Введение и базовые операции
Основные понятия БД
- Сущность - класс, хранящийся в базе данных, таблица
- Объект - экземпляр сущности
- Атрибут - свойства характеризующие сущность, название столбца в таблице
- Кортеж - строка в таблице, набор значений конкретных атрибутов
- Домен - набор допустимых значений атрибута
- Идентификатор - атрибут с уникальным значением для данной таблицы
Основные компоненты СУБД
- Ядро - процессы, сеть, память, файловая система итд
- Диспетчер данных - транзакции, кэш
- Диспетчер запросов - парсер запроса, оптимизатор, исполнитель
- Набор инструментов для служебных операций - резервное копирование, восстановление, мониторинг
Модель данных
- Объекты
- Операторы
- Описание структуры и доступа к данным
Характеристика модели данных
- Структурная часть
- Манипуляционная часть
- Ограничения целостности
Базы бывают серверные (server) и встроенные (embedded), например mssql, mysql, pgsql - серверные, sqllite - встроенная (используется например на смартфонах).
Реляционная база данных - это совокупность связанных данных, которые хранятся в таблицах.
Таблицы в такой базе как классы в ООП, каждый класс определяет свойства какого-либо типа объекта.
Поле каждой таблицы имеет следующие основные свойства (есть масса других свойств):
- Имя
- Тип данных
- Допустимость пустого значения
SQL - structed query language. (sql - то dml (data manupulation language)).
Данные в реляционной модели данных должны иметь определенный тип и быть строго типизированными, поэтоу сущеступют следующие типы данных MySQL:
- INT - целые числа
- FLOAT, DOUBLE - вещественные числа
- CHAR, VARCHAR - строки
- TEXT - строки
- DATE, DATETIME - дата и время
- BLOB - бинарные данные
- TINYINT - логические данные (true, false)
- NULL - означает отсутствие значения в ячейке
Домен - это совокупность ограничений типа данных и некоторое логическое выражение которое можно применить к элементам этого домена. Проще говоря домен это некоторое подмножество множества значений некоторого типа данных
Например для хранения количества проданных товаров можно ввести домен неотрицательных целых чисел.
Названия баз не регистрочувствительные.
create table `clients`
(
`id` int auto_increment not null,
`name` varchar(30),
`age` tinyint,
`phone` varchar(15),
primary key (`id`)
)
Сначала имя столбца, потом его тип, потом дополнительные аргументы.
В mysql есть 4 целочисленных типа данных
- tinyint - 8 бит (макс. знач. 127)
- smallint - 16 бит (макс. знач. 32676)
- int - 32 бит (макс. знач. 2*10^9)
- bigint - 64 бит (макс. знач. 9*10^18)
unsigned - увеличивает максимальное значение в два раза, но убирает отрицательные значения (то есть минимальное значение становится 0).
Можно указывать длину числового типа, но это не влияет на производительность.
Для очень больших чисел есть тип decimal, так как процессор не умеет работать с такими большими числами, то обработка их производится на стороне mysql, и это очень медленно.
Float - приблизительное значение. Процессор умеет работать с такими числами и float занимает меньше места. Его нужно использовать когда точность не очень важна.
Char/Varchar - тип для строк.
- CHAR - имеет фиксированную длину, поэтому для любой строки всегда будет выделено одно и то же количество памяти.
- VARCHAR - имеет переменную длину (не более указанной), поэтому его использование эффективнее но имеет свои недостатки.
Blob/Text - отличаются тем, что для blob не делается преобразования кодировок. По таким типам нельзя сделать сортировку, можно только по нескольким первым символам. При создании индекса по такой колонке нужно указывать длину.
Enum - значением может быть одно из заранее известных значений. Преимущество этого типа в том, что он записывает номер значения вместо самого значения в каждую строку. Этим обеспечивается огромная экономия места.
Datetime/Timestamp - отличаются следующим
- DATETIME занимает 8 байт и позволяет хранить даты с 1001 года до 9999 года.
- TIMESTAMP занимает 4 байта и позволяет хранить даты с 1970 года до 2038 года.
