vmagent
vmagent это маленький но мощный агент который поможет тебе собирать метрики из разных источников и сохранять их в VictriaMetrics или каком-то другом Prometheus-compatible хранилище с поддержкой Prometheus remote_write протокола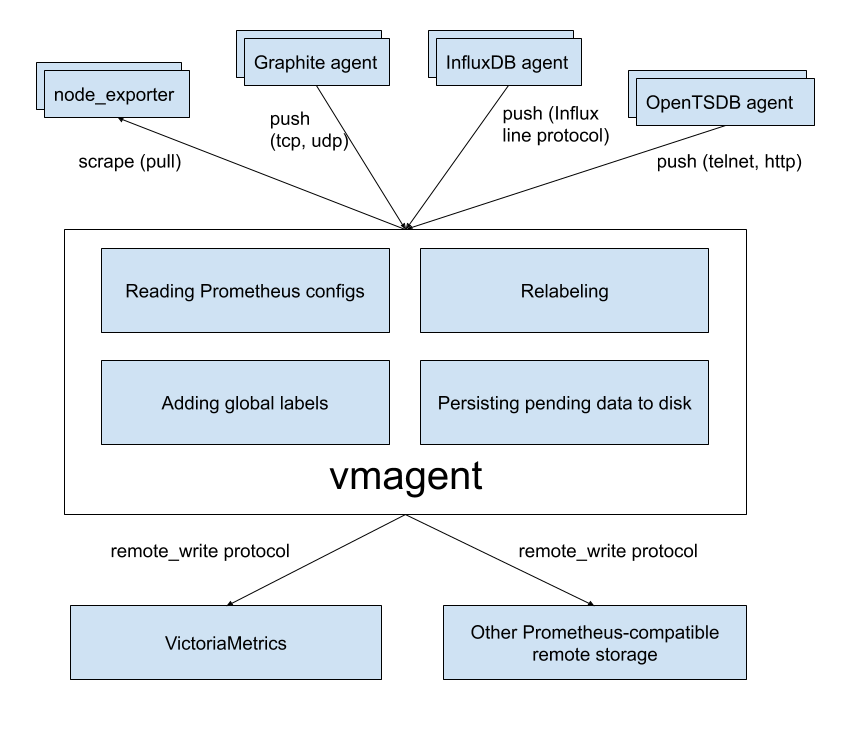
Motivation
vmagent появился потому что пока существовало роскошное хранилище метрик victoriametrics, пользователям также был необходим производительный и не требовательный к ресурсам сборщик метрик который бы складывал метрики в victoriametrics (вместо прожорливого prometheus'а)
Features
- может быть использовать как прямая замена прому для скрейпинга экспортеров
- может читать данные из кафки
- может писать данные в кафку
- может добавлять, удалять и изменять лейблы (relabeling), умеет фильтровать данные перед отправкой в сторадж
- умеет принимать данные через все протоколы поглощения которые поддерживает victoriametrics
- умеет реплицировать собранные метрики одновременно в несколько систем хранения
- нормально работает в условиях плохой связи с удаленным хранилищем. Если нет связи с хранилищем то он буфферизирует собранные данные в буффере указанном в
-remoteWrite.tmpDataPath. Как только связь с хранилищем будет восстановлена, тоvmagentсразу же зашлет все забуфферизированные данные туда. Максимальный размер буффера ограничивается параметром-remoteWrite.maxDiskUsagePerURL - по сравнения с prometheus использует меньше memory, cpu, disk io и network bandwidth
- скрейпинг таргетов может быть размазан на несколько агентов
- эффективно скрейпит жирные таргеты с миллионами таймсерий (например
/federateу прома) - позволяет справляться с high cardinality и high churn rate проблемами через различные ограничения
- может загружать scrape config'и из множества файлов
Quick Start
Скачай подходящий vmutils-* отсюда https://github.com/VictoriaMetrics/VictoriaMetrics/releases и вытащи оттуда бинарь vmagent'a
Базово запустить можно так
./vmagent-prod -remoteWrite.url http://localhost:8480/insert/0/prometheus/api/v1/write -promscrape.config /etc/victoriametrics/vmagent/config.yml
-
-promscrape.config- указываем путь до конфига (vmagent может обработать не все секции prometheus.yml, поэтому можно либо удалить из конфига нерабочие секции, либо добавить флаг-promscrape.config.strictParse=falseчтобы он их игнорил) -
-remoteWrite.urlпуть до хралища
Если скрейпить не надо, то можно запустить вообще с одной опцией
./vmagent-prod -remoteWrite.url http://localhost:8480/insert/0/prometheus/api/v1/write
Тогда агент сможет инджестить в себя пушинговые протоклы и пересылать данные дальше в указанное хранилище
How to push data to vmagent
vmagent поддерживает те же push-based протоколы что и VictoriaMetrics
- DataDog "submit metrics" API
- InfluxDB line protocol via
http://<vmagent>:8429/write - Graphite plaintext protocol if
-graphiteListenAddrcommand-line flag is set - OpenTSDB telnet and http protocols if
-opentsdbListenAddrcommand-line flag is set - Prometheus remote write protocol via
http://<vmagent>:8429/api/v1/write - JSON lines import protocol via
http://<vmagent>:8429/api/v1/import - Native data import protocol via
http://<vmagent>:8429/api/v1/import/native - Prometheus exposition format via
http://<vmagent>:8429/api/v1/import/prometheus - Arbitrary CSV data via
http://<vmagent>:8429/api/v1/import/csv
Configuration update
чтобы vmagent смог перечитать cli-флаги он должен быть рестартанут
vmagent имеет несколько способов перезагрузить конфиги из -promscrape.config, -remoteWrite.relabelConfig и -remoteWrite.urlRelabelConfig:
