Cluster VictoriaMetrics
Фишки
- Может все что может single node версия
- Производительность и расширяемость в ширину
- Поддерживает независимые неймспейсы для данных (aka multi-tenancy)
- Поддерживает репликацию
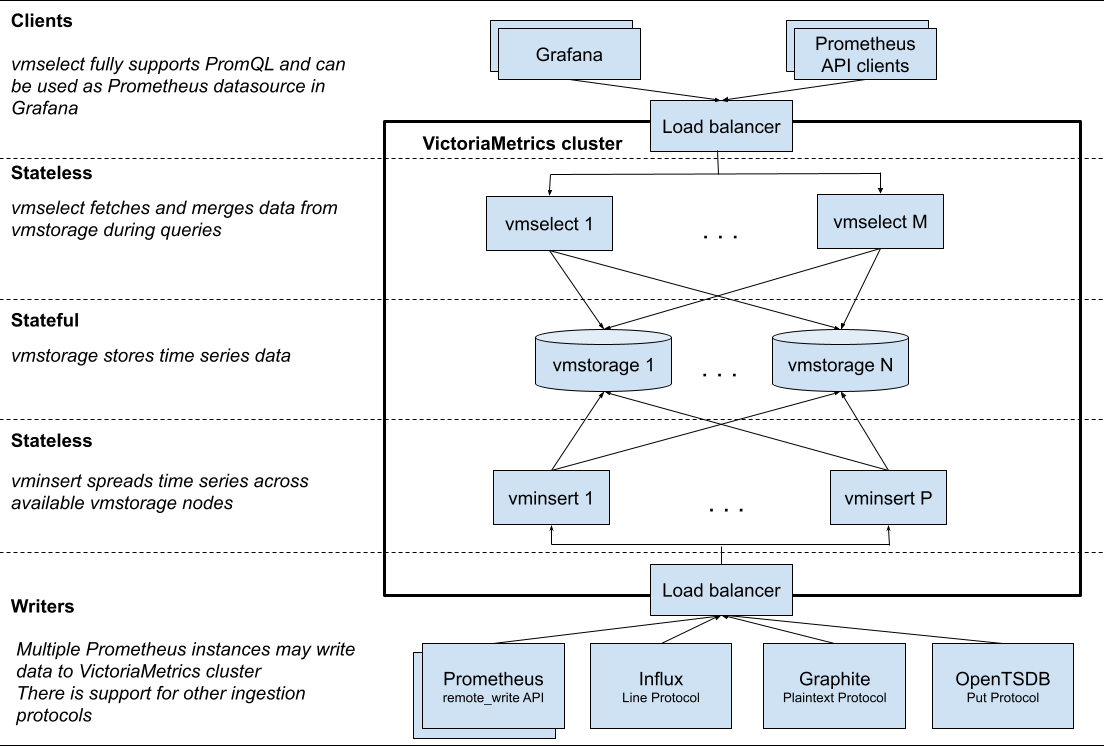
Обзор архитектуры
Кластер состоит из следующих сервисов:
- vmstorage - хранит данные
- vminsert - принимает данные и распределяет их по сторадж-нодам основываясь на хэше от имени метрики и всех ее лейблов
- vmselect - достает данные со стораджей
Каждый сервис может скейлиться независимо от остальных
Стораджи не знают друг о друге и никак друг с другом не коммуницируют, это упрощает авэйлабилити, расширяемость и обслуживаемость
Селекты поддерживают promql и могут быть использованы как prometheus datasource в графане
Мультитенантность
Тенанты определяются с помощью accountID или accountID:projectID, которые находятся внутри запроса
-
accountID/projectIDэто 32 битное целое. Projectid может быть опущен, тогда автоматом будет назначен projectid=0. Дополнительная информация про account или project хранится в отдельной реляционной базе и управляется через vmauth или vmgateway - Тенанты создаются автоматом когда в указанный тенантайди впервые кладуются данные
- Производительность базы не зависит от количества тенантов, она зависит от количества активных метрик во всех тенантах. Метрика считается активной если последний доступ к ней был менее часа назад (если положили или запросили менее часа назад)
- Нельзя сделать один кросстенантный запрос
Cluster setup
Минимальный кластер это
- 1 storage с флагами
-retentionPeriodи-storageDataPath - 1 insert с флагом
-storageNode=<vmstorage_host> - 1 select с флагом
-storageNode=<vmstorage_host>
Соответственно вышеуказанные флаги являются обязательными
vmauth или какой-либо http-loadbalancer ставится перед vmselect/vminsert нодами
Настроить балансер можно основываясь на url-format
Переменные окружения
Каждый флаг может быть задан через перменные окружения
- Должен быть установлен флаг
-envflag.enable - Каждая точка в имени флага должна быть заменена на подчеркивание (был флаг
-insert.maxQueueDuration <duration>стала переменнаяinsert_maxQueueDuration=<duration>) - Повторяющиеся флаги нужно объединить в одну переменную (было два флага
-storageNode <nodeA> -storageNode <nodeB>стала одна переменнаяstorageNode=<nodeA>,<nodeB>) - С помощью флага
-envflag.prefixможно задать префикс для переменных окружения
Monitoring
Каждый компонент отдает метрики в prometheus-совместимом формате на эндпоинте /metrics
Есть официальный и неофициальный дашборды для графаны
Алерты рекомендуется брать из этого конфига
Readonly mode