Для сравнения с NULL нужно использовать
is, через=не работает
desc tablename;покажет как устроена таблица
- Кортеж - набор аттрибутов сущности (строка в таблице)
Для осуществления ограничений целостности требуются ключи. Ключи бывают первичными и вторичными, но принципиальных различий между ними нет. Ключ может быть простым или составным. Простой ключ состоит из одного аттрибута, а составной из более чем одного. Ключи позволяют однозначно определить конкретную сущность (строку)
Если ключ составной, то аттрибуты входящие в состав ключа не должны иметь возможности быть неопределенными
Комментарии обозначаются двуми дефисами
-- select huemae;
Аггрегация
- count() -
select count(1) from project;покажет количество - avg(row_name) - покажет среднее между всеми значениями переданного столбца
- min/max - выводит мин/макс среди переданных данных
- group by - группирует данные по определенному столбцу
- order by - сортирует данные по определенному столбцу (desc - сортировать по убыванию)(можно указывать сразу несколько аттрибутов через запятую)
- limit - вывести N записей
Нужно делать группировку всегда когда есть обработка нескольких столбцов, иначе данные будут несовпадать
Про индексы
Как работает без индексов
- Фрагментация данных на диске - так как данные хранятся в виде последовательных блоков на диске, то чтобы открыть файл, нужно блок за блоком собрать их все с диска (информация о следующем блоке хранится в предыдущем) (данные на диске могут распологаться в разных его частях, что физически замедляет чтение).
- Поиск данных в mysql
SELECT * FROM users WHERE age = 29
Такой запрос потребует перебрать всю таблицу (строка за строкой) и сравнить значения со значением в запросе.
- Сортировка - отсортировав сначала таблицу по колонке по которой происходит поиск, скорость поиска значительно уменьшится, так как не нужно сравнивать каждую строку.
Индекс — это и есть отсортированный набор значений. В MySQL
Индексы всегда строятся для какой-то конкретной колонки.
Рассмотрим запрос из примера:
SELECT * FROM users WHERE age = 29
Нам необходимо создать индекс на колонку age:
CREATE INDEX age ON users(age);
Индексы бывают кластерными (являются частью структуры данных) и некластерными (выстраиваются вокруг структуры данных и содержат ссылки на кортежи)
Кластерный индекс строит упорядоченное дерево по первичному ключу и на листьях дерева размещает данные
Кластерные индексы самые быстрые, а некластерные чуть медленнее (потому что в некластерных происходит две операции: поиск индекса и переход к данным)
Наличие индексов замедляет обработку данных, так как при изменении данных нам требуется и изменение индексов (оно конечно происходит автоматически, но это все равно дополнительная операция)
То есть индексы ускоряют поиск, но замедляют обработку
По умолчанию для создания индексов (в том числе и кластерных) используется структура B-дерева
Кластерный индекс хранит в листьях сами данные, а некластерный лишь ссылки на данные
Типы логов в MySQL
- Error Log — стандартный лог ошибок, которые собираются во время работы сервера (в том числе start и stop);
- Binary Log — лог всех команд изменения БД, нужен для репликации и бэкапов;
- General Query Log — основной лог запросов;
- Slow Query Log — лог медленных запросов.
Join'ы
Декартово произведение - это множество элементами которого являются все возможные упорядоченные пары элементов исходных множеств
Join'ы - это набор кортежей из декартова произведения которые удовлетворяют определенному условию