- можно отправить
SIGHUPkill -SIGHUP `pidof vmagent` - можно отправить запрос на
/http://vmagent:8429/-/reloadэндпоинт
Есть флаг -promscrape.configCheckInterval который позволяет указать vmagent'у что нужно периодически проверять не изменился ли конфиг и подгружать если изменился
Multitenancy
По умолчанию vmagent собирает данные без каких-либо tennant id и просто отправляет их в -remoteWrite.url
Подержка мультитенантности включается когда проставлен флаг -remoteWrite.multitenantURL
Этим флагом задается адрес vmselect'а, куда vmagent будет засылать метрики полученные через push-протокол или собранные с таргетов из конфига
API для пушинга доступен у агента на http://vmagent:8429/insert/<accountID>/..., полученные данные он перенаправит в <-remoteWrite.multitenantURL>/insert/<accountID>/prometheus/api/v1/write
Флаг -remoteWrite.multitenantURL может быть указан несколько раз, тогда агент зареплицирует данные во все указанные remoteWrite хранилища
Чтобы агент скрейпил таргеты и клал собранные данные у нужные неймспейсы нужно чтобы у таргетов был лейбл __tenant_id__ в котором должен быть указан tenantID. Значение этого лейбла будет подставляться в <-remoteWrite.multitnenatURL>/insert/<__tenant_id__>/prometheus/api/v1/write и метрики будут попадать в нужный namespace
Пример
Вот такой конфиг:
---
global:
scrape_interval: 1s
scrape_configs:
- job_name: monitoring
static_configs:
- targets:
- mon-vm-01.g01.i-free.ru:9100
labels:
__tenant_id__: 1
- job_name: mon-test-vms
static_configs:
- targets:
- mon-vm-02.g01.i-free.ru:9100
labels:
__tenant_id__: 2
Вот такая команда запуска:
vmagent-prod -promscrape.config /etc/victoriametrics/vmagent/config.yml -remoteWrite.multitenantURL http://localhost:8480
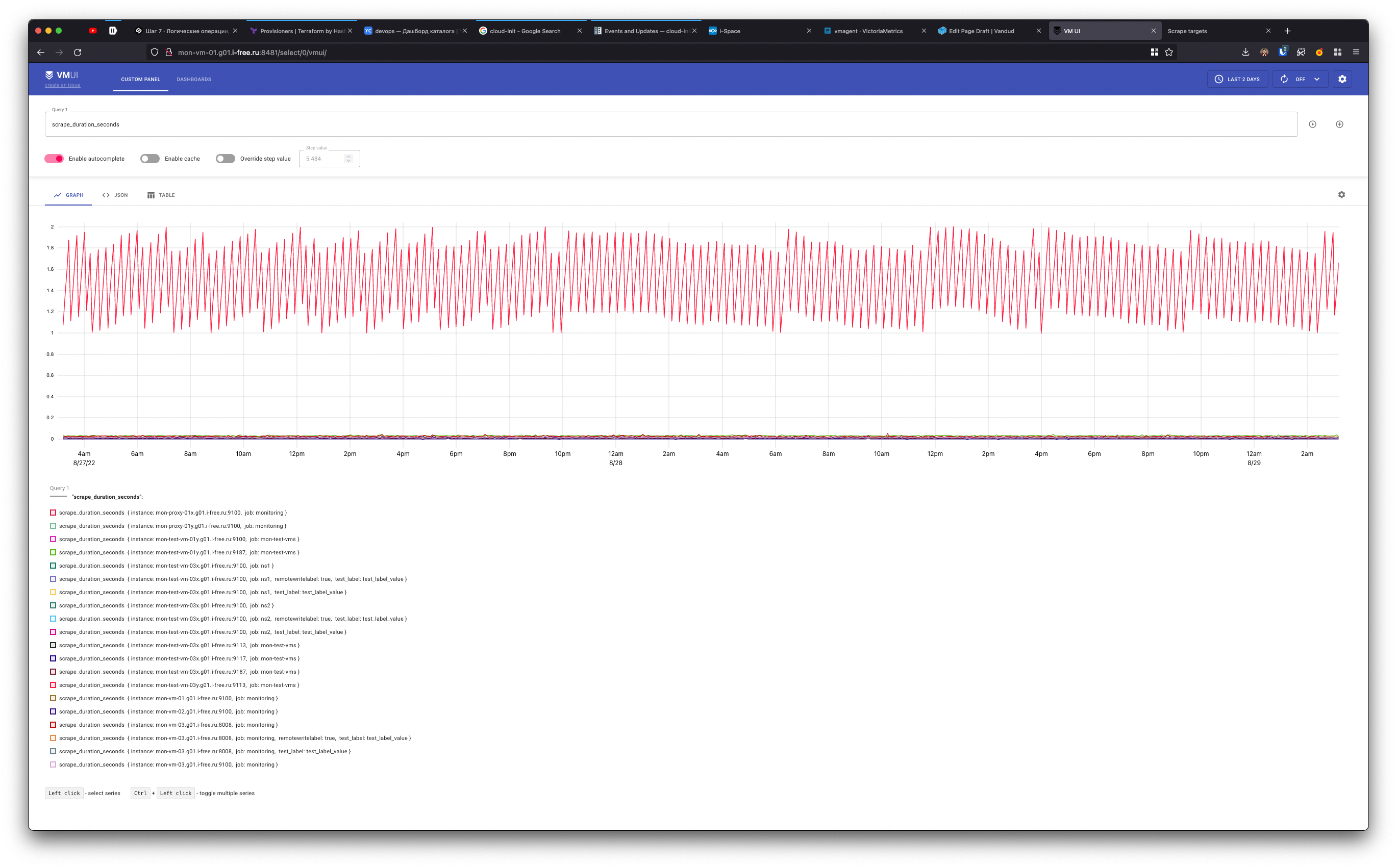
Получаем в каждом NS метрики по своему хосту:
vandud@macbook: ~ [0] ? curl -s http://mon-vm-03.g01.i-free.ru:8481/select/1/prometheus/api/v1/series?match[]=node_load1 | jq
{
"status": "success",
"isPartial": false,
"data": [
{
"__name__": "node_load1",
"job": "monitoring",
"instance": "mon-vm-01.g01.i-free.ru:9100"
}
]
}
vandud@macbook: ~ [0] ? curl -s http://mon-vm-03.g01.i-free.ru:8481/select/2/prometheus/api/v1/series?match[]=node_load1 | jq
{
"status": "success",
"isPartial": false,
"data": [
{
"__name__": "node_load1",
"job": "mon-test-vms",
"instance": "mon-vm-02.g01.i-free.ru:9100"
}
]
}
Если лейбла с tenantID нет, то данные кладутся в 0 неймспейс
How to collect metrics in Prometheus format
Файл из -promscrape.config читается не полностью, некоторые секции из него игнорируются
vmagent понимает только global и scrape_configs секции, а остальные игнорирует
Можно либо убрать лишние секции из конфига, либо добавить флаг -promscrape.config.strictParse=false который заставит vmagent'a их игнорировать
Пример запуска с невалидным конфигом
root@mon-vm-02:~# ./vmagent-prod -promscrape.config /etc/victoriametrics/vmagent/config.yml -remoteWrite.multitenantURL http://localhost:8480
2022-08-23T12:41:35.988Z info VictoriaMetrics/lib/logger/flag.go:12 build version: vmagent-20220808-173305-tags-v1.80.0-0-gad00f4aaa
2022-08-23T12:41:35.988Z info VictoriaMetrics/lib/logger/flag.go:13 command-line flags
2022-08-23T12:41:35.988Z info VictoriaMetrics/lib/logger/flag.go:20 -promscrape.config="/etc/victoriametrics/vmagent/config.yml"
2022-08-23T12:41:35.988Z info VictoriaMetrics/lib/logger/flag.go:20 -remoteWrite.multitenantURL="http://localhost:8480"
2022-08-23T12:41:35.988Z info VictoriaMetrics/app/vmagent/main.go:103 starting vmagent at ":8429"...