Стораджи автоматом переходят в ридонли режим когда в -storageDataPath остается мало места, а именно когда его меньше чем указано в -storage.minFreeDiskSpaceBytes
Инсерты в таком случае перестают слать данные в этот сторадж и шлют их в оставшиеся
URL format
Урл для вставки выглядит так - http://<vminsert>:8480/insert/<accountID>/<suffix>, где:
-
<accountID>- 32-ух битное целое обозначающее неймспей (aka тенант). Возможно также использовать вариант -accountID:projectID, где projectID тоже просто число. Если projectID нет, то он равен 0 -
<suffix>- может иметь следующие значения:-
datadog/api/v1/series- не интересно -
influx/writeиinflux/api/v2/write- не интересно -
opentsdb/api/put- не интересно -
prometheusиprometheus/api/v1/write- для вставки данных через Prometheus remote write API -
prometheus/api/v1/import- для импорта данных полученных через/select/<accountID>/prometheus/api/v1/exportу vmselect'а -
prometheus/api/v1/import/native- почти то же самое что выше -
prometheus/api/v1/import/csv- почти то же самое что выше -
prometheus/api/v1/import/prometheus- для импорта метрик в формате OpenMetrics
-
Урл для запросов выглядит так - http://<vmselect>:8481/select/<accountID>/prometheus/<suffix>, где:
-
<accountID>- описано выше -
<suffix>- может иметь следующие значения:-
api/v1/query- PromQL instant query -
api/v1/query_range- PromQL range query -
api/v1/series- series query -
api/v1/labels- возвращает лейблы -
api/v1/label/<label_name>/values- возвращает значения по переданному<label_name> -
federate- возвращает зафедерейтеные метрики -
api/v1/export- экспортит данные в JSON -
api/v1/export/native- экспортит данные в бинарном формате виктории. Потом эти данные могут быть импортированы в другую викторию черезapi/v1/import/native -
api/v1/export/csv- экспорт в CSV -
api/v1/series/count- возвращает общее количество time series -
api/v1/status/tsdb- статистика по TSDB -
api/v1/status/active_queries- текущие запросы -
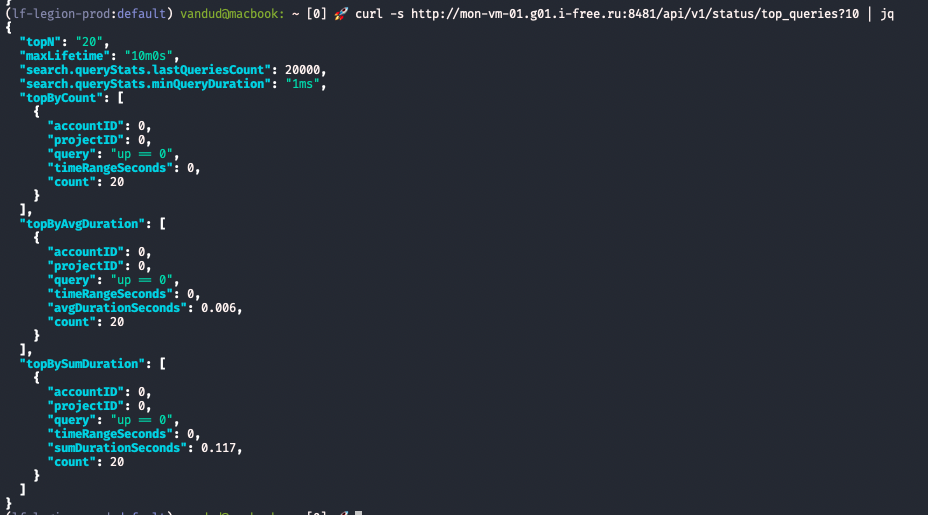
api/v1/status/top_queries- частые и долгие запросы
-
Урл для Graphite Metrics API - http://<vmselect>:8481/select/<accountID>/graphite/<suffix>, где все не интересно:
-
<accountID>- описано выше -
<suffix>- может иметь следующие значения:-
render- не интересно -
metrics/find- не интересно -
metrics/expand- не интересно -
metrics/index.json- не интересно -
tags/tagSeries- не интересно -
tags/tagMultiSeries- не интересно -
tags- не интересно -
tags/<tag_name>- не интересно -
tags/findSeries- не интересно -
tags/autoComplete/tags- не интересно -
tags/autoComplete/values- не интересно -
tags/delSeries- не интересно
-
Урл с простым Web UI - http://<vmselect>:8481/select/<accountID>/vmui/
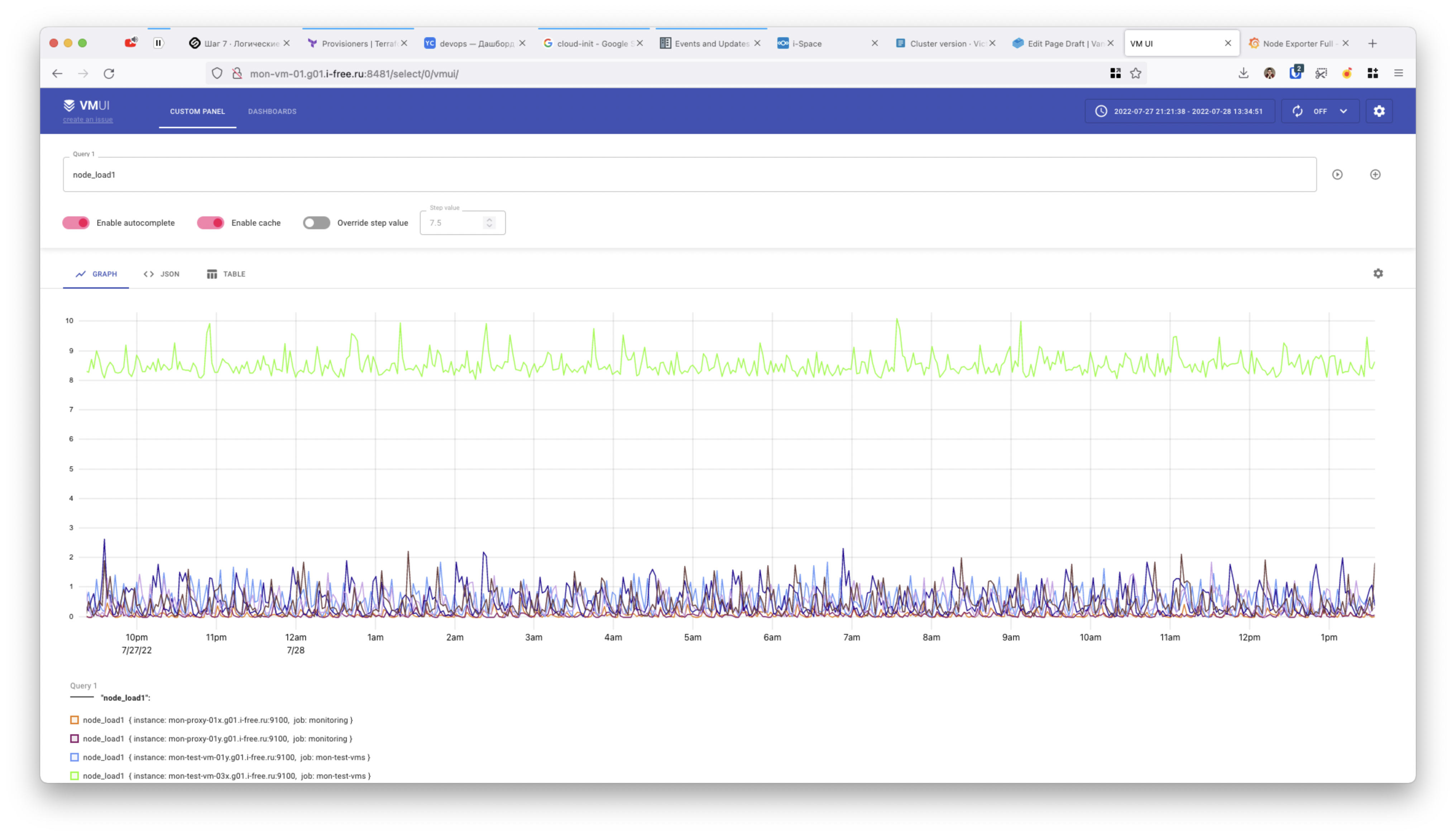
