Getting started
# Start Prometheus.
# By default, Prometheus stores its database in ./data (flag --storage.tsdb.path).
./prometheus --config.file=prometheus.yml
Добавляем в конфиг
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'vandud'
static_configs:
- targets: ['two.vandud.ru:80']
Рестартуем
И действительно появилось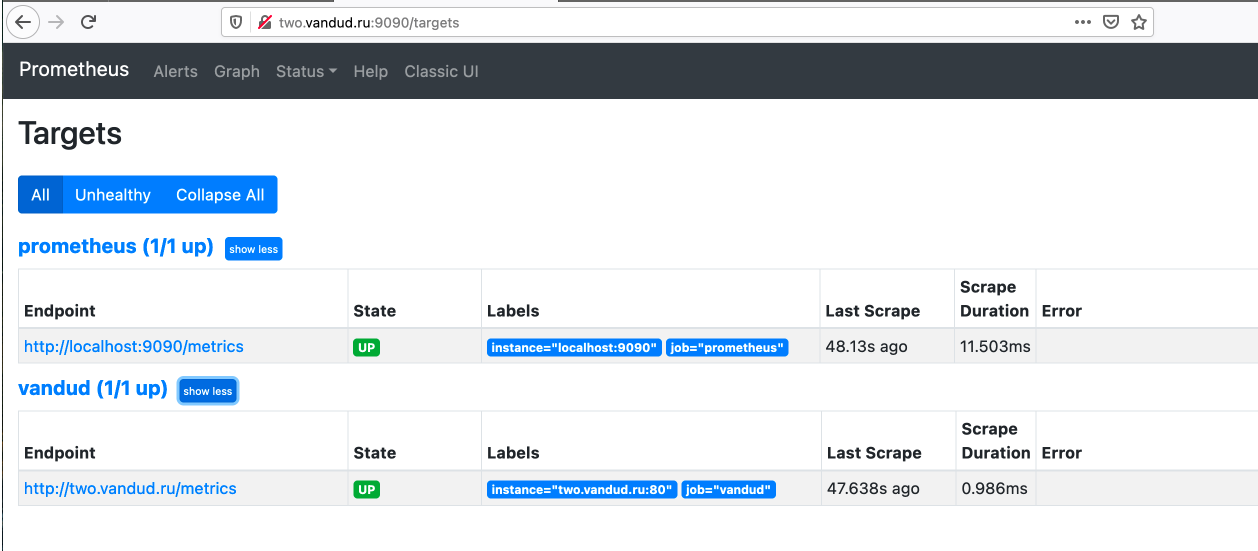
Пока у нас не много метрик, нет проблемы в вычислении функций для них
Но когда их становится много, то вычисление начнет занимать значительное время
В таких случаях можно настроить особые правила по которым prometheus будет аггрегировать данные в новые time series
Эти правила можно описать в отдельном файле
groups:
- name: cpu-node
rules:
- record: job_instance_mode:node_cpu_seconds:avg_rate5m
expr: avg by (job, instance, mode) (rate(node_cpu_seconds_total[5m]))
И подключать в основной конфиг так
rule_files:
- 'prometheus.rules.yml'
No Comments