2022-08-23T12:41:35.988Z info VictoriaMetrics/app/vmagent/main.go:128 started vmagent in 0.000 seconds
2022-08-23T12:41:35.988Z info VictoriaMetrics/lib/httpserver/httpserver.go:94 starting http server at http://127.0.0.1:8429/
2022-08-23T12:41:35.988Z info VictoriaMetrics/lib/httpserver/httpserver.go:95 pprof handlers are exposed at http://127.0.0.1:8429/debug/pprof/
2022-08-23T12:41:35.989Z info VictoriaMetrics/lib/promscrape/scraper.go:106 reading Prometheus configs from "/etc/victoriametrics/vmagent/config.yml"
2022-08-23T12:41:35.991Z fatal VictoriaMetrics/lib/promscrape/scraper.go:109 cannot read "/etc/victoriametrics/vmagent/config.yml": cannot parse Prometheus config from "/etc/victoriametrics/vmagent/config.yml": cannot unmarshal data: yaml: unmarshal errors:
line 17: field storage not found in type promscrape.Config; pass -promscrape.config.strictParse=false command-line flag for ignoring unknown fields in yaml config
Пример запуска с ключом -promscrape.config.strictParse=false
root@mon-vm-02:~# ./vmagent-prod -promscrape.config /etc/victoriametrics/vmagent/config.yml -remoteWrite.multitenantURL http://localhost:8480 -promscrape.config.strictParse=false [9/973]
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/logger/flag.go:12 build version: vmagent-20220808-173305-tags-v1.80.0-0-gad00f4aaa
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/logger/flag.go:13 command-line flags
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/logger/flag.go:20 -promscrape.config="/etc/victoriametrics/vmagent/config.yml"
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/logger/flag.go:20 -promscrape.config.strictParse="false"
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/logger/flag.go:20 -remoteWrite.multitenantURL="http://localhost:8480"
2022-08-23T12:42:23.991Z info VictoriaMetrics/app/vmagent/main.go:103 starting vmagent at ":8429"...
2022-08-23T12:42:23.991Z info VictoriaMetrics/app/vmagent/main.go:128 started vmagent in 0.000 seconds
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/httpserver/httpserver.go:94 starting http server at http://127.0.0.1:8429/
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/httpserver/httpserver.go:95 pprof handlers are exposed at http://127.0.0.1:8429/debug/pprof/
2022-08-23T12:42:23.991Z info VictoriaMetrics/lib/promscrape/scraper.go:106 reading Prometheus configs from "/etc/victoriametrics/vmagent/config.yml"
2022-08-23T12:42:23.995Z info VictoriaMetrics/lib/promscrape/config.go:117 starting service discovery routines...
2022-08-23T12:42:23.995Z info VictoriaMetrics/lib/promscrape/config.go:123 started service discovery routines in 0.000 seconds
2022-08-23T12:42:23.997Z info VictoriaMetrics/lib/promscrape/scraper.go:403 static_configs: added targets: 2, removed targets: 0; total targets: 2
2022-08-23T12:42:24.699Z info VictoriaMetrics/lib/memory/memory.go:42 limiting caches to 5019416985 bytes, leaving 3346277991 bytes to the OS according to -memory.allowedPercent=60
2022-08-23T12:42:24.701Z info VictoriaMetrics/lib/persistentqueue/fastqueue.go:59 opened fast persistent queue at "vmagent-remotewrite-data/persistent-queue/1_5E2F0F84E74D5D64" with maxInmemoryBlocks=1200, it contains 0 pending bytes
2022-08-23T12:42:24.701Z info VictoriaMetrics/app/vmagent/remotewrite/client.go:169 initialized client for -remoteWrite.url="1:secret-url:2:0"
2022-08-23T12:42:24.724Z info VictoriaMetrics/lib/persistentqueue/fastqueue.go:59 opened fast persistent queue at "vmagent-remotewrite-data/persistent-queue/1_3B7269031AC653CF" with maxInmemoryBlocks=1200, it contains 0 pending bytes
2022-08-23T12:42:24.724Z info VictoriaMetrics/app/vmagent/remotewrite/client.go:169 initialized client for -remoteWrite.url="1:secret-url:1:0"
Важное отличие prometheus можно полностью сконфигурировать через конфиг, а vmagent'у в конфиге можно указать только таргеты которые нужно скрейпить, все остальное у vmagent'a конфигурируется либо через флаги либо через перменные окружения
Файл указанный в -promscrape.config может содержать %{ENV_VAR} плейсхолдеры в которые будут подставлены соответствующие переменные окружения
scrape_config enhancements