Урл со статистикой по запросам сквозь все неймспейсы - http://<vmselect>:8481/api/v1/status/top_queries
Урл для удаления тайм серий - http://<vmselect>:8481/delete/<accountID>/prometheus/api/v1/admin/tsdb/delete_series?match[]=<timeseries_selector_for_delete>. Это нельзя делать на регулярной основе, чисто чтобы исправлять ошибки когда заинджестил что-то не то
Пример удаления
vandud@macbook: ~ [0] ? curl -s 'http://mon-vm-01.g01.i-free.ru:8481/select/1/prometheus/api/v1/query_range?query=node_load1\{instance="mon-vm-03.g01.i-free.ru:9100"\}&start=1659557812.652&end=1659559128.166' | jq
{
"status": "success",
"isPartial": false,
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "node_load1",
"instance": "mon-vm-03.g01.i-free.ru:9100",
"job": "monitoring"
},
"values": [
[
1659557812.652,
"0.06"
],
[
1659558112.652,
"0.04"
],
[
1659558412.652,
"0.2"
],
[
1659558712.652,
"0.01"
],
[
1659559012.652,
"0.06"
]
]
}
]
}
}
vandud@macbook: ~ [0] ? curl -s 'http://mon-vm-01.g01.i-free.ru:8481/delete/1/prometheus/api/v1/admin/tsdb/delete_series?match[]=node_load1\{instance="mon-vm-03.g01.i-free.ru:9100"\}'
vandud@macbook: ~ [0] ? curl -s 'http://mon-vm-01.g01.i-free.ru:8481/select/1/prometheus/api/v1/query_range?query=node_load1\{instance="mon-vm-03.g01.i-free.ru:9100"\}&start=1659557812.652&end=1659559128.166' | jq
{
"status": "success",
"isPartial": false,
"data": {
"resultType": "matrix",
"result": []
}
}
vmstorage предоставляет следующие HTTP эндпоинты на 8482 порту:
-
/internal/force_merge- запускает forced compactions на выбранной vmstorage ноде -
/snapshot/create- делает снапшот, который кладется в<storageDataPath>/snapshots, снапшоты можно бэкапить -
/snapshot/list- список снапшотов -
/snapshot/delete?snapshot=<id>- удалить снапшот -
/snapshot/delete_all- удалить все снапшоты
Cluster resizing and scalability
Производительность и вместительность кластера можно увеличивать двумя способами:
- добавляя ресурсы существующим нодам (вертикальное масштабирование)
- увеличивая количество нод (горизонтальное масштабирование)
Подробнее тут https://docs.victoriametrics.com/Cluster-VictoriaMetrics.html#cluster-resizing-and-scalability
Updating / reconfiguring cluster nodes
vmselect, vminsert и vmstorage можно апдейтнуть плавно. Для этого надо засылать им SIGINT после замены бинаря (это же касает обновления конфига)
Cluster availability
- HTTP балансер должен прекращать слать трафик на неисправные vminsert/vmselect
- Кластер остается доступным пока хотя бы один сторадж жив
- vminsert'ы рероутят трафик с нездоровых стораджей на здоровые
- vmselect'ы продолжают выдавать частичные ответы пока жив хотя бы один сторадж. Если консистентность важнее доступности то можно запретить частичные ответы через флаг
