-grafana/installation/debian/
apt-get install -y apt-transport-https; apt-get install -y software-properties-common wget; wget -q -O /usr/share/keyrings/grafana.key https://packages.grafana.com/gpg.key; echo "deb [signed-by=/usr/share/keyrings/grafana.key] https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list; apt-get update; apt-get install grafana
Prometheus-msteams version - 1.5.1 https://github.com/prometheus-msteams/prometheus-msteams/releases/download/v1.5.1/prometheus-msteams-linux-amd64
бинарь в /usr/local/bin/
юзер
useradd -d /nonexistent -M -r -s /usr/sbin/nologin -U prometheus-msteams
папка для конфигов
mkdir /etc/prometheus-msteams; chown -R prometheus-msteams:prometheus-msteams /etc/prometheus-msteams
конфиг и шаблон для алерта
vim /etc/prometheus-msteams/config.yml
connectors:
- alert_channel: "WEBHOOK"
vim /etc/prometheus-msteams/card.tmpl
{{ define "teams.card" }}
{
"@type": "MessageCard",
"@context": "http://schema.org/extensions",
"themeColor": "{{- if eq .Status "resolved" -}}2DC72D
{{- else if eq .Status "firing" -}}
{{- if eq .CommonLabels.severity "critical" -}}8C1A1A
{{- else if eq .CommonLabels.severity "warning" -}}FFA500
{{- else -}}808080{{- end -}}
{{- else -}}808080{{- end -}}",
"summary": "VictoriaMetrics Alerts",
"title": "VictoriaMetrics ({{ .Status }})",
"sections": [ {{$externalUrl := .ExternalURL}}
{{- range $index, $alert := .Alerts }}{{- if $index }},{{- end }}
{
"facts": [
{{- range $key, $value := $alert.Annotations }}
{
"name": "{{ reReplaceAll "_" "\\\\_" $key }}",
"value": "{{ reReplaceAll "_" "\\\\_" $value }}"
},
{{- end -}}
{{$c := counter}}{{ range $key, $value := $alert.Labels }}{{if call $c}},{{ end }}
{
"name": "{{ reReplaceAll "_" "\\\\_" $key }}",
"value": "{{ reReplaceAll "_" "\\\\_" $value }}"
}
{{- end }}
],
"markdown": true
}
{{- end }}
]
}
{{ end }}
создаем юнит
vim /etc/systemd/system/prometheus-msteams.service
[Unit]
Description=Prometheus-msteams
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus-msteams
Group=prometheus-msteams
Type=simple
ExecStart=/usr/local/bin/prometheus-msteams -config-file /etc/prometheus-msteams/config.yml -template-file /etc/prometheus-msteams/card.tmpl
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start prometheus-msteams.service
systemctl enable prometheus-msteams.service
OpenResty установлен по этой статье https://www.installing.in/how-to-install-openresty-on-debian-10/
Изменения в systemd сервисе
root@mon-proxy-01y:/usr/local/openresty# diff /tmp/openresty.service.old /lib/systemd/system/openresty.service
21,24c21,24
< ExecStartPre=/usr/local/openresty/nginx/sbin/nginx -t -q -g 'daemon on; master_process on;'
< ExecStart=/usr/local/openresty/nginx/sbin/nginx -g 'daemon on; master_process on;'
< ExecReload=/usr/local/openresty/nginx/sbin/nginx -g 'daemon on; master_process on;' -s reload
< ExecStop=-/sbin/start-stop-daemon --quiet --stop --retry QUIT/5 --pidfile /usr/local/openresty/nginx/logs/nginx.pid
---
> ExecStartPre=/usr/local/openresty/nginx/sbin/nginx -t -q -g 'daemon on; master_process on;' -c /etc/nginx/nginx.conf
> ExecStart=/usr/local/openresty/nginx/sbin/nginx -g 'daemon on; master_process on;' -c /etc/nginx/nginx.conf
> ExecReload=/usr/local/openresty/nginx/sbin/nginx -g 'daemon on; master_process on;' -s reload -c /etc/nginx/nginx.conf
> ExecStop=-/sbin/start-stop-daemon --quiet --stop --retry QUIT/5 --pidfile /usr/local/openresty/nginx/logs/nginx.pid -c /etc/nginx/nginx.conf
Так же нужно перенести дефолтный конфиг openresty в /etc/nginx:
root@mon-proxy-01y:/etc/nginx# rm -rf !(sites-enabled) ^C
root@mon-proxy-01y:/etc/nginx# cp -R /usr/local/openresty/nginx/conf/. /etc/nginx/. ^C
И привести секцию http в nginx.conf к следующему виду:
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/sites-enabled/*;
}
apt install libjq-dev
Вместо alertmanager'a используется cortex-alertmanager (потому что у нем есть multitenancy)
Взята версия Cortex 1.13.0
https://github.com/cortexproject/cortex/releases/download/v1.13.0/cortex-linux-amd64
Директория для конфигов - /etc/cortex-alertmanager
root@mon-vm-01:/etc/cortex-alertmanager# tree
.