vmagent имеет дополнительные опции которые могут быть указаны в секции scrape_configs
-
headers- список http хедеров которые будут добавляться к запросам при скрейпинге. Например туда могут быть подставлены заголовки для аутентификации на экспортереscrape_configs: - job_name: custom_headers headers: - "TenantID: abc" - "My-Auth: TopSecret" -
disable_compression: true- выключает сжатие (по умолчанию запросы от агента сжимаются чтобы экономить трафик) (per job) -
disable_keepalive: true- выключает keep-alive (per-job) -
series_limit: N- ограничивает кол-во таймсерий которые могут соскрейплены с одного таргета -
stream_parse: true- для скрейпинга данных в режиме потока, это полезно когда экспортеры выдают гигантское кол-во метрик и скрейпинг может затягиваться -
scrape_align_interval: duration- не понял как это работает, подробности тут -
scrape_offset: duration- не понял как это работает, подробности тут -
relabel_debug: true- включает дебаг по релейблингу таргетов -
metric_relabel_debug: true- включает дебаг по релейблингу метрик
Loading scrape configs from multiple files
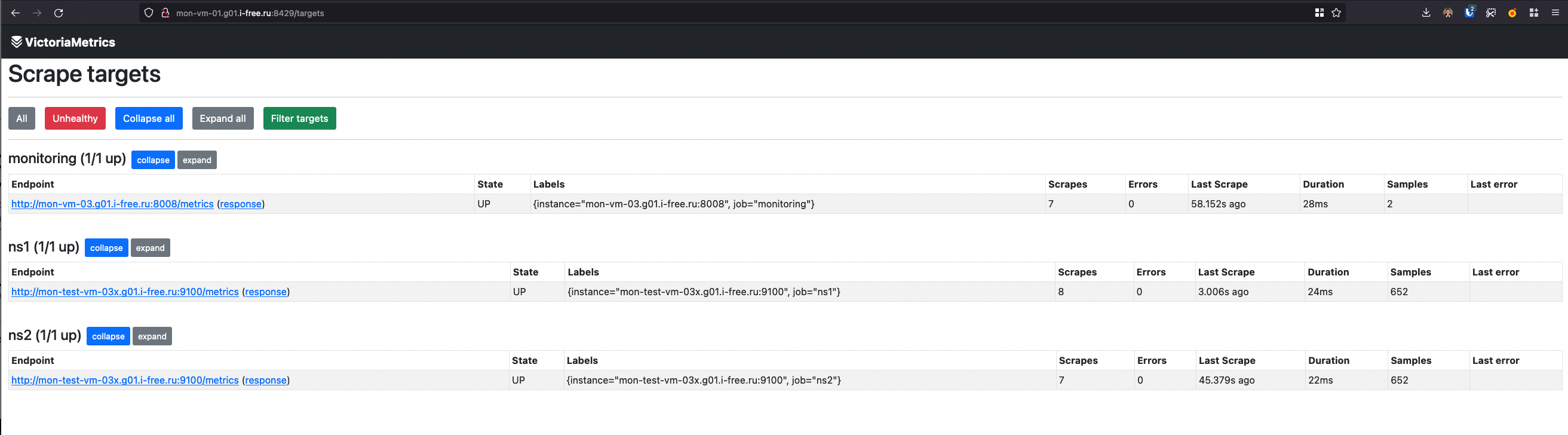
vmagent умеет загружать scrape конфиги из множества файлов указанных в секции scrape_config_files файла указанного в -promscrape.config
root@mon-vm-01:/etc/victoriametrics/vmagent# cat config.yml
scrape_configs:
- job_name: monitoring
static_configs:
- targets:
- mon-vm-03.g01.i-free.ru:8008
labels:
__tenant_id__: 1
scrape_config_files:
- scrape_config_files/test.yaml
root@mon-vm-01:/etc/victoriametrics/vmagent# cat scrape_config_files/test.yaml
- job_name: ns1
static_configs:
- targets:
- mon-test-vm-03x.g01.i-free.ru:9100
- job_name: ns2
static_configs:
- targets:
- mon-test-vm-03x.g01.i-free.ru:9100
Можно задавать файлы разными способами:
scrape_config_files:
- configs/*.yml
- single_scrape_config.yml
- https://config-server/scrape_config.yml # даже так
Каждый файл из этого списка должен содержать валидные скрейп конфиги (static_configs, *_sd_configs, etc)
Эти файлы могут релоадиться без рестарта
Unsupported Prometheus config sections
vmagent не поддерживает следующие секции из -promscrape.config файла (которые поддерживает пром):
-
remote_write- эта секция заменяется разными-remoteWrite*флагами -
remote_read- не работает вообще, запросы для получения данных доступны у хранилища (например VictoriaMetrics) -
rule_filesиalerting- не работает вообще потому что эту функцию выполняетvmalert
Список поддерживаемых SD https://docs.victoriametrics.com/sd_configs.html
Также не поддерживается refresh_interval для service_discovery, эта опция заменяется флагами -promscrape.*CheckInterval
Adding labels to metrics
Дополнительные лейблы к метрикам можно добавить следующим образом:
-
global -> external_labelsв-promscrape.configфайле, лейблы добавятся на все метрики и таргеты собранные через scrape механизм, не добавятся на метрики полученные через push механизм - Флаг
-remoteWrite.labelлейблы будут добавлены на все метрики перед отправкой в-remoteWrite.url
Например флаг--remoteWrite.label=remotewritelabel=true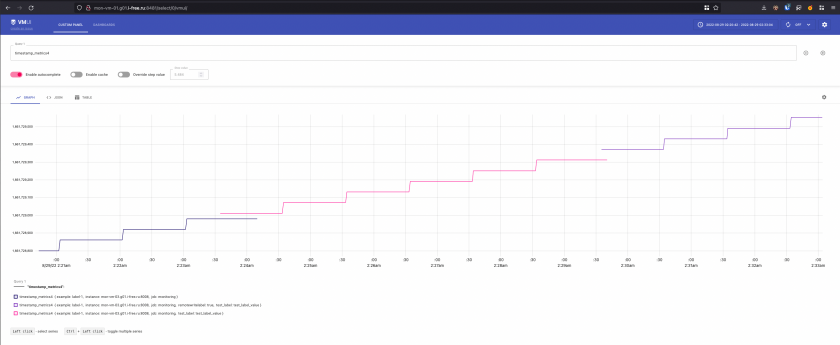
- Третий способ - релейблинг
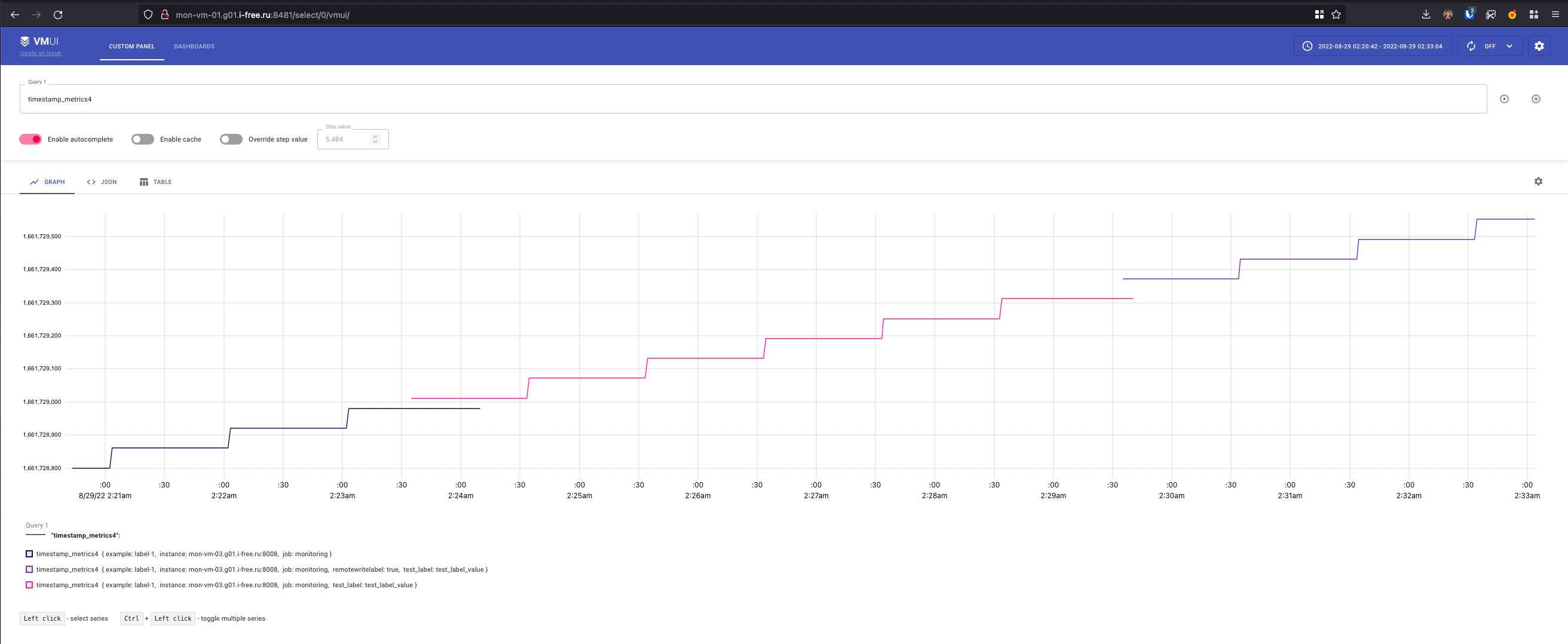
Как я понял
-remoteWrite.labelработает для метрик которые получены агентом через push протоколы и которые он дальше запушит в хранилку. То есть в случае когда агент работает вообще без конфига как гейтвей для пушинга
Automatically generated metrics
vmagent автоматически генерирует следующие метрики для каждого таргета:
-
up- значение1говорит об успешном скрейпе,0об ошибке при скрейпинге (позволяет отслеживать ошибки при скрейпинге) -
scrape_duration_seconds- длительность скрейпа в секундах (позволяет отслеживать медленные скрейпы)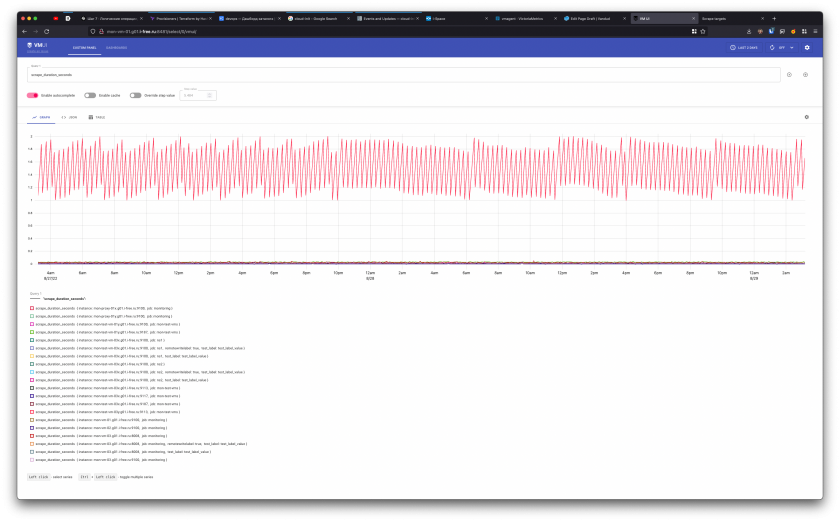
-
scrape_timeout_seconds- значениеscrape_timeoutиз конфига для этого таргета (позволяет отслеживать таргеты чейscrape_duration_secondsприближается к значению изscrape_timeout) -
scrape_samples_scraped- количество сэмплов полученных со скрейпа таргета (позволяет отслеживать таргеты которые выдают слишком много сэмплов) -
