ZooKeeper Overview
ZooKeeper: A Distributed Coordination Service for Distributed Applications
ZooKeeper это распределенный, опенсорсный координирующий сервис для распределенных систем
Он предоставляет простой набор примитивов на основе которых распределенные приложения могут строить свои высокоуровневые сервисы синхронизации
Он создан так чтобы быть простым в использовании и использует модель структурирования данных похожую на файловую систему
Известно что очень сложно сделать правильно координационный сервис. Они подвержены таким проблемам как race-condition и deadlock. Существование ZooKeeper'а мотивировано желанием освободить распределенные приложения от необходимости самостоятельно реализовывать такие сложные подсистемы
Design Goals
ZooKeeper is simple
ZeeKeeper позволяет распределенным процессам согласовываться с другими процессами через общий иерархический неймспейс который организован как обычная файловая система
Неймспейсы хранят регистры с данными, которые называются znode. Это похоже на файлы и директории
В отличие от файловой системы, которая создана чтобы хранить, ZooKeeper хранит данные в памяти, благодаря чему может достигать высокой пропускной способности и низких задержек
ZooKeeper дает высокую производительность, высокую доступность и строго упорядоченный доступ. Высокая производительность позволяет использовать его в больших, распределенных системах. Надежность не позволит ему стать единой точкой отказа. Упорядоченность позволяет имплементировать свои примитивы для синхронизации на клиенте
ZooKeeper is replicated
Будучи распределенным процессом он согласуется. Происходит репликация по всем хостам в "ансамбле"
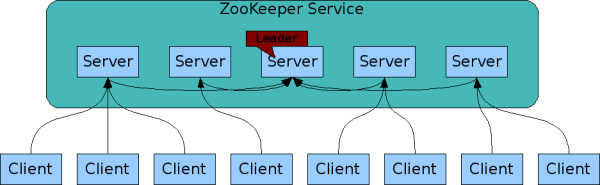
Серверы с ZooKeeper должны знать обо всех остальных. Они поддерживают образ состояния в памяти и ведут лог транзакций и складывают снапшоты на диск. Сервис ZooKeeper будет оставаться доступным пока доступно большинство серверов из ансамбля
Клиент подключается к одному серверу ZooKeeper. Устанавливается TCP подключение через которое передаются зарпосы, ответы, ивенты и heartbeat'ы. Если TCP подключение рвется, то клиент подключается к другому серверу
ZooKeeper is ordered
ZooKeeper помечает каждое изменение данных номером который отражает порядок транзакций. Последующие операции могут использовать этот порядок для построения высокоуровневых абстракций, таких как примитивы синхронизации
ZooKeeper is fast
Он особо быстр при нагрузке на чтение данных. ZooKeeper можно запустить на тысяках машин и его лучший перфоманс будет в условиях когда доминирует чтение к записи в отношении 10:1
Data model and the hierarchical namespace
Неймспейсы которые предоставляет ZooKeeper очень похожи на обычную файловую систему. Имя это последовательность элементов пути разделенных /. Каждая нода в идентифицируется по пути
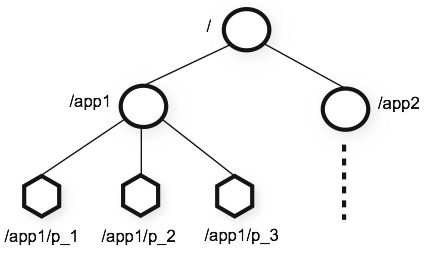
Nodes and ephemeral nodes
В отличие от стандартных файловых систем, каждая нода в неймспейсе может быть ассоциирована с данными так же как и ее дети. Это как если бы в файловой системе файлы могли быть директориями
ZooKeeper был создан чтобы хранить координационные данные: статус, конфигурация, локация информации, итд. Таким образом данные хранимые в каждой ноде - малы (от байта до килобайта). Используется термин znode для описания датанод в ZooKeeper
Znode'ы поддерживают структуры данных с версией данных, изменениями ACL и таймстемпы для обеспечения валидации кэша. При каждом обновлении данных в znode увеличивается и номер версии. Когда клиент получает данные он получает и версию данных
Данные пишутся и читаются атомарно. Чтение достает все байты связанные с выбранной znode, а запись заменяет все байты. Каждая znode имеет ACL в которой описано кто что может делать