├── configs
│ └── 1.yml
├── fallback.yaml
└── main.yaml
1 directory, 3 files
root@mon-vm-01:/etc/cortex-alertmanager# cat main.yaml
target: alertmanager
server:
http_listen_port: 9093
alertmanager:
external_url: http://mon-vm-01.test.i-free.ru:9093/alertmanager
data_dir: /var/lib/cortex-alertmanager
retention: 120h
poll_interval: 15s
sharding_enabled: false
fallback_config_file: /etc/cortex-alertmanager/fallback.yaml
# [auto_webhook_root: <string> | default = ""]
cluster:
listen_address: "0.0.0.0:9094"
advertise_address: ""
peers: "mon-vm-01.test.i-free.ru:9094,mon-vm-02.test.i-free.ru:9094,mon-vm-03.test.i-free.ru:9094"
peer_timeout: 15s
gossip_interval: 200ms
push_pull_interval: 1m
storage:
type: local
local:
path: /etc/cortex-alertmanager/configs
wget https://github.com/cortexproject/cortex/releases/download/v1.13.0/cortex-linux-amd64 -O /usr/local/bin/cortex-alertmanager
chmod 755 /usr/local/bin/cortex-alertmanager
useradd -d /nonexistent -M -r -s /usr/sbin/nologin -U cortex-alertmanager
systemd unit:
cat <<EOF > /etc/systemd/system/cortex-alertmanager.service
[Unit]
Description=Horizontally scalable, highly available, multi-tenant, long term Prometheus.
Documentation=https://cortexmetrics.io/docs
Wants=network-online.target
After=network-online.target
[Service]
Restart=always
User=cortex-alertmanager
ExecStart=/usr/local/bin/cortex-alertmanager --config.file /etc/cortex-alertmanager/main.yaml
ExecReload=/bin/kill -HUP $MAINPID
TimeoutStopSec=20s
SendSIGKILL=no
WorkingDirectory=/var/lib/cortex-alertmanager
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
mkdir /var/lib/cortex-alertmanager; chown -R cortex-alertmanager:cortex-alertmanager /var/lib/cortex-alertmanager
mkdir /etc/cortex-alertmanager; chown -R cortex-alertmanager:cortex-alertmanager /etc/cortex-alertmanager
mkdir /etc/cortex-alertmanager/configs; chown -R cortex-alertmanager:cortex-alertmanager /etc/cortex-alertmanager/configs/
systemctl enable cortex-alertmanager.service
Grafana Provisioning
Организации можно создавать только вручную (или через API)
Поэтому пока будем делать их вручную
LDAP
группы в ldap под тенанты кроме первого тенанта
в первый тенант (monitoring) добавляем по группе techsupp@i-free.com
Для ансиблизирования keepalived использована эта роль https://github.com/Oefenweb/ansible-keepalived (немного модифицирована)
Переналив машин
mon-proxy-01x.g01.i-free.ru (hoster-kvm-23.g01.i-free.ru)
virsh shutdown mon-proxy-01x.g01.i-free.ru
virsh undefine --remove-all-storage mon-proxy-01x.g01.i-free.ru
vm_create.sh -m 1024 -c 1 -s 20 -b vlanbr294 -i 172.27.245.237 -n 255.255.255.0 -g 172.27.247.254 ifree-buster-2.tar mon-proxy-01x.g01.i-free.ru -d "172.27.245.100" -e "Monitoring (prod)" --cpu-model SandyBridge
virsh -c qemu:///system start mon-proxy-01x.g01.i-free.ru
virsh attach-interface mon-proxy-01x.g01.i-free.ru bridge vlanbr300 --model virtio --persistent