scrape_samples_limit- значениеsample_limitиз конфига, метрика экспозится только если лимит задан (позволяет отслеживать таргеты которые экспозят количество метрики приближающееся к лимиту) -
scrape_samples_post_metric_relabeling- количество метрик оставшихся после применения релейблинга (хз зачем) -
scrape_series_added- аппроксимированное количество новых метрик со скрейпа (позволяет отслеживать high churn rate)
Эта метрика будет равна0если установлен флаг-promscrape.noStaleMarkers -
scrape_series_limit- значение изseries_limitдля таргета (метрика будет только если лимит выставлен) -
scrape_series_current- количество метрик которые экспозятся на таргете сейчас (не сэмплы, а именно таймсерии) (позволяет отслеживать приближение к лимиту) -
scrape_series_limit_samples_dropped- количество дропнутых из-за превышения лимита сэмплов
Relabeling
Поддерживается Premetheus-compatible релейблинг и ряд дополнений к нему. Релейблинг может быть определен в следующих местах:
- В секции
scrape_config -> relabel_configsв-promscrape.configфайле. Этот релейблинг используется для изменения лейблов в таргетах и для дроппинга ненужных таргетов. Этот релейблинг можно дебажить опциейrelabel_debug: trueв секцииscrape_config, vmagent будет логировать лейблы до и после релейблинга - В секции
scrape_config -> metric_relabel_configs. Этот релейблинг позволяет модифицировать лейблы метрик и дропать ненужные метрики. Можно дебажить через опциюmetric_relabel_debug: true - В файле
-remoteWrite.relabelConfig. Этот релейблинг позволяет модифицировать лейблы для всех собранных метрик (включая те что получены через push протоколы) и дропать ненужные метрики перед отправкой на-remoteWrite.urlадреса. Можно дебажить флагом-remoteWrite.relabelDebug - В файлах
-remoteWrite.urlRelabelConfig. То же что и выше но для конкретных-remoteWrite.url'ов. Можно дебажить флагом-remoteWrite.urlRelabelDebug
Все файлы с релейблинг конфигами могут содержать плейсхолдеры%{ENV_VAR}, которые будут заменены на соответствующие переменные окружения
https://relabeler.promlabs.com/ поможет отдебажить правила релейблинга
Relabeling enhancements
VictoriaMetrics имеет дополнительные действия для релейблинга поверх стандартных прометеусовских:
-
replace_allreplaces all of the occurrences ofregexin the values ofsource_labelswith thereplacementand stores the results in thetarget_label. For example, the following relabeling config replaces all the occurrences of-char in metric names with_char (e.g.foo-bar-bazmetric name is transformed intofoo_bar_baz):- action: replace_all source_labels: ["__name__"] target_label: "__name__" regex: "-" replacement: "_" -
labelmap_allreplaces all of the occurrences ofregexin all the label names with thereplacement. For example, the following relabeling config replaces all the occurrences of-char in all the label names with_char (e.g.foo-bar-bazlabel name is transformed intofoo_bar_baz):- action: labelmap_all regex: "-" replacement: "_" -
keep_if_equal: keeps the entry if all the label values fromsource_labelsare equal, while dropping all the other entries. For example, the following relabeling config keeps targets if they contain equal values forinstanceandhostlabels, while dropping all the other targets:- action: keep_if_equal source_labels: ["instance", "host"] -
drop_if_equal: drops the entry if all the label values fromsource_labelsare equal, while keeping all the other entries. For example, the following relabeling config drops targets if they contain equal values forinstanceandhostlabels, while keeping all the other targets:- action: drop_if_equal source_labels: ["instance", "host"] -
keep_metrics: keeps all the metrics with names matching the givenregex, while dropping all the other metrics. For example, the following relabeling config keeps metrics withfooandbarnames, while dropping all the other metrics:- action: keep_metrics regex: "foo|bar" -
drop_metrics: drops all the metrics with names matching the givenregex, while keeping all the other metrics. For example, the following relabeling config drops metrics withfooandbarnames, while leaving all the other metrics:- action: drop_metrics regex: "foo|bar"graphite: applies Graphite-style relabeling to metric name. See these docs for details.