-search.denyPartialResponseу vmselect'a (или можно засылать аргументdeny_partial_response=1в запросе)
vmselect не поддерживает частичные ответы на эндпоинтах которые отдают сырые данные (например /api/v1/export*) потому что обычно ожидается что там будут полные данные
Для пущей надежности можно настроить data replication
Capacity planning
VictoriaMetrics использует меньше ресурсов чем конкурирующие решения (Prometheus, Cortex, etc)
Кол-во потребляемых ресурсов зависит от от профиля нагрузки (сколько таймсерий, какой churn rate, какого типа запросы прилетают, количество запросов, etc)
Рекомендуется строить тестовый кластер на продовых нагрузках и отлаживать это все по ходу дела (все сервисы кластера предоставляют метрики)
Количество диска для указанного -retentionPeriod так же можно понять по тестовому кластеру (например если на тестовом стенде за день набралось 10Gb данных, то если мы захотим хранить 100 дней то 10 надо умножить на 100, получится 1Тб диска)
Рекомендуется оставить свободными 50% памяти и процессора чтобы кластер мог безопасно переживать всплески нагрузки
Так же рекомендуется иметь в запасе 20% диска
Советы:
- репликация увеличивает кол-во необходимых ресурсов для кластера потому что vminsert'у приходится складывать один и тот же сэмпл в N стораджей, а vmselect'у приходится постоянно дедуплицировать данные со стораджей (для увеличения производительности с сохранением надежности можно переложить реплицирование на уровень ниже (например делать реплицирование на уровне системы хранения))
- большой кластер из мелких нод лучше чем маленький кластер из жирных нод. Если мы теряем 1 ноду из 10 нодового кластера то нагрузка на оставшиеся повысится всего на 11%, если мы теряем 1 ноду из 3 нодового кластера то нагрузка на оставшиеся вырастет на 50%, это нужно учитывать потому что оставшиеся ноды могут не выдержать повышения нагрузки и кластер может упасть целиком
- чтобы увеличить вместимость активных таймсерий нужно увеличивать ноды вверх или кластер вширь
- медленность запросов может быть решена увеличением cpu на vmselect'ах
- если нужно обрабатывать запросы с высокой скоростью то можно увеличить количество vmselect'ов
- по умолчания vminsert сжимает данные перед отправкой в сторадж для уменьшения нагрузки на сеть, в определенных случаях выгоднее выключить сжатие с помощью флага
-rpc.disableCompression(тогда cpu на vminsert'ах будет потребляться меньше) - аналогично сжимает данные vmstorage перед отправкой их на vmselect и аналогично можно снизить потребление cpu на vmstorage с помощью флага
-rpc.disableCompression
Resource usage limits