mon-proxy-01y.g01.i-free.ru (hoster-kvm-24.g01.i-free.ru)
virsh shutdown mon-proxy-01y.g01.i-free.ru
virsh undefine --remove-all-storage mon-proxy-01y.g01.i-free.ru
vm_create.sh -m 1024 -c 1 -s 20 -b vlanbr294 -i 172.27.245.227 -n 255.255.255.0 -g 172.27.247.254 ifree-buster-2.tar mon-proxy-01y.g01.i-free.ru -d "172.27.245.100" -e "Monitoring (prod)" --cpu-model SandyBridge
virsh -c qemu:///system start mon-proxy-01y.g01.i-free.ru
virsh attach-interface mon-proxy-01y.g01.i-free.ru bridge vlanbr300 --model virtio --persistent
mon-exporters-01x.g01.i-free.ru (hoster-kvm-25.g01.i-free.ru)
vm_create.sh -m 4096 -c 4 -s 40 -b vlanbr294 -i 172.27.245.248 -n 255.255.255.0 -g 172.27.247.254 ifree-buster-2.tar mon-exporters-01x.g01.i-free.ru -d "172.27.245.100" -e "Monitoring (prod)" --cpu-model SandyBridge
virsh attach-interface mon-exporters-01x.g01.i-free.ru bridge vlanbr300 --model virtio --persistent
mon-exporters-01y.g01.i-free.ru (hoster-kvm-24.g01.i-free.ru)
vm_create.sh -m 4096 -c 4 -s 40 -b vlanbr294 -i 172.27.245.250 -n 255.255.255.0 -g 172.27.247.254 ifree-buster-2.tar mon-exporters-01y.g01.i-free.ru -d "172.27.245.100" -e "Monitoring (prod)" --cpu-model SandyBridge
virsh attach-interface mon-exporters-01y.g01.i-free.ru bridge vlanbr300 --model virtio --persistent
mtail
https://github.com/google/mtail/releases/download/v3.0.0-rc50/mtail_3.0.0-rc50_Linux_x86_64.tar.gz
Kubernetes Monitoring
Чтобы замониторить k8s с помощью VictoriaMetrics, нужно установить туда victoria-metrics-k8s-stack helm chart
Сперва подготовь вот такой вэльюс и отредактируй если нужно (обязательно подставь корректный адрес для remote write), можешь добавить каких-то лейблов для vmagent (эти лейблы будут на всех собранных метриках)
# victoria-metrics-k8s-stack.values.yaml
---
fullnameOverride: "victoria-metrics-k8s-stack"
victoria-metrics-operator:
operator:
disable_prometheus_converter: false
externalVM:
write:
url: "http://10.0.244.254:8428/api/v1/write"
# bearerTokenSecret:
# name: dbaas-read-access-token
# key: bearerToken
vmagent:
spec:
externalLabels:
cluster: test
env: test
defaultRules:
create: false
vmsingle:
enabled: false
alertmanager:
enabled: false
vmalert:
enabled: false
grafana:
enabled: false
prometheus-node-exporter:
enabled: true
kube-state-metrics:
enabled: true
kubeEtcd:
enabled: false
crds:
enabled: true
Далее задеплой это такими командами:
helm repo add vm https://victoriametrics.github.io/helm-charts/
helm install victoria-metrics-k8s-stack vm/victoria-metrics-k8s-stack --version 0.18.8 -n monitoring --create-
namespace --wait --atomic --values victoria-metrics-k8s-stack.values.yaml
Также нужно чтобы были установлены CRD от prometheus-operator (проверь, они могут быть уже установлены (например если ранее стоял kube-prometheus-stack))
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install prometheus-operator-crds prometheus-community/prometheus-operator-crds -n monitoring