The regex value can be split into multiple lines for improved readability and maintainability. These lines are automatically joined with | char when parsed. For example, the following configs are equivalent:
- action: keep_metrics
regex: "metric_a|metric_b|foo_.+"
- action: keep_metrics
regex:
- "metric_a"
- "metric_b"
- "foo_.+"
VictoriaMetrics components support an optional if filter in relabeling configs, which can be used for conditional relabeling. The if filter may contain arbitrary time series selector. For example, the following relabeling rule drops metrics, which don't match foo{bar="baz"} series selector, while leaving the rest of metrics:
- action: keep
if: 'foo{bar="baz"}'
This is equivalent to less clear Prometheus-compatible relabeling rule:
- action: keep
source_labels: [__name__, bar]
regex: 'foo;baz'
Graphite relabeling
Не интересно
Prometheus staleness markers
Про staleness маркеры - https://www.robustperception.io/staleness-and-promql/ (я не особо понял)
vmagent засылает staleness маркеры в -remoteWrite.url в следующих случаях:
- Если они получены vmagent'ом через remote_write протокол
- Если метрика пропала из списка соскрейпленных метрик, тогда stale маркер выставляется на конкретную метрику
- Если таргет стал недоступен, тогда маркер выставляет на все метрики этого таргета
- Если таргет пропал из списка таргетов, тогда маркеры выставляет на все метрики этого таргета
Для работы маркеров требуется дополнительная память, потому что нужно хранить предыдущий response body для каждого таргета, чтобы сравнивать его с текущим response body. Потребление памяти можно уменить выключив этот функционал флагом -promscrape.noStaleMarkers (он выключает staleness tracking), также этот флаг выключает сервисную метрику scrape_series_added
Stream parsing mode
По умолчанию vmagent сперва записывает весь response body в память, потом парсит его, потом применяет релейблинг и пушит в в -remoteWrite.url. Этот режим работает хорошо в большинстве случаев когда таргет экспозит небольшое количество метрик (меньше 10к). Но этот режим может требовать много памяти когда таргеты экспозят огромное количество метрик. В таких случаях рекомендуется включать stream parsing mode. Когда включен этот режим, vmagent читает response body чанками, немедленно процессит каждый чанк и пушит полученные метрики в remote storage. Это позволяет сохранить потребление памяти когда таргеты экспозят миллионы метрик
Stream parsing mode включается автоматически для таргетов, размер ответа которых превышает значение флага -promscrape.minResponseSizeForStreamParse
Этот режим может быть включен явно в следующих местах:
- Через флаг
-promscrape.streamParse. В этом случае все таргеты из-promscrape.configбудут обрабатываться в этом режиме - Через опцию
stream_parse: trueв секцииscrape_configs. Тогда таргеты описанные в этой секции будут обрабатываться в этом режиме - Через лейбл
__stream_parse__=true, который может быть установлен через релейблинг в секцииrelabel_configs. Тогда режим будет использоваться для конкретных таргетов
Опции
sample_limitиseries_limitне могут быть использованы одновременно с stream parsing mode потому что пропаршенные данные пушатся в сторадж сразу
Scraping big number of targets
Один vmagent может скрейпить десятки тысяч таргетов. Иногда этого может быть недостаточно из-за разных ограничений по ресурсам. В таком случае таргеты можно пошарить между несколькими инстансами vmagent'a (горизонтальное масштабирование). Все vmagent'ы в кластере должны иметь идентичные -promscrape.config с ясным значением флага -promscrape.cluster.memberNum. Значение этого флага должно быть в диапазоне от 0 до N-1, где N это количество vmagent'ов в кластере. Количество vmagent'ов нужно указать в флаге -promscrape.cluster.memberCount
Например следующие две команды поднимут кластер vmagent'ов из двух инстансов и нагрузка будет разделена между ними:
/path/to/vmagent -promscrape.cluster.membersCount=2 -promscrape.cluster.memberNum=0 -promscrape.config=/path/to/config.yml ...
/path/to/vmagent -promscrape.cluster.membersCount=2 -promscrape.cluster.memberNum=1 -promscrape.config=/path/to/config.yml ...
По умолчанию каждый таргет скрейпится только одним vmagent'ом из кластера. Если нужна репликация таргетов между агентами, то нужно проставить флаг -promscrape.cluster.replicationFactor с значением желаемого количества реплик
Например следующие три команды поднимут кластер vmagent'ов из трех нод с фактором репликации - 2. То есть каждый таргет будет скрейпиться какими-то двумя vmagent'ами:
/path/to/vmagent -promscrape.cluster.membersCount=3 -promscrape.cluster.replicationFactor=2 -promscrape.cluster.memberNum=0 -promscrape.config=/path/to/config.yml ...
