Storage
Прометеус включает в себя локальную TSDB на диске
Но также может интегрироваться с remote стораджами
Local storage
TSDB хранит данные в кастомном высокоэффективном формате на локальном диске
Группирует блоки данных по два часа
Каждый двухчасовой блок состоит из директории которая хранит:
- Поддиректория с чанками данных для этого промежутка времени
- Файл с метаданными
- Индексный файл (который индексирует имена метрик и лейблы в таймсерии из поддериктории chunks)
Сэмплы в папке chunks сгруппированы в один или более файл размером до 512М каждый
Когда таймсерии удаляются через API, команда удаления записывается в tombstone файл (вместо немедленного удаления данных /querying/api/#delete-series) до следующего сжатия (compaction)
Текущий двухчасовой блок данных хранится в памяти и не является полностью постоянным. WAL (write ahead log) защитит от потери данных из памяти (при рестарте), этот лог может быть проигран (replayed) для восстановления данных
WAL файлы хранятся в папке wal сегментами по 128M. В них хранятся сырые данные, которые не могут быть сжаты и их размер значительно больше обычных блоков данных
Хранится не менее трех wal-файлов, высоконагруженные серверы могут иметь больше трех чтобы уместить двухчасовой период
./data
├── 01BKGV7JBM69T2G1BGBGM6KB12
│ └── meta.json
├── 01BKGTZQ1SYQJTR4PB43C8PD98
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── 01BKGTZQ1HHWHV8FBJXW1Y3W0K
│ └── meta.json
├── 01BKGV7JC0RY8A6MACW02A2PJD
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── chunks_head
│ └── 000001
└── wal
├── 000000002
└── checkpoint.00000001
└── 00000000
Прометеус не кластеризуется и не реплицируется, поэтому с ним нужно обходиться как с single node database
Рекомендуется использовать raid и snapshots
При правильной архитектуре данные можно хранить годами
Как альтернатива может быть использован какой-либо external storage через remote read/write API
Compaction
Двухчасовые блоки компануются в фоне в долгие блоки данных
У Прометеуса есть несколько флагов для конфигурирования локального хранилища
Вот наиважнейшие из них:
-
--storage.tsdb.path- Путь куда будет записываться база данных. По умолчаниюdata/ -
--storage.tsdb.retention.time- Когда удалять старые данные. Defaults to 15d -
--storage.tsdb.retention.size- [EXPERIMENTAL] Размер удерживаемых данных. Сначала удаляются более старые данные. Defaults to 0 or disabled. Units supported: B, KB, MB, GB, TB, PB, EB. Ex: "512MB" -
--storage.tsdb.retention- Deprecated in favor ofstorage.tsdb.retention.time -
--storage.tsdb.wal-compression- Включает сжатие wal. В зависимости от твоих данных может уменьшить вдвое размер данных с низкой нагрузкой на процессор. Включено по умолчанию начиная с 2.20.0 версии (это нужно учитывать если захочется задаунгрейдить пром до версии без этой функции (более старый чем 2.11.0 не сможет понять wal-файл, и wal придется удалить))
Prometheus хранит 1-2 байта на сэмпл. Поэтому для расчета того сколько дискового пространства потребуется для сервера, нужно воспользоваться этой формулой:
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample
Чтобы снизить размер поглощаемых данных можно снизить количество таймсерий (убавить целей или убавить таймсерий на цель), или можно увеличить scrape interval
Если локальный сторадж повредился по каким-то причинам, то лучшая стратегия это выключить prometheus и удалить storage directory, также можно попробовать удалить только какой-то конкретный блок данных или wal
Этот метод имеет место быть потому что Прометей не годится для длительного хранения данных, внешние решения сделают это лучше и надежнее
Если одновременно указаны и time и size retention, то будет использован тот кто сработает первее
Блоки удаляются целиком за раз после того как их срок действия полностью истек (поэтому это может занять до двух часов)
Remote storage integrations
Локальный сторадж имеет ограничения, поэтому вместо того чтобы решать проблемы кластеризации, прометеус предоставляет интерфейс для интеграции с remote storages
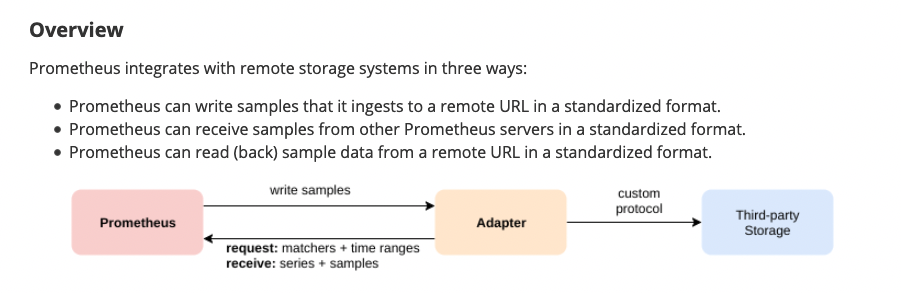
Чтобы включить приемник (receiver) нужно указать флаг --enable-feature=remote-write-receiver, тогда дефолтный эндпоинт для remote write будет /api/v1/write
Note that on the read path, Prometheus only fetches raw series data for a set of label selectors and time ranges from the remote end. All PromQL evaluation on the raw data still happens in Prometheus itself. This means that remote read queries have some scalability limit, since all necessary data needs to be loaded into the querying Prometheus server first and then processed there. However, supporting fully distributed evaluation of PromQL was deemed infeasible for the time being.