Простой join (inner join) как раз и делает декартово произведение
С помощью оператора on можно указать условие
> select product.product_name, category.category_name, product.price
from product inner join category
on category.category_id = product.category_id;
Также вместо on можно использовать using() (но только если имя аттрибута в обоих таблицах одинаковое)
Разница между on и using в том что в on более гибко можно указать условие, а using выглядит проще и легче читается
using может принимать сразу несколько аттрибутов
Пример использования `using` (клик раскроет текст)
Имеется две таблицы у которых есть колонка с одинаковым именем
using - построит выборку почти как on category.id = client.id
Только еще и объединит столбец id, а on выведет его дважды
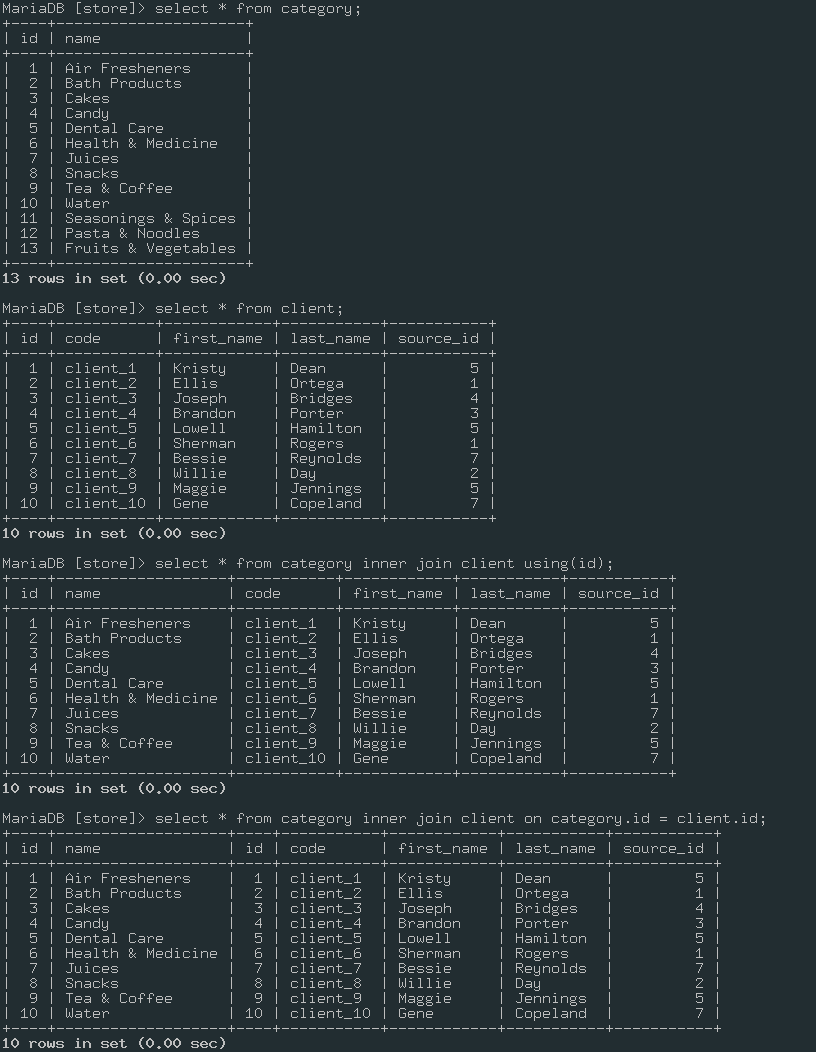

inner join, cross join, join
inner join - позволяет выбрать все кортежи, которые обязательно присутствуют в обоих таблицах
Помимо конструкции INNER JOIN внутреннее объединение можно объявить так же через CROSS JOIN и JOIN
Результат будет одинаковым
Также можно использовать запятую вместо join, но при использовании запятой нельзя использовать on или using, нужно задавать условия через where
После from можно указывать больше двух таблиц через запятую с использованием where
Также дойны можно использовать и в других операциях (не только в селектах). Еще можно делать многотабличные удаления или обновления
left join, right join
left join - левостороннее объединение выводит левую таблицу полностью и дополняет ее значениями из правой таблицы
left/right [outer] join - правые и левые объединения являются внешними, поэтому слово outer можно не писать
Внешние объединения в отличие от внутренних оставляют в выборке кортежи которые не присутствуют сразу в двух таблицах
MariaDB [store]> select * from category left join client using(id);
+----+---------------------+-----------+------------+-----------+-----------+
| id | name | code | first_name | last_name | source_id |
+----+---------------------+-----------+------------+-----------+-----------+
| 1 | Air Fresheners | client_1 | Kristy | Dean | 5 |
| 2 | Bath Products | client_2 | Ellis | Ortega | 1 |
| 3 | Cakes | client_3 | Joseph | Bridges | 4 |
| 4 | Candy | client_4 | Brandon | Porter | 3 |
| 5 | Dental Care | client_5 | Lowell | Hamilton | 5 |
| 6 | Health & Medicine | client_6 | Sherman | Rogers | 1 |
| 7 | Juices | client_7 | Bessie | Reynolds | 7 |
| 8 | Snacks | client_8 | Willie | Day | 2 |
| 9 | Tea & Coffee | client_9 | Maggie | Jennings | 5 |
| 10 | Water | client_10 | Gene | Copeland | 7 |
| 11 | Seasonings & Spices | NULL | NULL | NULL | NULL |
| 12 | Pasta & Noodles | NULL | NULL | NULL | NULL |
| 13 | Fruits & Vegetables | NULL | NULL | NULL | NULL |
+----+---------------------+-----------+------------+-----------+-----------+
13 rows in set (0.00 sec)
Как видно, левая таблица выведена полностью, а правая по возможности дополнила ее. Места где между таблицами нет перечения по аттрибуту id заполнены значением NULL
right join - Правостороннее объединение отличается от левостороннего только тем что данные изначально берутся из правой таблицы и дополняются значениями из левой
Можно менять местами имена таблиц и менять right на left, вывод останется одинаковым
Можно объединять много таблиц сразу. Максимум 61 (зависит от версии СУБД)
Также можно объединять таблицу саму с собой, но нужно использоватьASалисас, иначе возникнет ошибка об неуникальности имен
union