/path/to/vmagent -promscrape.cluster.membersCount=3 -promscrape.cluster.replicationFactor=2 -promscrape.cluster.memberNum=1 -promscrape.config=/path/to/config.yml ...
/path/to/vmagent -promscrape.cluster.membersCount=3 -promscrape.cluster.replicationFactor=2 -promscrape.cluster.memberNum=2 -promscrape.config=/path/to/config.yml ...
В случае с репликацией нужно включать data deduplication на сторадже указанном в -remoteWrite.url. Флаг -dedup.minScrapeInterval должен быть выставлен в scrape_interval указанный в -promscrape.config
High availability
Для этого можно запустить несколько агентов которые будут скрейпить одинаковые таргеты и пушить в один и тот же сторадж, но нужно чтобы была настроена дедупликация на сторадже
Также рекомендуется указывать разные значения в флагах -promscrape.cluster.name на агентах для более качественной дедупликации
High Availability достигается фактором репликации. То есть каждый таргет опрашивается более чем одним агентом и при потере любого одного агента из кластера, как минимум один продолжает скрейпить таргет
Scraping targets via a proxy
https://docs.victoriametrics.com/vmagent.html#scraping-targets-via-a-proxy
vmagent может скрейпить таргеты сквозь прокси (http, https, socks5). Адрес прокси задается опцией proxy_url в секции scrape_configs:
scrape_configs:
- job_name: foo
proxy_url: https://proxy-addr:1234
Работу через прокси можно законфигурировать следующими опциями:
Cardinality limiter
По умолчанию vmagent не ограничивает количество таймсерий которые могут быть потреблены с каждого таргета. Это ограничение может быть задано в следующих местах:
- Через флаг
-promscrape.seriesLimitPerTarget. Этот лимит будет применяться к каждому таргету из-promscrape.config - Через опцию
series_limitв секцииscrape_config. Этот лимит будет применяться ко всем таргетам из этогоscrape_config - Через лейбл
__series_limit__на таргете который может быть выставлен на конкретный таргет в секцииrelabel_configs
Так же может быть полезной опция sample_limit в секции scrape_config
Метрики сверх лимита будут дропаться
vmagent создает дополнительные сервисные метрики для каждого таргета у которого не нулевой лимит:
-
scrape_series_limit_samples_dropped- количество дропных из-за превышения лимита метрик -
scrape_series_limit- лимит на этот таргет -
scrape_series_current- текущее количество таймсерий для этого таргета
Эти сервисные метрики засылаются в -remoteWrite.url вместе с обычными метриками
Эти метрики позволяют настроить следующие алертинги:
-
scrape_series_current / scrape_series_limit > 0.9- алерт когда количество предоставляемых экспортером метрик приближается к лимиту -
sum_over_time(scrape_series_limit_samples_dropped[1h]) > 0- алерт когда превышен series limit и некоторые метрики начинают дропаться
По умолчанию vmagent не ограничивает количество таймсерий которые отправляются в хранилище указанное в -remoteWrite.url. Этот лимит может быть проставлен следующими флагами:
-
-remoteWrite.maxHourlySeries- лимит на количество уникальных таймсерий которые vmagent может записать в remote storage в течение часа. Полезно для ограничения количества активных таймсерий -
-remoteWrite.maxDailySeries- лимит на количество уникальных таймсерий которые vmagent может записать в remote storage в течение дня. Полезно для ограничения дневного churn rate
Оба лимита могут быть выставлены одновременно. Если любой из этих лимитов достигнут, тогда сэмплы для новых таймсерий будут дропаться и в лог будут писаться сообщения с уровнем WARNING
vmagent экспозит следующие метрики на http://vmagent:8429/metrics:
- vmagent_hourly_series_limit_rows_dropped_total` - количество дропнутых после достижения часового лимита метрик
- vmagent_hourly_series_limit_max_series
- значение из-remoteWrite.maxHourlySeries` - vmagent_hourly_series_limit_current_series` - количество уникальных метрик за последний час
- vmagent_daily_series_limit_rows_dropped_total` - количество дропнутых после достижения дневного лимита метрик
- vmagent_daily_series_limit_max_series
- значение из-remoteWrite.maxDailySeries` - vmagent_daily_series_limit_current_series` - количество уникальных метрик за последнй день
Эти лимиты примерны, обычно расходятся меньше чем на один процент
Monitoring
vmagent экспортирует разные метрики на эндпоинте http://vmagent-host:8429/metrics
Рекомендуется их регулярно скрейпить потому что их анализ в будущем может принести пользу
Есть официальный дашборд для графаны https://grafana.com/grafana/dashboards/12683-vmagent/
vmagent также экспортирует статус для разных таргетов на следующих хэндлерах:
-
http://vmagent-host:8429/targets- человеко-читаемый статус по каждому таргету. Этот урл можно курлануть (то есть один и тот же урл красиво выглядит и в браузере и в терминале)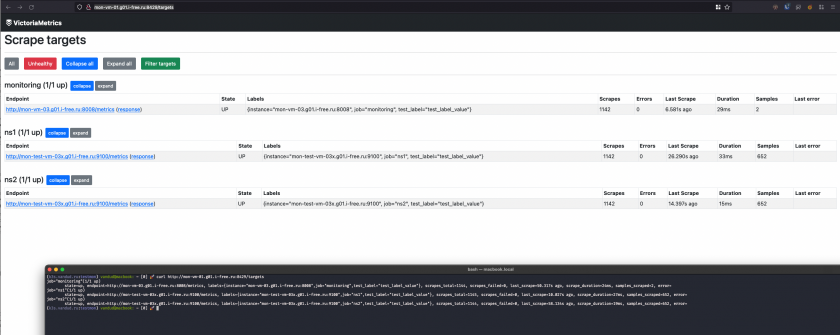
Можно добавить к запросу аргументshow_original_labels=1и будут показаны оригинальные лейблы до применения релейблинга (это полезно при дебаге релейблинга)
-
http://vmagent-host:8429/api/v1/targets- хэндлер аналогичный прометеусовскому? curl -s http://mon-vm-01.g01.i-free.ru:8429/api/v1/targets | jq 'del(.data.activeTargets[0,1])' { "status": "success", "data": { "activeTargets": [ { "discoveredLabels": { "__address__": "mon-vm-03.g01.i-free.ru:8008", "__metrics_path__": "/metrics", "__scheme__": "http", "__scrape_interval__": "1m0s", "__scrape_timeout__": "10s", "__tenant_id__": "1", "job": "monitoring", "test_label": "test_label_value" }, "labels": { "instance": "mon-vm-03.g01.i-free.ru:8008", "job": "monitoring", "test_label": "test_label_value" }, "scrapePool": "monitoring", "scrapeUrl": "http://mon-vm-03.g01.i-free.ru:8008/metrics", "lastError": "", "lastScrape": "2022-08-29T21:41:33.779+03:00", "lastScrapeDuration": 0.025, "lastSamplesScraped": 2, "health": "up" } ], "droppedTargets": [] } } -