По умолчания компоненты кластера настроены на оптимальную работу при типичных нагрузках. В некоторых случаях может потребоваться ограничение потребления некоторых ресурсов. Далее будут рассмотрены флаги для ограничения потребления ресурсов:
-
-memory.allowedPercentи-search.allowedBytesограничивают потребление памяти под различные внутренние кэши, доступны во всех трех компонентах кластера (vminsert, vmstorage, vmselect), но они не ограничивают дополнительное потребление памяти для выполнения запросов -
-search.maxUniqueTimeseriesна vmselect'е ограничивает количество уникальных таймсерий которые могут быть найдены и обработаны в рамках одного запроса. С vmselect'а этот параметр проксируется на vmstorage -
-search.maxQueryDurationна vmselect'е ограничивает длительность выполнения одного запроса, когда запрос выполняется дольше то он завершается и это позволяет экономить cpu и memory при выполнении неожиданно больших и сложных запросов -
-search.maxConcurrentRequestsна vmselect'е ограничивает количество параллельно обрабатываемых запросов на одной vmselect-ноде, большое количество параллельно обрабатываемых запросов увеличивает потребление памяти на vmselect'ах и vmstorage. Например если один запрос требует 100Mb дополнительной памяти, то 100 параллельных таких запросов потребуют 10Gb дополнительной памяти. Лучше ограничивать параллельность, запросы сверх лимита встают в очередь и ждут когда дойдет очередь до их выполнения, у vmselect'ов есть флаг-search.maxQueueDurationкоторый ограничивает длительность ожидания запроса в очереди -
-search.maxSamplesPerSeriesна vmselect'ах ограничивает количество семплов на таймсерию которые может обработать запрос. vmselect последовательно обрабатывает каждый сэмпл из найденной таймсерии на протяжении запроса (таймсерия распаковывается и кладется в память, после чего для распаковынных данных применяется функция из запроса). Этот флаг позволяет ограничить потребление памяти на vmselect'ах -
-search.maxSamplesPerQueryна vmselect'ах ограничивает кол-во сэмплов на весь запрос, позволяет ограничить потребление cpu -
-search.maxSeriesна vmselect'ах ограничивает количество таймсерий которые будут доступны на эндпоинте/api/v1/series(он часто используется графаной для auto-completion метрик), запросы на этот эндпоинт могут отбирать много cpu у vmstorage и vmselect когда в хранилище много метрик или когда high churn rate (затестил, работает так что если на запрос должно вернуть больше айтемов чем указано в лимите, то запрос фейлится) -
