Configuration/Alerting rules
Правила алертинга позволяют определять состояния используя prometheus expression language и слать алерты во внешние сервисы
Когда выражение возвращает один или несколько элементов на протяжении указанного периода, алерт считается активным для набора лейблов
Defining alerting rules
Правила алертинга конфигурируются так же как и правила записи
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency
-
for- опциональный параметр. Указывает prometheus'у проверять на протяжении указанного периода, то что выражение активно, и только после этого слать алерт. Уже активные, но еще не сработавшие алерты находятся в состоянии ожидания -
labels- тут можно определить набор лейблов для алерта -
annotations- тут можно определить набор информационных лейблов, например описание проблемы или полезные ссылки
Templating
Лейблы и аннотации могут быть затемплейчены через console templates
Переменная $labels содержит пары key/value алерт инстанса
Внешние лейблы могут вызываться через $externalLabels
Переменная $value содержит значение
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
Inspecting alerts during runtime
После того как у нас сработал алерт, мы можем получить time series по этому алерту, в метрике хранится состояние проверки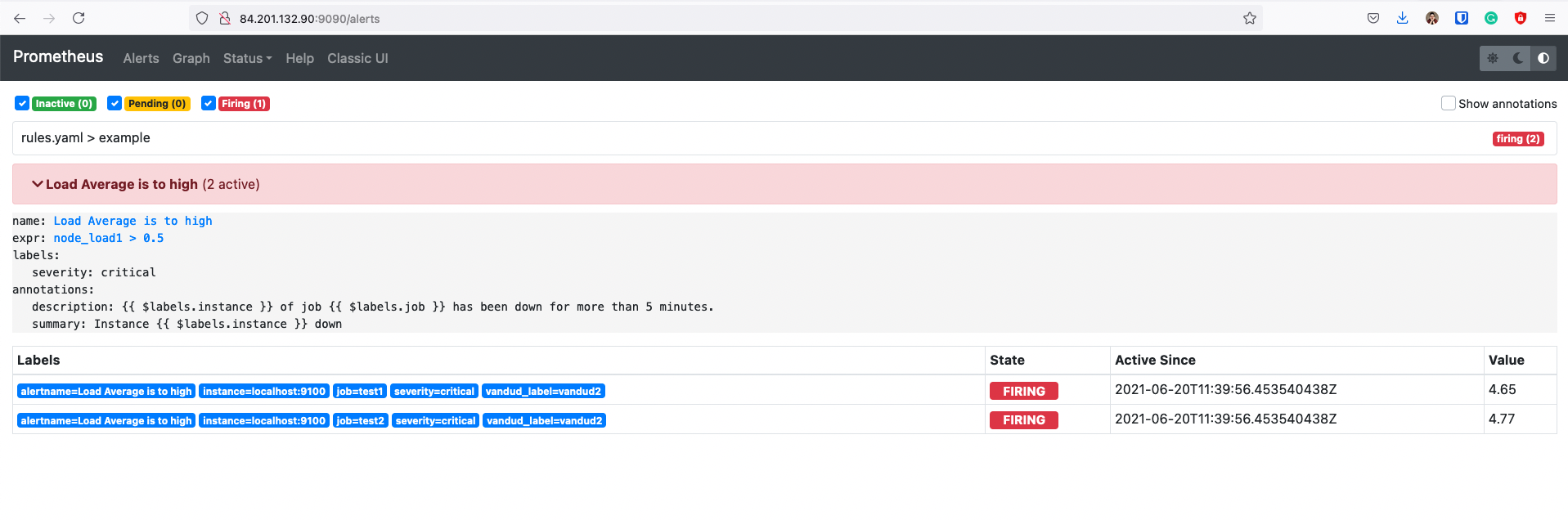

Time Series ALERTS хранит только активные и ожидающие алерты
На скрине видно что данные перестали писаться в этот временной ряд после того как алерт перешел в ОК
Единица туда пишется просто так, чтобы писать хоть что-то, смысловой нагрузки единица не несет
Sending alert notifications
Страница с алертами это хороший способ узнать что сломано прямо сейчас
Но это не полноценное решение для нотификаций
Следующим уровнем нужно добавить суммирование, ограничение скорости уведомлений, приглушение и зависимости алертов
В экосистеме prometheus эту роль занимает alertmanager
Прометеус шлет в алертменеджер все подряд, а алертменеджер отсылает только то что нужно (с учетом зависимостей и прочего)
Прометеус может быть настроен на автодискаверинг доступных алертменеджеров
No Comments