http://vmagent-host:8429/ready- отдает код 200 с текстомOKкогда vmagent завершил инициализацию для всех SD конфигов. Это может быть полезным для налаживания rolling update без потерь скрейпов

Troubleshooting
- Рекомендуется использовать официальный дашборд для vmagent'a https://grafana.com/grafana/dashboards/12683-vmagent/
- Рекомендуется увеличить ограничение на открытые файлы в системе
ulimit -nпри скрейпинге большого количетсва таргетов, потому что при скрейпинге устанавливается одно tcp соединение на один таргет - Если vmagent потребляет много памяти, то следующие опции могут помочь:
- Выключение staleness tracking'a через флаг
-promscrape.noStaleMarkers - Включение stream parsing mode (если скрейпится гигантское кол-во метрик)
- Уменьшение кол-ва выходных очередей через флаг
-remoteWrite.queues - Уменьшение кол-ва памяти которую может потребить vmagent для in-memory буфферизации через флаги
-memory.allowedPercentили-memory.allowedBytes - Уменьшение кол-ва ядер которые может занять vmagent через переменную окружения
GOMAXPROCS=N, гдеNэто желаемый лимит на ядра - Можно выставить флаг
-promscrape.dropOriginalLabels(подробнее тут)
- Выключение staleness tracking'a через флаг
- Когда vmagent скрейпит много нерабочих таргетов, то о каждой неудаче он сообщает в лог. Эти ошибки можно выключить флагом
-promscrape.suppressScrapeErrors - Урл
/api/v1/targetsполезен для дебагинга процесса релейблинга. Эта страница содержит оригинальные лейблы для таргетов которые дропаются правилами релейблинга (секцияdroppedTargets). По умолчанию в этой секции будет отображено столько таргетов, сколько указано в флаге-promscrape.maxDroppedTargets, если твой сетап дропает больше таргетов, то чтобы увидеть все увеличь значение этого флага. Трэкинг дропаемых таргетов требует дополнительной памяти, поэтому если их у тебя слишком много то это может заметно отразиться на потреблении памяти - Рекомендуется увеличивать значение флага
-remoteWrite.queuesесли значение метрикиvmagent_remotewrite_pending_data_bytesрастет. Также в таком случае рекомендуется увечивать значения флагов-remoteWrite.maxBlockSizeи-remoteWrite.maxRowsPerBlock. Это улучшит производительность поглощения данных ценой потребления памяти - Если ты видишь гэпы в данных которые пушатся агентом в хранилку при установленном флаге
-remoteWrite.maxDiskUsagePerURL, попробуй увеличить количество очередей в-remoteWrite.queues. Такие гэпы могут происходить потому что vmagent не успевает отправлять данные в хранилище и дропает данные из кэша если достигает ограничения из-remoteWrite.maxDiskUsagePerURL - vmagent дропает блоки данных если сторадж отдает
400 Bad Requestили409 Conflict. Количество дропнутых блоков можно отслеживать по метрикеvmagent_remotewrite_packets_dropped_total - Используй
-remoteWrite.queues=1если используется хранилище не поддерживающее out-of-order samples (data backfilling) - vmagent буфферизирует собранные данные в
-remoteWrite.tmpDataPathдо отправки их в-remoteWrite.url. Эта директория может вырастать до больших размеров в ситуациях когда сторадж не доступен долгое время и если флаг-remoteWrite.maxDiskUsagePerURLне задан. В таких случаях если тебе не важны эти данные то можно остановить агента, удалить данные и запустить заново - По умолчанию vmagent маскриует
-remoteWrite.urlподsecret-urlв логах и на странице с метриками агента/metrics(этот урл фигурирует в некоторых метриках) потому что этот урл может содержать чувствительные данные (токены, пароли). Флаг-remoteWrite.showURLпозволяет отключить это сокрытие для улучшение дебагобилити# проверяет без флага root@mon-vm-01:~# curl -s http://mon-vm-01.g01.i-free.ru:8429/metrics | grep vmagent_remotewrite_requests_total vmagent_remotewrite_requests_total{url="1:secret-url", status_code="2XX"} 299 root@mon-vm-01:~# vim /etc/systemd/system/vmagent.service; systemctl daemon-reload; systemctl restart vmagent # проверяем после добавления флага root@mon-vm-01:~# curl -s http://mon-vm-01.g01.i-free.ru:8429/metrics | grep vmagent_remotewrite_requests_total vmagent_remotewrite_requests_total{url="1:http://mon-vm-01.g01.i-free.ru:8480/insert/0/prometheus", status_code="2XX"} 0 - By default vmagent evenly spreads scrape load in time. If a particular scrape target must be scraped at the beginning of some interval, then scrape_align_interval option must be used. For example, the following config aligns hourly scrapes to the beginning of hour
scrape_configs: - job_name: foo scrape_interval: 1h scrape_align_interval: 1h - By default vmagent evenly spreads scrape load in time. If a particular scrape target must be scraped at specific offset, then scrape_offset option must be used. For example, the following config instructs vmagent to scrape the target at 10 seconds of every minute
scrape_configs: - job_name: foo scrape_interval: 1m scrape_offset: 10s
Kafka integration
Пока не интересно
Подробности тут
How to build from sources
Пока не интересно
Подробности тут
Profiling
vmagent предоставляет хэндлеры для сбора Go профилей:
- Memory profile -
curl http://vmagent:8429/debug/pprof/heap > mem.pprof - CPU profile -
curl http://vmagent:8429/debug/pprof/profile > cpu.pprof
Команда для сбора CPU профиля сперва ждет 30 секунд и только потом возращает результат
Собранные профили можно проанализировать утилитой https://github.com/google/pprof
Файлы профилей не содержат сенсетивной информации поэтому их можно без страха шарить кому-то
Advanced usage
vmagent имеет еще массу различных флагов, актуальную справку по которым можно увидеть запустив vmagent -help
No Comments