-search.maxTagKeysна vmstorage ограничивает кол-во айтемов на эндпоинте/api/v1/labels-search.maxTagValuesна vmstorage ограничивает кол-во айтемов на эндпоинте/api/v1/label/.../values(эти эндпоинты часто используются графаной как и в примере выше) Например вот такие значения-search.maxTagKeys 10 -search.maxTagValues 20приводят к вот такому результату? curl -s http://mon-vm-02.g01.i-free.ru:8481/select/0/prometheus/api/v1/labels | jq { "status": "success", "isPartial": false, "data": [ "__name__", "address", "alertgroup", "alertname", "alertstate", "bios_date", "bios_vendor", "bios_version", "branch", "broadcast" ] } ? curl -s http://mon-vm-02.g01.i-free.ru:8481/select/0/prometheus/api/v1/label/address/values | jq { "status": "success", "isPartial": false, "data": [ "00:00:00:00:00:00", "02:42:12:7a:d4:c2", "02:42:2b:18:51:ef", "02:42:2d:55:16:71", "02:42:3b:88:ee:ef", "02:42:44:fd:51:8c", "02:42:49:06:bb:d3", "02:42:72:54:87:57", "02:42:83:01:2e:6c", "02:42:93:29:1b:95", "02:42:9d:9d:4b:10", "02:42:af:5c:44:16", "02:42:df:bf:b1:58", "0e:c2:e6:fb:3c:e7", "2e:c8:78:38:67:9a", "3a:48:37:8b:2d:74", "42:73:3a:c9:e0:8c", "52:54:00:25:d1:60", "52:54:00:27:dd:62", "52:54:00:33:15:55" ] } -
-storage.maxDailySeriesи-storage.maxHourlySeriesна vmstorage ограничивают кол-во таймсерий которые могут быть добавлены в хранилище за 24 часа или за час (это позволяет бороться с high churn rate
Multi-level cluster setup
Одни vmselect'ы могут обращаться к другим vmselect'ам если они запущены с флагом -clusternativeListenAddr, то же самое с vminsert'ом
Replication and data safety
По умолчанию victoriametrics полагается на надежность хранилища которое выбрано для хранения данных и прописано в -storageDataPath, но так же она поддерживает репликацию на уровне приложения
С помощью ключа -replicationFactor=N на vminsert'ах можно задать количество хранимых копий сэмплов (на разных стораджах). Это гарантирует что все сохраненные данные будут оставаться доступными для запросов если вплоть до N-1 vmstorage'й будет недоступно (ReplicationFactor - 1 = UnavailableNodes)
Кластер должен содержать как минимум 2*N-1 стораджей, где N - фактор репликации
Кластер хранит таймстемпы с миллисекундным разрешением, поэтому флаг -dedup.minScrapeInterval=1ms может быть добавлен на vmselect'ы для дедуплицирования сэмплов получаемых со стораджей
Но надо помнить что реплика это не бэкап, поэтому не забывай про бэкапы
Репликация увеличивает потребление ресурсов, потому что vminsert'у нужно клать две копии в два разных стораджа, а vmselect'у нужно дедуплицировать полученные данные
Для сокращения этих издержек можно передать репликацию на уровень ниже (на систему хранения предоставляющую диск для ВМ)
Deduplication
VictoriaMetrics выбирает сэмпл с наибольшим таймстемпом из сэмплов попадающих в интервал заданный в -dedup.minScrapeInterval. То есть из таймсерии на каждый такой интервал выпадает один сэмпл (если спорный момент когда одинаковый таймстемп у двух сэмплов то выбирается случайный)