Backfilling for Recording Rules
Когда создается новое recording rules, для него еще нет исторических данных, они появляются со временем
Утилита promtool позволяет сгенерировать исторические данные для правила
$ promtool tsdb create-blocks-from rules --help
Добавил правило
$ cat rule
groups:
- name: example
rules:
- record: job:load_average_1:rate
expr: rate(node_load1[60m])
Данных пока нет

$ sudo !!
sudo promtool tsdb create-blocks-from rules --start 1624547613 --end 1624554804 --url http://84.201.175.11:9090 --output-dir=/var/lib/prometheus/metrics2 /etc/prometheus/rule
level=info backfiller="new rule importer from start" 24Jun2115:13UTC=" to end" 24Jun2117:13UTC=(MISSING)
level=info backfiller="processing group" name=/etc/prometheus/rule;example
level=info backfiller="processing rule" id=0 name=job:load_average_1:rate
И данные появились
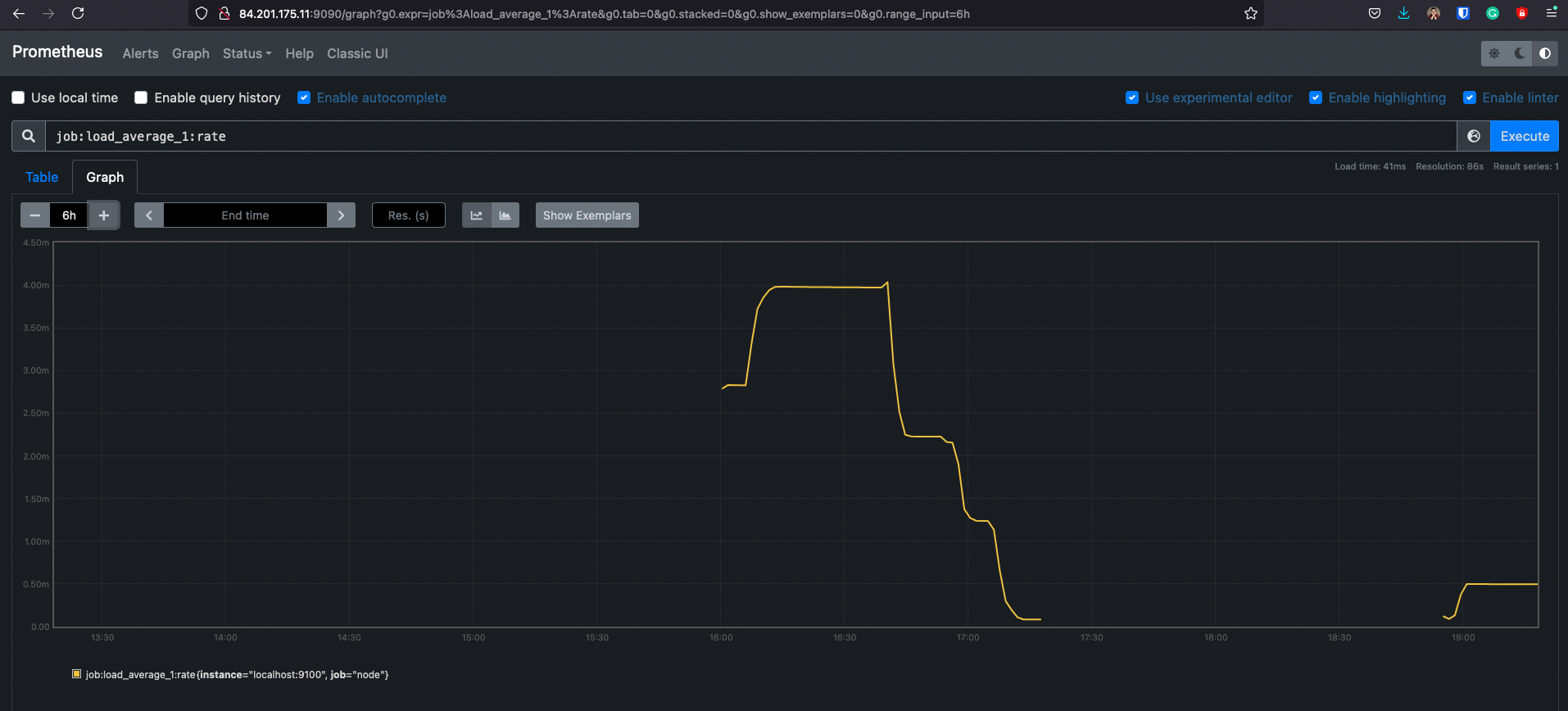
Но с этим нужно быть аккуратным
https://prometheus.io/docs/prometheus/latest/storage/#usage-0
No Comments