Еще есть эфемерные znode, которые существуют пока существует сессия в рамках которой они созданы, когда сессия завершается - znode удаляется
Conditional updates and watches
ZooKeeper имеет концепцию 'watch'. Клиент может установить watch на znode. Этот watch стриггерится и удалится когда znode будет изменен. Когда триггерится watch, клиент получает пакет в котором говорится что znode был изменен. Если подключение между клиентом и сервером сорвалось, то клиент получит локальную нотификацию (через локальную сессию)
New in 3.6.0: клиенты могут устанавливать постоянный, рекурсивный watch на целое дерево znode. Такой watch не удаляется после триггерения
Guarantees
ZooKeeper очень быстрый и простой. Так как его цель быть базой для построения более сложных сервисов, таких как синхронизация, то он предоставляет ряд гарантий:
- Sequential Consistency - Изменения от клиента будут применены в порядке в котором они были присланы
- Atomicity - Изменения либо успешны либо нет. Никаких частичных результатов
- Single System Image - Клиент увидит то же состояние сервиса независимо от того к какому серверу он подключен
- Reliability - Однажды примененное изменение будет хранится пока оно не будет перезаписано
- Timeliness - Видение клиентом системы гарантировано актуально
Simple API
Одна из целей дизайна ZooKeeper'a - предоставлять простой API. В результате он поддерживает только эти несколько операций:
create: creates a node at a location in the treedelete: deletes a nodeexists: tests if a node exists at a locationget data: reads the data from a nodeset data: writes data to a nodeget children: retrieves a list of children of a nodesync: waits for data to be propagated
Implementation
Схема ниже отображает высокоуровневое представление сервиса ZooKeeper
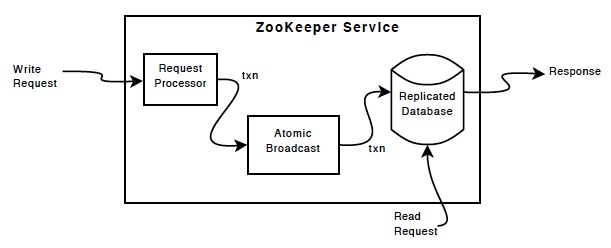
Replicated database это in-memory база данных которая хранит в себе полное дерево данных. Изменения логируются на диск для восстановляемости, и запись сериализуется на диск перед тем как будет применена к данным в памяти
Каждый сервер ZooKeeper'a обслуживает клиентов. Клиенты подключаются исключительно к одному серверу для запросов. Запросы на чтение обрабатываются за счет локальной копии данных на каждом сервере. Запросы на запись обрабатываются через agreement protocol
Все запросы на запись в рамках agreement protocol перенаправляются на единый сервер называемый leader. Остальные серверы называются follower'ами. Они получают предложение на изменение данных от leader'a и соглашаются с ним. Messaging layer сам заботится о замене лидера и о синхронизации фоловеров с лидером
Используется кастомный атомарный протокол взаимодействия. Так как messaging layer атомарный, то ZooKeeper гарантирует что локальные копии данных никогда не расходятся. Когда лидер получается запрос на запись
Когда лидер получает запрос на запись, он вычисляет, в каком состоянии находится система на момент выполнения записи, и преобразует его в транзакцию, которая фиксирует это новое состояние
Uses
API ZooKeeper'a намеренно прост. Благодаря этому ты можешь имплементировать свои примитивы поверх этой базы
Performance, Reliability, The ZooKeeper Project
https://zookeeper.apache.org/doc/current/zookeeperOver.html
Getting Started: Coordinating Distributed Applications with ZooKeeper
Этот документ содержит информацию для быстрого старта с ZooKeeper. Он нацелен в первую очередь на разработчиков желающих попробовать, и содержит простые инструкции по установке одиночного сервера ZooKeeper. Далее будет пара секций про более сложные инсталяции, например запуск реплицируемых деплойментов и оптимизация лога транзакций. В любом случае для инсталяции в проде обратись к ZooKeeper Administrator's Guide
Pre-requisites
Download
Скачать можно здесь - http://zookeeper.apache.org/releases.html
Standalone Operation