Рекомендуется задавать -dedup.minScrapeInterval равным scrape_interval и scrape_interval рекомендуется иметь одинаковым на всех таргетах
Флаг -dedup.minScrapeInterval должен быть проставлен и на vmselect'ах и на vmstorage'ах потому что vmselect пытается лить одну метрику в один сторадж (в идеальных условиях все сэмплы определенной таймсерии будут лежать на одном сторадже), но это поведение может нарушиться если мы будем добавлять/убирать стораджи, если какой-то сторадж будет временно недоступен (зарестартится или произойдет какая-то авария) или на нужном сторадже кончится место, тогда vminsert выберет другой сторадж для этой метрики и часть сэмплов будет на одной ноде, часть на другой
Backups
Рекомендуется периодически делать бэкапы из снапшотов чтобы защититься от пользовательских ошибок таких как случайное удаление данных
Для создания бэкапа:
- Создай снапшот через API
root@mon-vm-02:~# curl -s http://localhost:8482/snapshot/create | jq { "status": "ok", "snapshot": "20220821113230-170D3C49F5660E08" } - Преврати снапшот в бэкап с помощью утилиты vmbackup
Получается бэкап storageDataPathroot@mon-vm-02:~# ./vmbackup-prod -storageDataPath /var/lib/vmstorage-data/ -snapshotName 20220821113230-170D3C49F5660E08 -dst fs:///tmp/test-vm-backuproot@mon-vm-02:~# du -hs /tmp/test-vm-backup/ 67M /tmp/test-vm-backup/ root@mon-vm-02:~# du -hs /var/lib/vmstorage-data/ 68M /var/lib/vmstorage-data/ - Удали снапшот
root@mon-vm-02:~# ls /var/lib/vmstorage-data/snapshots/ 20220821113215-170D3C49F5660E07 root@mon-vm-02:~# curl -s http://localhost:8482/snapshot/delete?snapshot=20220821113215-170D3C49F5660E07 | jq { "status": "ok" } root@mon-vm-02:~# ls /var/lib/vmstorage-data/snapshots/ root@mon-vm-02:~#
Все три пункта можно сделать одной командой
# ./vmbackup-prod -storageDataPath /var/lib/vmstorage-data/ -snapshot.createURL http://localhost:8482/snapshot/create -dst fs:///tmp/test-vm-backup2
Процесс бэкапирования не влияет на производительность кластера, поэтому бэкапы можно делать в любое удобное время
Чтобы восстановить из бэкапа нужно:
- Остановить сторадж
- Восстановить
vmrestore-prod -src fs:///tmp/test-vm-backup -storageDataPath /var/lib/vmstorage-data/ - Запустить сторадж
Profiling
Все компоненты кластера предоставляют хендлеры для профайлинга
-
/debug/pprof/heap- memory -
/debug/pprof/profile- cpu
root@mon-vm-02:~# wget http://localhost:8480/debug/pprof/profile
--2022-08-21 16:02:16-- http://localhost:8480/debug/pprof/profile
Resolving localhost (localhost)... ::1, 127.0.0.1
Connecting to localhost (localhost)|::1|:8480... failed: Connection refused.