Union позволяет объединять результат нескольких запросов в один вывод
Пример
MariaDB [store]> select * from category where id < 5
-> union
-> select * from category where id > 10;
+----+---------------------+
| id | name |
+----+---------------------+
| 1 | Air Fresheners |
| 2 | Bath Products |
| 3 | Cakes |
| 4 | Candy |
| 11 | Seasonings & Spices |
| 12 | Pasta & Noodles |
| 13 | Fruits & Vegetables |
+----+---------------------+
7 rows in set (0.00 sec)
Просто тупо два запроса через union)
Можно объединять таким образом только одинаковое количество столбцов
Это могут быть две разных таблицы. Заголовки будут от первой таблицы
MariaDB [store]> select * from category where id < 5 union select * from category_has_good where category_id > 1 limit 10;
+----+----------------+
| id | name |
+----+----------------+
| 1 | Air Fresheners |
| 2 | Bath Products |
| 3 | Cakes |
| 4 | Candy |
| 2 | 6 |
| 2 | 8 |
| 2 | 9 |
| 2 | 10 |
| 2 | 13 |
| 2 | 15 |
+----+----------------+
10 rows in set (0.00 sec)
По умолчанию union сделает проверку на уникальность кортежей и избавится от дубликатов
Чтобы получить выборку с дубликатами нужно использовать ключевое слово ALL для оператора union
select ...
union all
select ...;
Такой вывод будет содержать в себе два селекта с дубликатами
full outer join
Полного внешнего соединения в mysql не придусмотрено. Для этого можно использовать две выборки с левым и правым объединением через union
Триггеры и хранимые процедуры
Процедурные расширения позволяют сделать SQL вычислительно полным языком
Хранимые процедуры исполняются сервером БД, то есть процедуры исполняются там же или очень близко к месту расположения данных
Процедуры однократно компилируются. То есть единожды происходит компиляция (с проверкой синтаксиса и пр.) и дальше уже выполняется скомпилированная процедура. Это гораздо быстрее чем последовательное выполнение запросов
Процедуры могут кэшировать данные и пр.
В СУБД есть встроенные функции (например конкатенация или работа с датами). Можно определять пользовательские функции и использовать их как встроенные. Это часть процедурного расширения
Также существуют процедуры реализуемые на языках общего назначения (perl, python, etc)
Это нужно потому что язык SQL не так выразителен как множество других языков
Хранимые процедуры позволяют скрывать структуру данных. Например чтобы не держать в голове сложную схему таблиц и их связей, можно реализовать процедуру которая будет предоставлять интерфей к данным
Также если несколько приложений взаимодействуют с базой, то можно использовать процедуры вместо многократных реализаций методов доступа к данным
Как правило процедуры непереносимы, в другой субд придется реализовывать заново
Для реализации процедуры вероятно придется погружаться в особенности субд
Размазывание бизнес логики как правило не очень круто (имеется ввиду когда в виде процедур реализовано много логики)
Триггер это разновидность хранимой процедуры
Триггеры позволяют обрабатывать определнные события с предметной таблицей (внесение измнений в базу данных). Эти события называются инициирующими операциями (вставка, изменение, удаление)
Триггер может быть вызван до или после операции
Тригеры могут иницировать триггеры (рекурсия -> кончается память -> падает база)
Варианты использования:
- Проверка данных
- Поддержка согласованности
- Журналирование и аудит
- Процедуры не связанные с обработкой данных
Недостатки:
- Непрозрачность
- Сложность отладки
- Производительность
- Глобальность
No Comments