Установка ZooKeeper в одиночном режиме очень проста. Сервер содержится в одном JAR-файле, нужно лишь создать конфигурационный файл
Когда ты скачал релиз, распаковал и перешел внутрь, то для старта ZooKeeper'a остается только добавить конфиг. Ниже пример, создай его в conf/zoo.cfg
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
Этот файл может называться как угодно, но чтобы оставаться в рамках этой статьи назови его conf/zoo.cfg
Измени значение dataDir на существующую директорию. Далее значения каждого поля:
tickTime- базовая единица времени используемая ZooKeeper'ом. Он используется для хартбитов и для значения минимального таймаута сессии будет использоться удвоенное значение этого параметраdataDir- локация для сохранения снапшотов in-memory базы данных и логов транзакций (можно задать другое место)clientPort- порт для прослушивания для принятия клиентских подключений
Теперь после создания конфига можно запустить ZooKeeper:
bin/zkServer.sh start
Для логов используется logback, логи будут выводиться в консоль или в файл в зависимости от конфигурации logback
Установить java на ubuntu:
sudo apt install default-jre
Managing ZooKeeper Storage
Для долгоживущих продакш сетапов сторадж должен управляться снаружи (dataDir и логи)
Смотри в секцию maintenance для подробностей
Connecting to ZooKeeper
$ bin/zkCli.sh -server 127.0.0.1:2181
Эта команда запустит cli который позволит делать простые операции над хранилищем
(команда help выведет список доступных команд)
Programming to ZooKeeper
ZooKeeper имеет привязки в Java и C, они функционально эквивалентны
Для C есть два варианта, однопоточный и много-поточный. Они отличаются тем как работает messaging-loop
Доп инфа тут - https://zookeeper.apache.org/doc/current/zookeeperProgrammers.html#ch_programStructureWithExample
Running Replicated ZooKeeper
ZooKeeper в одиночном режиме удобен для оценки, разработки и тестирования. Но в продакшене нужно использовать режим с репликацией. Реплицируемая группа серверов называется кворум, все серверы в кворуме имеют одинаковую конфигурацию
Для работы в режиме репликации требуется минимум три сервера. Строго рекомендуется чтобы серверов в кворуме было нечетное количество. Если у тебя две машины, то ты можешь попасть в ситуацию когда одна из них вышла из строя и машин стало недостаточно для обесчения большинства. Две машины даже менее надежны чем одна, потому что это две отдельные точки отказа
Конфиг похож на предыдущий за исключением пары деталей
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
Новая запись initLimit это таймаут коннекта к лидеру, а запись syncLimit ограничивает отставание от лидера
Для обоих этих таймаутов используется единица времени из опции tickTime
В примере выше initLimit это 5 тиков по 2000 милисекунд - а это 10 секунд
Записи вида server.X это список серверов которые обеспечивают сервис ZooKeeper
Когда сервер стартует, он знает что это за сервер благодаря файлу myid из dataDir (этот файл содержит номер сервера из списка серверов в конфиге (число 1/2/3), файл нужно создать самостоятельно)
Наконец посмотрим на два порта после каждого имени сервера: 2888 и 3888. Узлы используют первый порт для общения друг с другом. Процесс выборов тоже требует TCP подключения, для этого подключения требуется другой порт (это второй порт)
2181 - is the client port. Clients (Kafka brokers) used to communicate with the server.
2888 - is the peer port. This is the port that zookeeper nodes use to talk to each other.
3888 - is the leader port. The port that nodes use to talk to each other when it comes to the leader election.
Other Optimizations
Для снижения задержек рекомендуется выносить директорию с логом транзакций в отдельное место за счет директивы dataLogDir
https://zookeeper.apache.org/doc/current/zookeeperStarted.html
No Comments