Connecting to localhost (localhost)|127.0.0.1|:8480... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [application/octet-stream]
Saving to: ‘profile’
profile [ <=> ] 3.83K --.-KB/s in 0s
2022-08-21 16:02:46 (24.4 MB/s) - ‘profile’ saved [3919]
Грузится достаточно долго, этого пугаться не стоит
Далее полученный файл формата pprof можно как-то анализировать
Например:
root@mon-vm-02:~# go tool pprof -http=172.27.247.182:8080 profile # profile это имя файла который мы получили выше
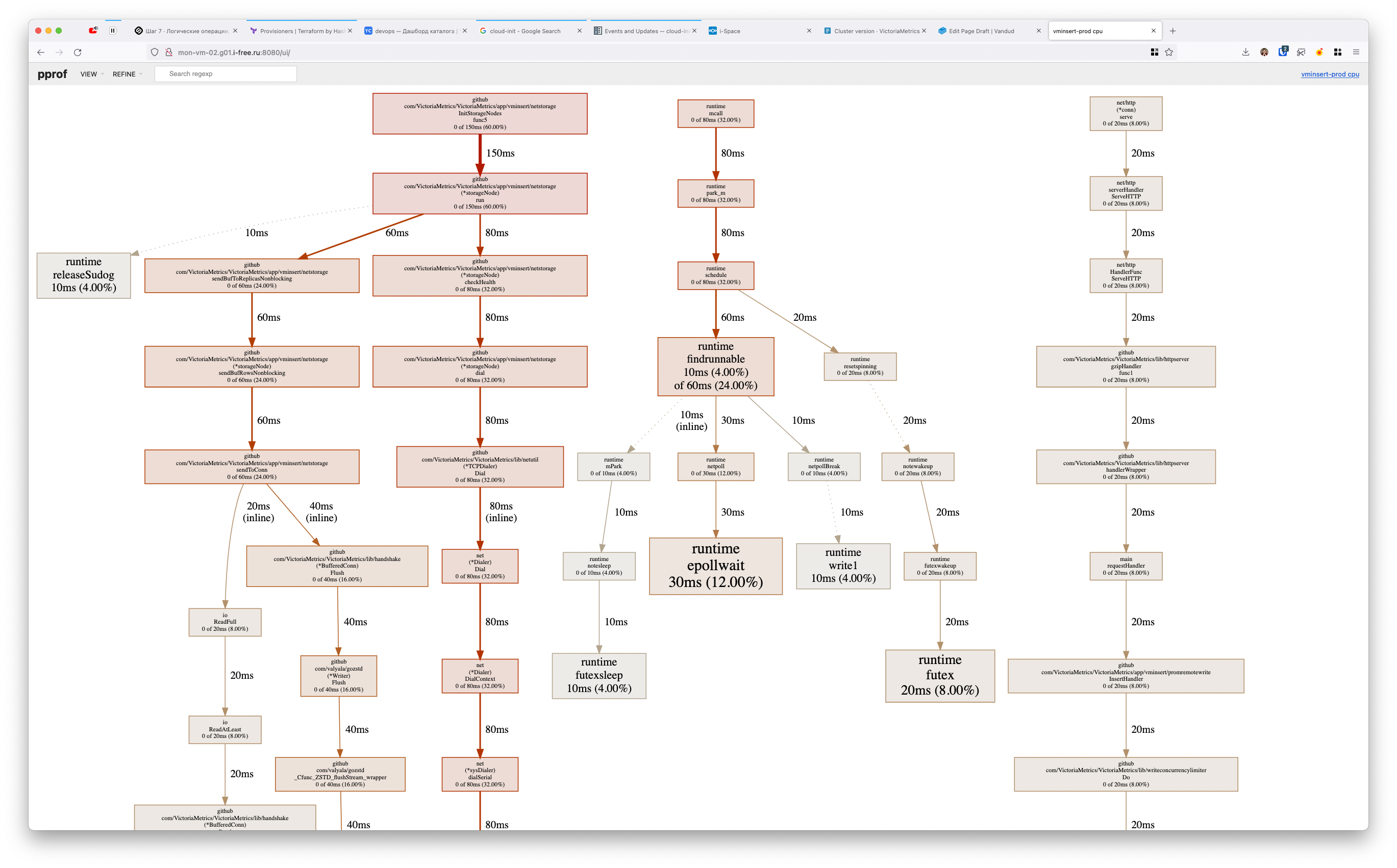
vmalert
vmselect'у можно указать флаг -vmalert.proxyURL и тогда он сможет проксировать некоторые запросы на vmalert
Это нужно для Grafana Alerting UI и можно увидеть интрерфейс vmalert'a через vmselect
Описание доступных флагов у сервисов можно увидеть в хелпе по сервису
No Comments